
В связи с растущим публичным интересом к анализу и визуализации различных пространственных моделей (например, для изучения распространения вирусов) мне вспомнился один из проектов, которыми я занимался на фриланс-платформе Upwork. Эта работа выполнена по заказу корпорации Google и заключалась в создании общедоступного датасета OpenStreetMap (OSM) на Google Cloud Platform для работы с ним с помощью Google BigQuery и создании некоторых примеров анализа данных OpenStreetMap (смотрите Python Jupyter Notebooks в репозитории). Моей частью проекта была работа с данными; кто сразу хочет посмотреть код — добро пожаловать в мой гит-репозиторий bigquery-openstreetmap. Далее я расскажу, в чем заключаются преимущества созданного датасета (хинт: реализован и доступен классификатор слоев на SQL) и как его можно использовать.
Обращение к читателям: убедительная просьба избежать обсуждения Upwork в частности и фриланса в целом в комментариях, ну надоело же, право слово… разные там проекты есть.
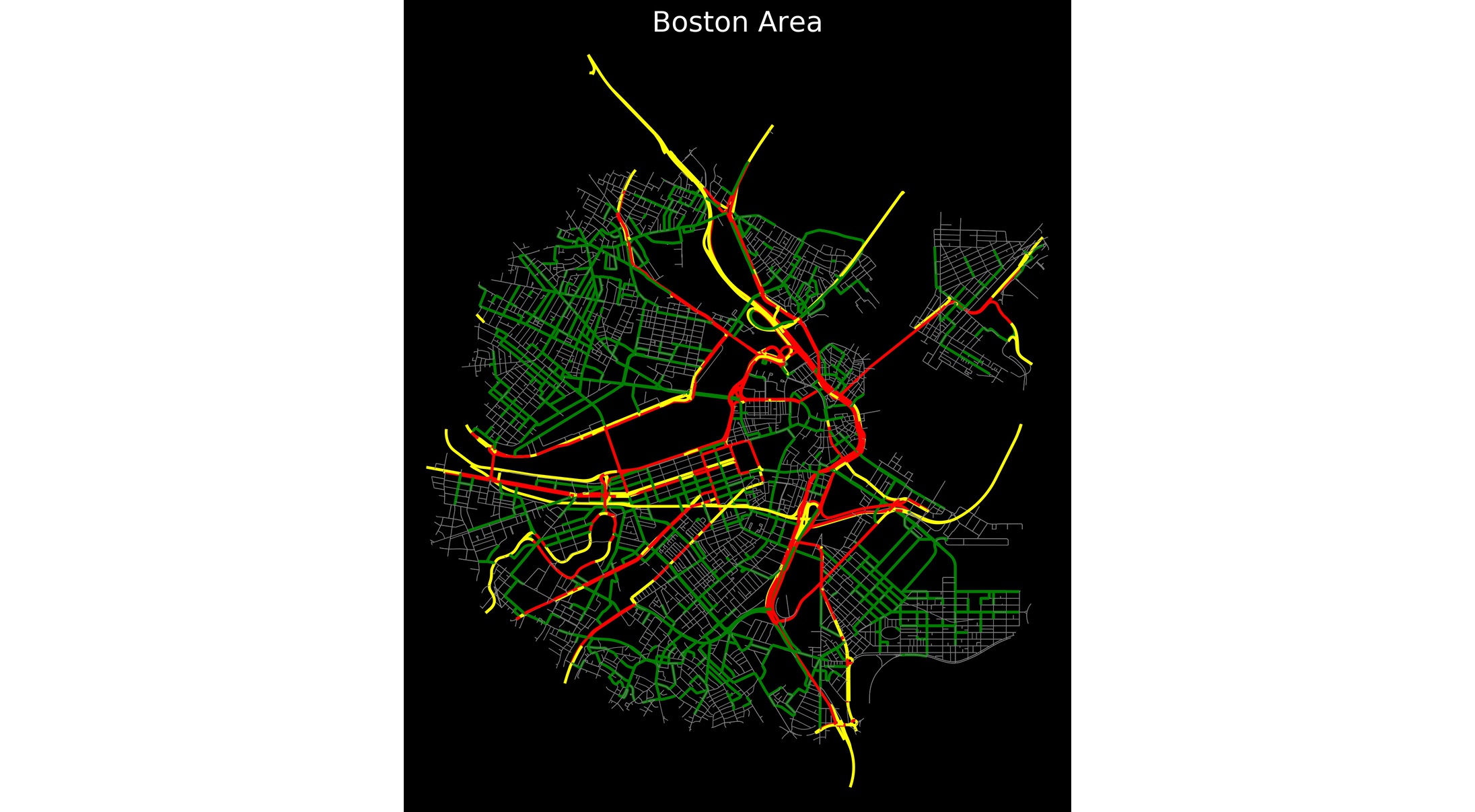
Результаты анализа дорожной сети города Бостона по данным OpenStreetMap. Красным цветом обозначены хайвеи с высоким Betweenness centrality (bc), зеленым — улицы с высоким bc, желтым — хайвей с низким bc, серым — улицы с низким bc.
Вместо введения
Если будет время и интерес к теме работы с OSM, я мог бы рассказать про построение сложного роутинга средствами PostgreSQL/PostGIS/PgRouting — как обеспечить поддержку однонаправленных дорог для задачи коммивояжера (Travelling salesman problem, TSP), избавиться от лишних пересечений дорог, комбинировать доставку на транспортном средстве с пешеходной (не к каждому дому можно подъехать) и так далее — то есть построить коммерческую систему роутинга на открытых картографических данных OSM. Или о проекте анализа в реальном времени дорожного трафика Германии (на самом деле, анализируются данные сразу для нескольких европейских стран, но Германия среди них наибольшая по территории и дорожной сети) — порядка миллиона автомобилей посылают данные раз в 5-10 секунд (у водителей установлено специальное мобильное приложение), эти данные используются для подсчета количества и средней скорости автомобилей на сегментах дорог (средняя длина сегмента 100м) и получения оценки загруженности дорог, выделения участков дорог из сегментов с аномально низкой скоростью их прохождения ("пробок") и прочее. Для меня последний названный проект интересен еще и тем, что для хранения и отображения терабайтов данных трафика всем пользователям системы используется база данных SQLite3 с расширением Spatialite (аналог PostgreSQL/PostGIS/PgRouting) в связке с PostgreSQL/PostGIS для предобработки поступающих данных.
Работа с данными проекта OpenStreetMap
Обратимся к википедии за определением OpenStreetMap:
OpenStreetMap (дословно «открытая карта улиц»), сокращённо OSM — некоммерческий веб-картографический проект по созданию силами сообщества участников — пользователей Интернета подробной свободной и бесплатной географической карты мира.
Как уже понятно, OSM данные весьма разнородные по своей сути, и качество данных и их детальность и доступные атрибуты очень варьируются для разных территорий. При этом, качество данных достаточно высокое для развитых стран, при этом возможно внести свои правки при обнаружении неточностей — все это делает OSM отличным кандидатом для создания различных картографических сервисов. Более того, используя Google Maps API/Bing Maps API можно провести оценку аккуратности карты и, при необходимости, внести необходимые изменения автоматически или вручную (с точки зрения лицензий коммерческих сервисов мы вправе выполнить сравнение с ними, а вот сами изменения можно внести на основе космоснимков, кадастровых планов и других источников). К примеру, выбираем некоторое количество адресов на карте OSM и с помощью геокодирования определяем их координаты на коммерческих картах для сравнения. Может быть, это покажется удивительным каждому, кто не знаком с миром картографии, но идеальных карт не существует и существовать не может (в том числе, потому, что и города и строения появляются новые, перестраиваются, разрушаются...), и все коммерческие карты тоже содержат немало ошибок, для каких-то территорий OSM оказывается лучше коммерческих карт, для каких-то хуже, зато позволяет внести нужные исправления. И, конечно, прежде чем начать использование данных, смотрите лицензию проекта OpenStreetMap License.
OpenStreetMap это именно проект сбора данных, так что в нем организация сбора данных приоритетнее, нежели структура этих данных. Фактически, данные OSM даже не являются пространственными данными (с заданными геометриями) — вместо этого у них просто определены разнообразные свойства, включая координаты или наборы координат (притом это могут быть координаты или внешнего контура или внутреннего контура или то и другое вместе или вовсе никаких координат: все это указывается дополнительными атрибутами или не указывается вовсе). Существует множество разных схем данных OSM для разных применений ("OSM uses different database schemas for different applications"). В частности, в схеме для веб-редактирования (так называемая web database schema) геометрии не определены (хотя, разумеется, есть атрибуты с координатами). Так называемая "простая" схема данных содержит "только" 10 таблиц и поддерживает репликацию, но не хранит полную историю изменений (Simple schema for Osmosis) — и также не содержит геометрий объектов (есть только наборы координат). Смотрите подробнее в вики проекта: Database Schemas Здесь же можно найти таблицу с рекомендуемыми для различных вариантов использования схемами данных и утилитами для преобразования в них, нас интересуют только схемы для анализа данных:
| Schema name | Created with | Updatable | Geometries (PostGIS) | Lossless | hstore columns | Database |
|---|---|---|---|---|---|---|
| pgsnapshot | osmosis | yes | optional | yes | yes | PostgreSQL |
| ogr2ogr | ogr2ogr | no | yes | no | optional | various |
| overpass | Overpass API | yes | ? | yes | ? | custom |
| mongosm | MongOSM | maybe | ? | ? | ? | MongoDB |
| node-mongosm | Mongoosejs | yes | yes | yes | NA | MongoDB |
| goosm | goosm | no | yes | yes | NA | MongoDB |
| pbf2mongo | pbf2mongo | no | yes | yes | NA | MongoDB |
Из всех представленных вариантов только схема ogr2ogr позволяет использование с различными базами данных, так что выбор для нас очевиден. Замечу, что это наиболее универсальная схема для множества аналитических приложений, в том числе, использующих PostgreSQL/PostGIS. Что касается схемы pgsnapshot, создаваемой с помощью утилиты osmosis — для определения геометрий используется пост-обработка загруженных данных с помощью предоставляемого набора пользовательских функций, что работает намного медленнее, нежели обработка в оперативной памяти непосредственно при загрузке данных утилитой ogr2ogr. Схема оverpass (и одноименный web API) предназначена для работы с атрибутами и не определяет геометрии. Все схемы, использующие для хранения MongoDB, вместо "настоящих" геометрий предоставляют просто сортированные наборы точек, что непригодно для пространственного анализа и предназначено лишь для анализа атрибутов.
После выбора схемы данных (ogr2ogr) необходимо определить правила конвертации геометрий в конфигурационном файле ogr2ogr (osmconf.ini). Дело в том, что, к примеру, замкнутая линия может быть кольцевой автодорогой или контуром дома — поэтому требуется преобразование в пригодный для дальнейшей работы формат, поскольку нам удобно для зданий или районов иметь не только свойство длины границы (определено для линейных объектов), но и их площадь (определено для полигональных, но не для линейных объектов). В OSM одни и те же объекты можно хранить разными способами — скажем, для набора точечных объектов создана коллекция (объект типа "relation") в котором после серии редактирований осталась одна точка (обычно хранится как объект типа "node"). Все это создает неоднозначности, и нам придется явно указать в конфигурационном файле, какие типы геометрий каким атрибутам соответствуют. При дальнейшей работе с данными также придется временами заглядывать в этот конфигурационный файл. Поставляемый с утилитой ogr2ogr конфигурационный файл содержит множество полезных комментариев и советов, так что стоит прочитать его содержимое и поправить для своих целей. Также смотрите мой вариант конфигурации в репозитории osmconf.ini
Теперь мы разобрались с данными OSM и методами их конвертации в набор пространственных данных с определенными геометриями. С полученными данными уже можно работать стандартными способами — измерять длины и площади, отображать на карте… Но мы сталкиваемся с очередной проблемой — не только геометрии, но и атрибуты OSM слабо и неоднозначно специфицированы, так что выбрать, к примеру, леса вовсе не так просто — такая выборка может состоять из нескольких подвыборок по разным значениям атрибутов (и их названия вовсе не очевидны). Эта проблема широко известна, как известны и ее решения. Решение "в лоб" — использовать OSM wiki для поиска нужных атрибутов, однако для регулярной работы с данными этот путь очень трудоемок и чреват ошибками (в том числе потому, что не вся информация в вики точная, а также возможно использование разных тэгов в разных странах, так что все описания атрибутов нужно проверять и проверять). Для регулярного использования оптимальным представляется применение одного из известных каталогизаторов слоев, как основу мы выбрали каталог OpenStreetMap Data in Layered GIS Format от проекта GEOFABRIK. Отметим, что проект предлагает скачать уже готовые актуальные слои OSM, однако в используемом каталоге присутствуют ошибки, так что мы внесли различные изменения, смотрите в репозитории BigQuery SQL файлы запросов для создания слоев каталога.
Таким образом, мы подготовили набор пространственных "сырых" данных с помощью утилиты ogr2ogr с пользовательским файлом конфигурации и сделали на их основе каталог слоев согласно исправленному каталогу слоев OSM от проекта GEOFABRIK. Полученный набор данных открыто доступен как OpenStreetMap Public Dataset и с ним можно работать с помощью Google BigQuery (поддерживается язык SQL). Конечно, этим же путем можно загрузить данные OSM и в другую базу данных по вашему выбору — используйте скрипты загрузки и создания каталога слоев OSM из моего репозитория bigquery-openstreetmap.
Анализ и визуализация
Для примера проанализируем расстояния от зданий до ближайшего парка для городов Нью-Йорк и Токио, смотрите в репозитории BigQuery SQL файлы запросов. Заметим, что предложенные SQL скрипты при желании несложно адаптировать и для других баз данных. Не касаясь особенностей партиционирования данных, отмечу лишь следующий нюанс — ориентация некоторых полигонов зданий в OSM инвертирована, так что вместо формы здания геометрии описывают всю площадь планеты за исключением территории этих зданий. Такие геометрии единичные и просто исключаются с помощью проверки "на разумность" площади зданий, смотрите комментарии в коде ("ignore incorrect geometries with wrong orientation (see GeoJSON RFC 7946)"). Результаты выполнения запросов сохранены в CSV файлы и доступны в репозитории.
Ноутбук с примером вычисления и анимации расстояния зданий до ближайшего парка в городе Нью-Йорк parks2buildings_distance_NY.ipynb:
Ноутбук с примером вычисления и анимации расстояния зданий до ближайшего парка в городе Токио parks2buildings_distance_Tokyo.ipynb:
Для тех, кто дочитал — смотрите ноутбук Результаты анализа дорожной сети города Бостона как пример работы непосредственно с данными OSM — и так тоже можно.

{kind=link}
AmberSP
ДА
N-Cube Автор
Что именно интересует? Как я вижу, OSM популярностью не пользуется в рунете, потому обо всем рассказывать смысла и нет.
AmberSP
В первую очередь — роутинг на открытых данных. Особенно интересны подводные камни, проблемы, их решения. Ежу понятно, что если просто поставить Valhalla какую-нибудь и начать ей пользоваться, то что-то пойдёт не так. Я был бы очень рад возможности поучиться на чужих ошибках.
N-Cube Автор
Ok, принято. Хотите пробежаться по сложностям и решениям для роутинга уровня коммерческих сервисов или просто вводную статью? Скажем, для решения задачи коммивояжера в PgRouting нельзя использовать oneway пути, но где-то в документации есть упоминание, что эта проблема решаема в теории графов — так что любую маршрутную сеть с однонаправленными участками возможно преобразовать в поддерживаемую маршрутную сеть. Цена такого решения — удвоение размера сети. Аналогично, ценой удвоения сети можно еще много возможностей добавить. Опять же, если построенная маршрутная сеть будет актуальна день-неделю-месяц, можно подготовить ее в PostgreSQL/PostGIS/PgRouting и выгрузить в SQLite3/Spatialite чтобы сделать очень быстрый роутинг. Также интересна возможность роутинга масштабов планеты — так, чтобы на одной (огромной) маршрутной сети можно было быстро построить любой маршрут (идея в том, чтобы несколько маршрутных сетей соединить oneway связями так, что маршруты в пределах города/страны/континента вычисляются на сетях разных масштабов). Могу перечислить такие (неочевидные) вещи обзорно, а могу что-то выборочно с кодом (PL/PgSQL) показать детально. Все разом детально рассказать не возьмусь, это придется многие выполненные проекты за последние лет 10 смотреть-вспоминать да и писательского опыта у меня маловато для такой задачи.
P.S. А еще аналогичные графовые алгоритмы в биоинформатике используются для моделирования и синтеза лекарств… только там огромная проблема с исходными данными, так что просто что-то взять и попробовать без доступа к специальным базам данных не получится.
AmberSP
>перечислить такие (неочевидные) вещи обзорно
А я с удовольствием задам уточняющие вопросы там, где наиболее актуально, а остальное схороню в записную книжечку.
Кажется, что у такого подхода идеальное соотношение принесённой ценности к затраченному времени.
Например, уже сейчас понятно, что про мировые путешествия мне не более, чем любопытно, а про быстрый локальный роутинг на SQLite интересны подробности.
N-Cube Автор
Хорошо, принято. Постараюсь не затягивать с публикацией.