
In-Memory — набор концепций хранения данных, когда они сохраняются в оперативной памяти приложения, а диск используется для бэкапа. В классических подходах данные хранятся на диске, а память — в кэше. Например, веб-приложение с бэкендом для обработки данных запрашивает их в хранилище: получает, трансформирует, а по сети перегоняется много данных. В In-Memory вычисления отправляются к данным — в хранилище, где обрабатываются и сеть нагружается меньше.
Благодаря своей архитектуре, в In-Memory в разы, а иногда и на порядки, быстрее скорость доступа к данным. Например, аналитики банка хотят посмотреть в аналитическом приложении отчет по выданным кредитам в динамике по дням за прошлый год. Этот процесс на классической СУБД займет минуты, а c In-Memory появится почти сразу. Всё потому, что подход позволяет кэшировать гораздо больше информации и она хранится в оперативной памяти «под рукой». Приложению не нужно запрашивать данные у жесткого диска, доступность которых ограничена скоростью сети и диска.
Какие еще возможности доступны с In-Memory и что это за подход, расскажет Владимир Плигин — инженер компании GridGain. Этот обзорный материал будет полезен разработчикам бэкенда веб-приложений, которые не работали с In-Memory и хотят попробовать, или интересуются современными трендами разработки программных решений и проектированием архитектуры.
Примечание. Статья основана на расшифровке доклада Владимира на конференции #GetIT Conf. До введения самоизоляции мы регулярно проводили митапы и конференции для разработчиков в Москве и Санкт-Петербурге: обсуждали тренды, актуальные вопросы разработки, проблемы и их решения. Сейчас конференции не провести, зато самое время поделиться полезными материалами с прошлых.
In-Memory используют чаще всего там, где требуется быстрое взаимодействие с пользователем или обработка больших массивов данных.
Я расскажу несколько примеров, как наши клиенты используют решения In-Memory и как вы можете внедрить их у себя.
Один из наших клиентов — крупный поставщик медицинского научного оборудования из США. Они используют In-Memory решение, как основное хранилище данных. Все данные хранятся на диске, а подмножество данных, которое активно используется, держат в оперативной памяти. Методы доступа к хранилищу стандартные — GDBC (Generic Database Connector) и язык запросов SQL.
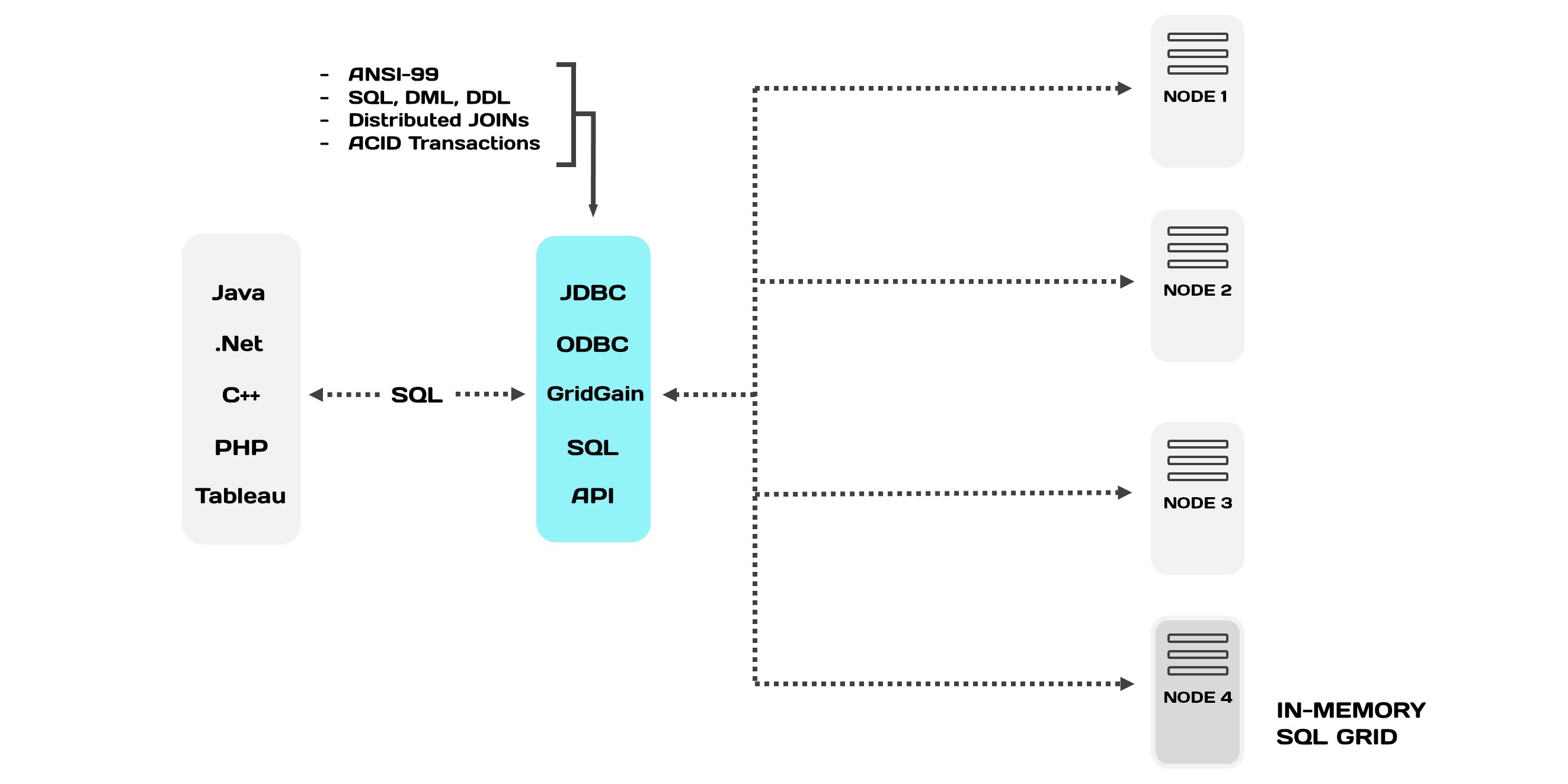
Все вместе это называется In-Memory Database (IMDB) или Memory-Centric Storage. У этого класса решений много названий, это не единственные.
Особенности IMDB:
IMDB частично поддерживают ACID: атомарность, согласованность и изолированность. Но не поддерживают «долговечность» — при отключении питания пропадают все данные. Для решения проблемы можно использовать снэпшоты — «снимок» базы данных, аналог бэкапа БД на жесткий диск, или записывать транзакции (логи), чтобы восстановить данные после перезагрузки.
Представим классическую архитектуру отказоустойчивого веб-приложения. Она работает так: все запросы распределяет веб-балансировщик между серверами. Эта система устойчива, потому что серверы дублируют друг друга и подстраховывают при инцидентах.
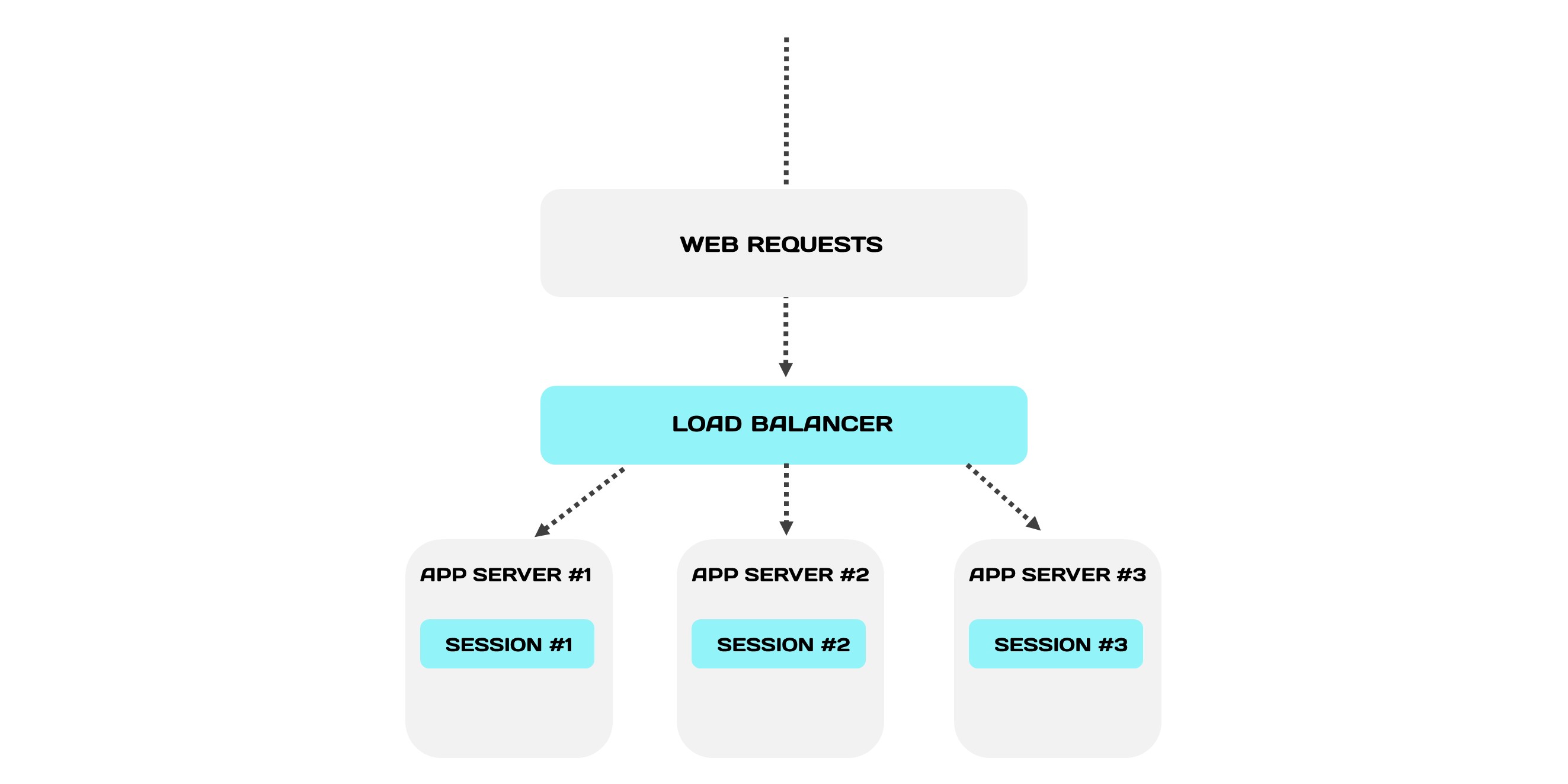
Балансировщик направляет все запросы с одной сессии строго на один сервер. Это механизм стики-сессий: каждая сессия привязывается к серверу, в котором она локально хранится и обрабатывается.
Что произойдет, когда откажет один из серверов?

Сервис не пострадает, потому что архитектура дублирована. Но мы потеряем подмножество сессий умершего сервера. А заодно и пользователей, которые привязаны к этим сессиям. Например, клиент оформляет заказ и внезапно его выкидывает из кабинета. Он будет недоволен, когда заново авторизуется и обнаружит, что все придется оформлять еще раз.
От веб-приложения требуется поддерживать большое количество пользователей и не «тормозить» чтобы им было комфортно работать. Но при отказе, с каждым следующим запросом время на общение с хранилищем сессий будет все больше. Это увеличивает среднюю задержку (latency) для остальных пользователей. Но они не хотят ждать больше, чем привыкли.
Эту проблему можно решить, как другой наш клиент — крупный PASS-провайдер из США. Он использует In-Memory, чтобы кластеризовать веб-сессии. Для этого хранит их не локально, а централизованно — в In-Memory кластере. В этом случае сессии доступны гораздо быстрее, потому что уже они находятся в оперативной памяти.

Когда сервер падает, балансировщик отправляет запросы упавшего на другие серверы, как и в классической архитектуре. Но есть важное различие: сессии хранятся в In-Memory кластере и у серверов есть доступ к сессиям упавшего сервера.
Такая архитектура повышает отказоустойчивость всей системы. Больше того, возможно вообще отказаться от механизма стики-сессий.
Обычно транзакционные и аналитические системы держат отдельно. Когда они разделяются, под нагрузку попадает основная база. Для аналитической обработки данные копируются в реплику, чтобы аналитическая обработка не мешала транзакционным процессам. Но копирование идет с отставанием — без отставания реплицировать невозможно. Если будем делать это синхронно, это будет также замедлять основную базу и выигрыша не получим.
В HTAP всё работает иначе — одно и то же хранилище данных используется для транзакционной нагрузки от приложений, и для аналитических запросов, которые могут долго выполняться. Когда данные лежат в оперативной памяти, аналитические запросы выполняются быстрее, а сервер с БД нагружается меньше (в среднем).
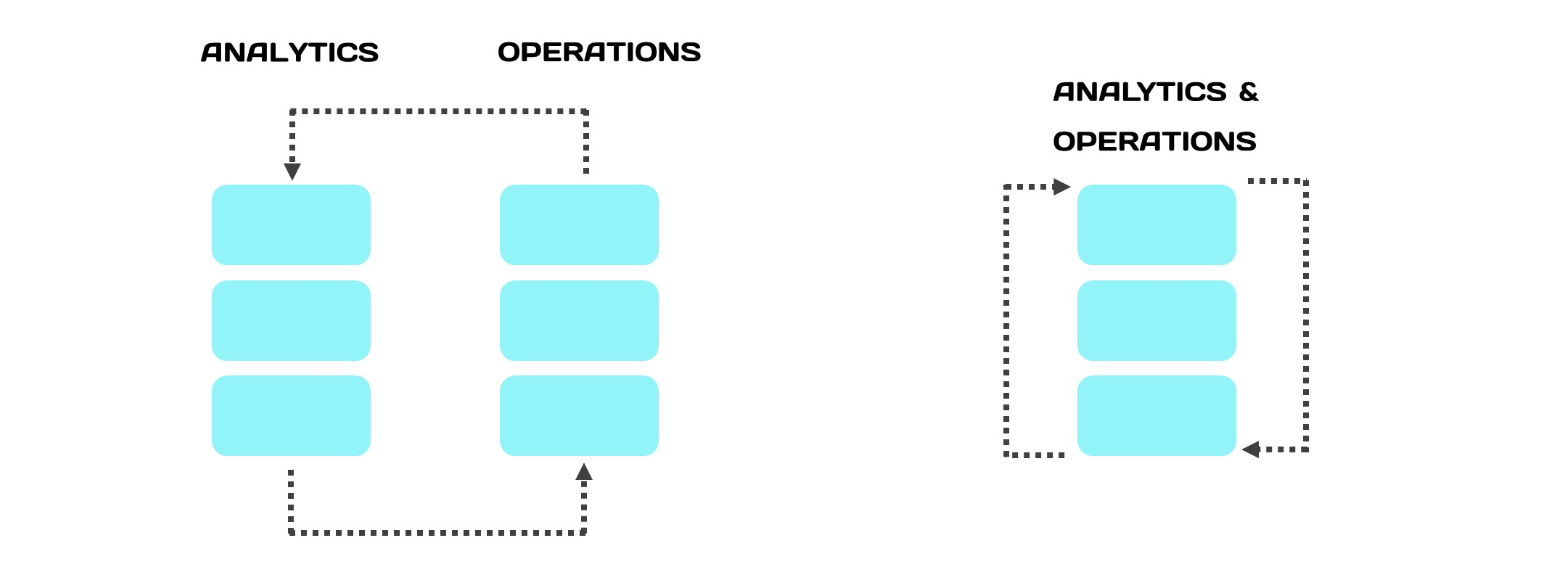
Гибридный подход «ломает стену» между обработкой транзакций и аналитикой. Если мы выполняем аналитику на том же хранилище, то аналитические запросы запускаются на данных из оперативной памяти. Они гораздо точнее, более интерпретируемые и адекватные.
Простой (относительно) способ — разработать все с нуля. Мы держим данные на диске, а горячие храним в памяти. Это помогает переживать перезагрузки серверов или отключения.
Здесь работают два основных сценария, когда данные хранятся на диске. В первом мы хотим переживать падения или штатные перезагрузки кластера или частей — хотим использовать, как простую базу данных. Во втором сценарии, когда данных слишком много, какая-то часть из них в памяти.
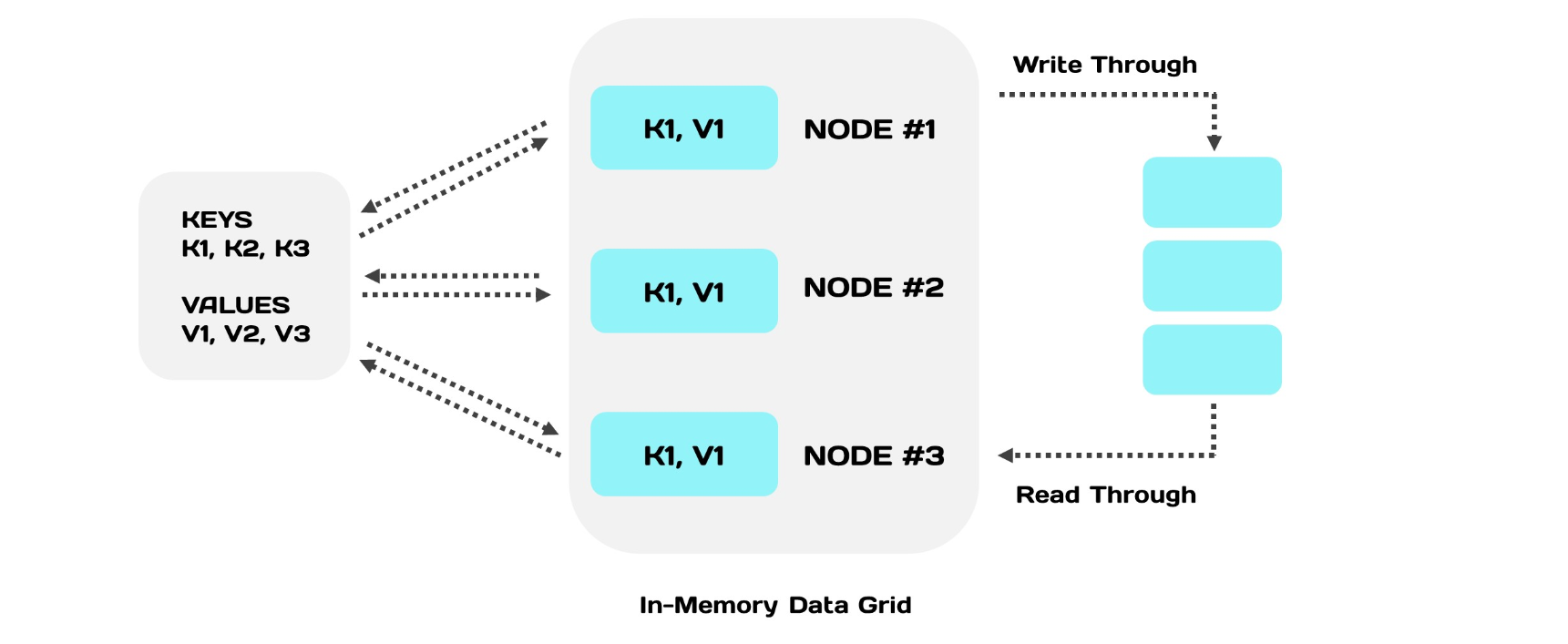
Если нет возможности все построить с нуля, возможно интегрировать In-Memory в уже существующую архитектуру. Но не все In-Memory решения для этого подходят. Есть три обязательных условия. In-Memory решение должно поддерживать:
Если все три условия соблюдены, то интеграция возможна. Помещаем In-Memory Data Grid между приложением и базой. Теперь запросы на запись будут делегироваться в нижестоящую базу, а запросы на чтение — в базу, если данных нет в кэше.
Благодаря своей архитектуре, в In-Memory в разы, а иногда и на порядки, быстрее скорость доступа к данным. Например, аналитики банка хотят посмотреть в аналитическом приложении отчет по выданным кредитам в динамике по дням за прошлый год. Этот процесс на классической СУБД займет минуты, а c In-Memory появится почти сразу. Всё потому, что подход позволяет кэшировать гораздо больше информации и она хранится в оперативной памяти «под рукой». Приложению не нужно запрашивать данные у жесткого диска, доступность которых ограничена скоростью сети и диска.
Какие еще возможности доступны с In-Memory и что это за подход, расскажет Владимир Плигин — инженер компании GridGain. Этот обзорный материал будет полезен разработчикам бэкенда веб-приложений, которые не работали с In-Memory и хотят попробовать, или интересуются современными трендами разработки программных решений и проектированием архитектуры.
Примечание. Статья основана на расшифровке доклада Владимира на конференции #GetIT Conf. До введения самоизоляции мы регулярно проводили митапы и конференции для разработчиков в Москве и Санкт-Петербурге: обсуждали тренды, актуальные вопросы разработки, проблемы и их решения. Сейчас конференции не провести, зато самое время поделиться полезными материалами с прошлых.
Кто и как использует In-Memory
In-Memory используют чаще всего там, где требуется быстрое взаимодействие с пользователем или обработка больших массивов данных.
- Банки используют In-Memory, например, чтобы уменьшать задержки при использовании клиентами приложений или для анализа клиента перед выдачей кредита.
- Финтех использует In-Memory, чтобы улучшать производительность сервисов и приложений для банков, которые отдают обработку и анализ данных на аутсорс.
- Страховые компании: для расчета рисков, например, анализируя данные клиента за несколько лет.
- Логистические компании. Они обрабатывают много данных, например, чтобы просчитывать оптимальные маршруты грузовых и пассажирских перевозок с тысячами параметров, отслеживать статус отправлений.
- Ретейл. In-Memory решения помогают быстрее обслуживать клиентов и обрабатывать большие объемы информации: отгрузки, счета, транзакции, наличие тысяч товаров на складах, готовить аналитические отчеты.
- В IoT In-Memory заменяет традиционные БД.
- Фармацевтические компании используют In-Memory, например, для перебора комбинаций состава лекарств.
Я расскажу несколько примеров, как наши клиенты используют решения In-Memory и как вы можете внедрить их у себя.
In-Memory как основное хранилище
Один из наших клиентов — крупный поставщик медицинского научного оборудования из США. Они используют In-Memory решение, как основное хранилище данных. Все данные хранятся на диске, а подмножество данных, которое активно используется, держат в оперативной памяти. Методы доступа к хранилищу стандартные — GDBC (Generic Database Connector) и язык запросов SQL.
Все вместе это называется In-Memory Database (IMDB) или Memory-Centric Storage. У этого класса решений много названий, это не единственные.
Особенности IMDB:
- Данные, которые хранятся в In-Memory и доступны через SQL, те же самые, что и в других подходах. Они синхронизированы, отличается лишь способ представления, способ обратиться к ним. Между данными работает транзакционность.
- IMDB быстрее, чем реляционные БД, потому что достать информацию из оперативной памяти быстрее, чем с диска.
- У внутренних алгоритмов оптимизации меньше инструкций.
- IMDB подходят для управления данными, событиями и транзакциями в приложениях.
IMDB частично поддерживают ACID: атомарность, согласованность и изолированность. Но не поддерживают «долговечность» — при отключении питания пропадают все данные. Для решения проблемы можно использовать снэпшоты — «снимок» базы данных, аналог бэкапа БД на жесткий диск, или записывать транзакции (логи), чтобы восстановить данные после перезагрузки.
Для создания отказоустойчивых приложений
Представим классическую архитектуру отказоустойчивого веб-приложения. Она работает так: все запросы распределяет веб-балансировщик между серверами. Эта система устойчива, потому что серверы дублируют друг друга и подстраховывают при инцидентах.
Балансировщик направляет все запросы с одной сессии строго на один сервер. Это механизм стики-сессий: каждая сессия привязывается к серверу, в котором она локально хранится и обрабатывается.
Что произойдет, когда откажет один из серверов?
Сервис не пострадает, потому что архитектура дублирована. Но мы потеряем подмножество сессий умершего сервера. А заодно и пользователей, которые привязаны к этим сессиям. Например, клиент оформляет заказ и внезапно его выкидывает из кабинета. Он будет недоволен, когда заново авторизуется и обнаружит, что все придется оформлять еще раз.
От веб-приложения требуется поддерживать большое количество пользователей и не «тормозить» чтобы им было комфортно работать. Но при отказе, с каждым следующим запросом время на общение с хранилищем сессий будет все больше. Это увеличивает среднюю задержку (latency) для остальных пользователей. Но они не хотят ждать больше, чем привыкли.
Эту проблему можно решить, как другой наш клиент — крупный PASS-провайдер из США. Он использует In-Memory, чтобы кластеризовать веб-сессии. Для этого хранит их не локально, а централизованно — в In-Memory кластере. В этом случае сессии доступны гораздо быстрее, потому что уже они находятся в оперативной памяти.
Когда сервер падает, балансировщик отправляет запросы упавшего на другие серверы, как и в классической архитектуре. Но есть важное различие: сессии хранятся в In-Memory кластере и у серверов есть доступ к сессиям упавшего сервера.
Такая архитектура повышает отказоустойчивость всей системы. Больше того, возможно вообще отказаться от механизма стики-сессий.
Гибридная транзакционно-аналитическая обработка (HTAP)
Обычно транзакционные и аналитические системы держат отдельно. Когда они разделяются, под нагрузку попадает основная база. Для аналитической обработки данные копируются в реплику, чтобы аналитическая обработка не мешала транзакционным процессам. Но копирование идет с отставанием — без отставания реплицировать невозможно. Если будем делать это синхронно, это будет также замедлять основную базу и выигрыша не получим.
В HTAP всё работает иначе — одно и то же хранилище данных используется для транзакционной нагрузки от приложений, и для аналитических запросов, которые могут долго выполняться. Когда данные лежат в оперативной памяти, аналитические запросы выполняются быстрее, а сервер с БД нагружается меньше (в среднем).
Гибридный подход «ломает стену» между обработкой транзакций и аналитикой. Если мы выполняем аналитику на том же хранилище, то аналитические запросы запускаются на данных из оперативной памяти. Они гораздо точнее, более интерпретируемые и адекватные.
Интеграция In-Memory решений
Простой (относительно) способ — разработать все с нуля. Мы держим данные на диске, а горячие храним в памяти. Это помогает переживать перезагрузки серверов или отключения.
Здесь работают два основных сценария, когда данные хранятся на диске. В первом мы хотим переживать падения или штатные перезагрузки кластера или частей — хотим использовать, как простую базу данных. Во втором сценарии, когда данных слишком много, какая-то часть из них в памяти.
Если нет возможности все построить с нуля, возможно интегрировать In-Memory в уже существующую архитектуру. Но не все In-Memory решения для этого подходят. Есть три обязательных условия. In-Memory решение должно поддерживать:
- стандартный способ соединения с базой, которая будет находиться под ним (например, MySQL);
- стандартный язык запросов, чтобы не переписывать и изменять логику взаимодействия с хранилищем;
- транзакционность — сохранять семантику взаимодействия.
Если все три условия соблюдены, то интеграция возможна. Помещаем In-Memory Data Grid между приложением и базой. Теперь запросы на запись будут делегироваться в нижестоящую базу, а запросы на чтение — в базу, если данных нет в кэше.
Если вам важен быстрый доступ к данным и их обработка, например, для бизнес-аналитики — можно задуматься над внедрением In-Memory. А для реализации можете использовать оба способа при проектировании новой архитектуры.


musicriffstudio
Неправда.
Этот процесс на классической СУБД займет займёт доли секунды.
sgjurano
Это зависит от объёма данных, структуры таблиц и архитектуры самой базы.
Akuma
Если у вас объем данных такой, что обработка его в классической СУБД займет 10 минут, то думаю в In-Memory вы просто не поместитесь. Или поместитесь не полностью.
VlK
Я не уверен, что понимаю термин in-memory. Болтология какая-то.
Но если речь идёт о последнем поколении бд, что держат в памяти данные, а на дисках только лог, то они бывают вполне себе распределенные.
См термин newsql
Akuma
Само-собой. Тарантул какой-нибудь, например.
Вот только чтобы какой-нибудь аналитический Clickhouse обрабатывал запрос 10 минут, я даже не знаю сколько там должно быть данных. Да даже MySQL при наличии индексов запросы в много-гигабайтные таблицы обрабатывает меньше секунды.
Сколько у вас там данных? Десятки Тб? Это не получится держать In-Memory полностью за адекватные ресурсы.
По крайней мере я это так понимаю.
VlK
Не понимаю, почему это не может быть в социальной сети на сотни миллионов пользователей сотни Тб данных :-)
Последний раз, когда я проверял, наши пользователи генерировали что-то вроде 2.5 Тб в сутки. А всего в первичном хранилище было порядка 2-3 Пб данных.
Paskin
В In-Memory есть всякие интересные оптимизации, которые возможны, но не окупаются с дисками — например, «авто-выделение в справочник» повторяющихся значений или использование всяких трудносериализуемых структур данных в качестве индексов. Когда SAP внедряли свою HANA — у них получалось хранить данных в среднем (ЕМНИП) в 1.6 раза больше чем на машине установлено памяти. А с тех пор уже лет 10 прошло и много чего еще оптимизировали.
VlK
В классическую БД объёмы данных, характерные для сложных аналитических запросов, никто не кладёт.
А распределенные аналитические БД про "доли секунды" даже в рекламных проспектах не пишут, на то они и распределенные.
pshhpshh
А куда кладут?
VlK
В одну из многочисленных аналитических баз данных?