
Несмотря на наличие множества языков различной степени высокоуровневости, сегодня ассемблер не потерял своей актуальности и в индексе TIOBE находится на почётном 10-ом месте (на февраль 2021), обогнав такие модные языки как Go и Rust. Одна из причин его привлекательности – в простоте и максимальной близости к железу; с другой стороны, программирование на ассемблере всё ещё может рассматриваться как искусство и даёт совершенно особые эмоции.
Однако писать программы целиком и полностью на ассемблере — не просто долго, муторно и сложно — но ещё и несколько глупо — ведь высокоуровневые абстракции для того и были придуманы, чтобы сократить время разработки и упростить процесс программирования. Поэтому чаще всего на ассемблере пишут отдельно взятые хорошо оптимизированные функции, которые затем вызываются из языков более высокого уровня, таких как с++ и c#.
Исходя из этого, наиболее удобной средой для программирования будет Visual Studio, в состав которой уже входит MASM. Подключить его к проекту на с/c++ можно через контекстное меню проекта Build Dependencies – Build Customizations…, поставив галочку напротив masm, а сами программы на ассемблере будут располагаться в файлах с расширением .asm (в свойствах которого Item Type должно иметь значение Microsoft Macro Assembler). Это позволит не просто компилировать и вызывать программы на ассемблере без лишних телодвижений – но и осуществлять сквозную отладку, «проваливаясь» в ассемблерный исходник непосредственно из c++ или c# (в том числе и по точке останова внутри ассемблерного листинга), а также отслеживать состояния регистров наряду с обычными переменными в окне Watch.
B Visual Studio нет встроенной подсветки синтаксиса для ассемблера и прочих достижений современного IDE-строения; но её можно обеспечить с помощью сторонних расширений.
AsmHighlighter — исторически первый с минимальным функционалом и неполным набором команд — отсутсвуют не только AVX, но и некоторые из стандартных, в частности fsqrt. Именно этот факт побудил к написанию собственного расширения —
ASM Advanced Editor. В нём, помимо подсветки и сворачивания участков кода (с использованием комментариев ";[", ";[+" и ";]") реализована привязка подсказок к регистрам, всплывающих по наведению курсора ниже по коду (также через комментарии). Выглядит это так:
или так:
Подсказки на команды также присутствуют, но скорее в экспериментальном виде – оказалось, что для их полноценного наполнения времени потребуется больше, чем на написание самого расширения.
Также внезапно выяснилось, что привычные кнопки рас/комментирования выделенного участка кода перестали работать. Поэтому пришлось писать ещё одно расширение, в котором эта функциональность была повешена на одну и ту же кнопку, а необходимость того или иного действия выбирается автоматически.
Asm Dude — обнаружился чуть позже. В нём автор пошёл другим путём и сфокусировал силы на встроенном справочнике команд и автодополнении, в том числе и с отслеживанием меток. Сворачивание кода там также присутствует (по «#region / #end region»), но привязки комментариев к регистрам вроде ещё нет.
С тех пор, как появилась 64-битная платформа, стало нормой писать по 2 варианта приложений. Пора завязывать с этим! Сколько можно тянуть легаси. Это же касается и расширений — найти процессор без SSE2 можно разве что в музее – к тому же, без SSE2 64-битные приложения и не заработают. Никакого удовольствия от программирования не будет, если писать по 4 варианта оптимизированных функций для каждой платформы.Только 64 бит/AVX, только хардкор! Хотя может быть и прямо противоположный взгляд — новые процессоры и так работают быстро, и оптимизацию стоит делать под старые. В общем, всё зависит от конкретной задачи.
Преимущество 64-битной платформе вовсе не в «широких» регистрах – а в том, что этих самых регистров стало в 2 раза больше – по 16 штук как общего назначения, так и XMM/YMM. Это не только упрощает программирование, но и позволяет значительно сократить обращения к памяти.
Если ранее без FPU было никуда, т.к. функции с вещественными числами оставляли результат на вершине стека, то на 64-битной платформе обмен проходит уже без его участия с использованием регистров xmm расширения SSE2. Intel в своих руководствах также активно рекомендует отказаться от FPU в пользу SSE2. Однако есть нюанс: FPU позволяет производить вычисления с 80-битной точностью — что в некоторых случаях может оказаться критически важным. Поэтому поддержка FPU никуда не делаcь, и рассматривать её как устаревшую технологию совершенно точно не стоит. Например, вычисление гипотенузы можно делать «в лоб» без опасения переполнения,
Основная сложность при программировании FPU — это его стековая организация. Для упрощения была написана небольшая утилитка, автоматически генерирующей комментарии с текущим состоянием стека (планировалось добавить подобную функциональность непосредственно в основное расширение для подсветки синтаксиса — но до этого руки так и не дошли)
Современные компиляторы с++ достаточно умны, чтобы автоматически векторизировать код на простых задачах типа суммирования чисел в массиве или поворота векторов, распознавая соответствующие паттерны в коде. Поэтому получить значительный прирост производительности на примитивных задачах не то что не получится — а наоборот, может оказаться, что ваша супер-оптимизированная программа работает медленнее того, что сгенерировал компилятор. Но и далеко идущие выводы из этого делать тоже не стоит — как только алгоритмы становятся чуточку сложнее и неочевиднее для оптимизации — всё волшебство оптимизирующих компиляторов пропадает. Получить десятикратный прирост производительности путём ручной оптимизации в 2021 году по-прежнему ещё возможно.
Итак, в качестве задачи возьмём алгоритм (медленного) преобразования Хартли:
Он также достаточно тривиальный для автоматической векторизации (убедимся позже), но даёт чуть больше пространства для оптимизации. Ну а наш оптимизированный вариант будет выглядеть так:
Обратите внимание: тут нет ни разворачивания цикла, ни SSE/AVX, ни косинусных таблиц, ни снижения сложности за счёт «быстрого» алгоритма преобразования. Единственная явная оптимизация — это итеративное вычисление синуса/косинуса во внутреннем цикле алгоритма непосредственно в регистрах FPU.
Поскольку речь идёт об интегральном преобразовании, то помимо скорости, нас ещё интересует точность вычисления и уровень накопленных погрешностей. В данном случае посчитать её очень просто — делая два преобразования подряд, мы должны получить (в теории) исходные данные. На практике они будут слегка отличаться, и можно будет посчитать ошибку через среднеквадратическое отклонения полученного результата от аналитического.
Результаты авто-оптимизации программы на c++ также могут сильно зависеть от настроек параметров компилятора и выбора допустимого расширенного набора инструкций (SSE/AVX/etc). При этом есть два нюанса:
Самый интересный параметр оптимизации – это Floating Point Model, принимающий значения Precise|Strict|Fast. В случае с Fast компилятору разрешается делать любые математические преобразования на своё усмотрение (в том числе и итеративные вычисления) – собственно, только в этом режиме и происходит автоматическая векторизация.
Итак, компилятор Visual Studio 2019, целевая платформа AVX2, Floating Point Model=Precise. Чтобы было ещё интереснее — будет измерять из проекта на c# на массиве из 10000 элементов:
C# ожидаемо оказался медленнее с++, а функция на ассемблере оказалась быстрее в 9 раз! Однако ещё рано радоваться — установим Floating Point Model=Fast:

Как видно, это помогло значительно ускорить код и отставание от ручной оптимизации составило всего лишь в 1.8 раз. Но вот что не изменилось – так это погрешность. Что тот, что другой вариант дал ошибку в 4 значащих цифры – а это немаловажно при математических вычислениях.
В данном случае наш вариант оказался и быстрее, и точнее. Но так бывает не всегда – и выбирая FPU для хранения результатов мы неизбежно будем терять в возможности оптимизации векторизацией. Также никто не запрещает комбинировать FPU и SSE2 в тех случаях, когда это имеет смысл (в частности, такой подход я использовал в реализации double-double арифметики, получив 10-кратное ускорение при умножении).
Дальнейшая оптимизация преобразования Хартли лежит уже в другой плоскости и (для произвольного размера) требует алгоритма Блюстейна, который также критичен к точности промежуточных вычислений. Ну а этот проект можно скачать на GitHub, и в качестве бонуса там также присутствуют пара функций для суммирования/масштабирования массивов для FPU/SSE2/AVX (в образовательных целях).
Литературы по ассемблеру навалом. Но можно выделить несколько ключевых источников:
1. Официальная документация от Intel. Ничего лишнего, вероятность опечаток минимальна (кои в печатной литературе встречаются повсеместно).
2. Официальная документация от Microsoft.
3. Онлайн справочник, спарсенный из официальной документации.
4. Сайт Агнера Фога, признанного эксперта по оптимизации. Также содержит образцы оптимизированного кода на C++ с использованием интринсиков.
5. SIMPLY FPU.
6. 40 Basic Practices in Assembly Language Programming.
7. Все, что нужно знать, чтобы начать программировать для 64-разрядных версий Windows.
Однако писать программы целиком и полностью на ассемблере — не просто долго, муторно и сложно — но ещё и несколько глупо — ведь высокоуровневые абстракции для того и были придуманы, чтобы сократить время разработки и упростить процесс программирования. Поэтому чаще всего на ассемблере пишут отдельно взятые хорошо оптимизированные функции, которые затем вызываются из языков более высокого уровня, таких как с++ и c#.
Исходя из этого, наиболее удобной средой для программирования будет Visual Studio, в состав которой уже входит MASM. Подключить его к проекту на с/c++ можно через контекстное меню проекта Build Dependencies – Build Customizations…, поставив галочку напротив masm, а сами программы на ассемблере будут располагаться в файлах с расширением .asm (в свойствах которого Item Type должно иметь значение Microsoft Macro Assembler). Это позволит не просто компилировать и вызывать программы на ассемблере без лишних телодвижений – но и осуществлять сквозную отладку, «проваливаясь» в ассемблерный исходник непосредственно из c++ или c# (в том числе и по точке останова внутри ассемблерного листинга), а также отслеживать состояния регистров наряду с обычными переменными в окне Watch.
Подсветка синтаксиса
B Visual Studio нет встроенной подсветки синтаксиса для ассемблера и прочих достижений современного IDE-строения; но её можно обеспечить с помощью сторонних расширений.
AsmHighlighter — исторически первый с минимальным функционалом и неполным набором команд — отсутсвуют не только AVX, но и некоторые из стандартных, в частности fsqrt. Именно этот факт побудил к написанию собственного расширения —
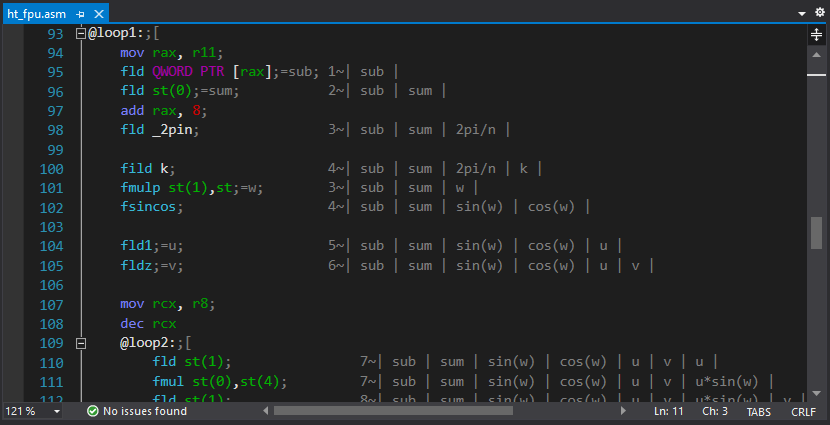
ASM Advanced Editor. В нём, помимо подсветки и сворачивания участков кода (с использованием комментариев ";[", ";[+" и ";]") реализована привязка подсказок к регистрам, всплывающих по наведению курсора ниже по коду (также через комментарии). Выглядит это так:
;rdx=ссылка на текущий элемент входного массиваили так:
mov rcx, 8;=счётчик циклаПодсказки на команды также присутствуют, но скорее в экспериментальном виде – оказалось, что для их полноценного наполнения времени потребуется больше, чем на написание самого расширения.
Также внезапно выяснилось, что привычные кнопки рас/комментирования выделенного участка кода перестали работать. Поэтому пришлось писать ещё одно расширение, в котором эта функциональность была повешена на одну и ту же кнопку, а необходимость того или иного действия выбирается автоматически.
Asm Dude — обнаружился чуть позже. В нём автор пошёл другим путём и сфокусировал силы на встроенном справочнике команд и автодополнении, в том числе и с отслеживанием меток. Сворачивание кода там также присутствует (по «#region / #end region»), но привязки комментариев к регистрам вроде ещё нет.
32 vs. 64
С тех пор, как появилась 64-битная платформа, стало нормой писать по 2 варианта приложений. Пора завязывать с этим! Сколько можно тянуть легаси. Это же касается и расширений — найти процессор без SSE2 можно разве что в музее – к тому же, без SSE2 64-битные приложения и не заработают. Никакого удовольствия от программирования не будет, если писать по 4 варианта оптимизированных функций для каждой платформы.
Преимущество 64-битной платформе вовсе не в «широких» регистрах – а в том, что этих самых регистров стало в 2 раза больше – по 16 штук как общего назначения, так и XMM/YMM. Это не только упрощает программирование, но и позволяет значительно сократить обращения к памяти.
FPU
Если ранее без FPU было никуда, т.к. функции с вещественными числами оставляли результат на вершине стека, то на 64-битной платформе обмен проходит уже без его участия с использованием регистров xmm расширения SSE2. Intel в своих руководствах также активно рекомендует отказаться от FPU в пользу SSE2. Однако есть нюанс: FPU позволяет производить вычисления с 80-битной точностью — что в некоторых случаях может оказаться критически важным. Поэтому поддержка FPU никуда не делаcь, и рассматривать её как устаревшую технологию совершенно точно не стоит. Например, вычисление гипотенузы можно делать «в лоб» без опасения переполнения,
а именно
fld x
fmul st(0), st(0)
fld y
fmul st(0), st(0)
faddp st(1), st(0)
fsqrt
fstp hypotОсновная сложность при программировании FPU — это его стековая организация. Для упрощения была написана небольшая утилитка, автоматически генерирующей комментарии с текущим состоянием стека (планировалось добавить подобную функциональность непосредственно в основное расширение для подсветки синтаксиса — но до этого руки так и не дошли)
Пример оптимизации: преобразование Хартли
Современные компиляторы с++ достаточно умны, чтобы автоматически векторизировать код на простых задачах типа суммирования чисел в массиве или поворота векторов, распознавая соответствующие паттерны в коде. Поэтому получить значительный прирост производительности на примитивных задачах не то что не получится — а наоборот, может оказаться, что ваша супер-оптимизированная программа работает медленнее того, что сгенерировал компилятор. Но и далеко идущие выводы из этого делать тоже не стоит — как только алгоритмы становятся чуточку сложнее и неочевиднее для оптимизации — всё волшебство оптимизирующих компиляторов пропадает. Получить десятикратный прирост производительности путём ручной оптимизации в 2021 году по-прежнему ещё возможно.
Итак, в качестве задачи возьмём алгоритм (медленного) преобразования Хартли:
код
static void ht_csharp(double[] data, double[] result)
{
int n = data.Length;
double phi = 2.0 * Math.PI / n;
for (int i = 0; i < n; ++i)
{
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
double w = phi * i * j;
sum += data[j] * (Math.Cos(w) + Math.Sin(w));
}
result[i] = sum / Math.Sqrt(n);
}
}Он также достаточно тривиальный для автоматической векторизации (убедимся позже), но даёт чуть больше пространства для оптимизации. Ну а наш оптимизированный вариант будет выглядеть так:
код (комментарии удалены)
ht_asm PROC
local sqrtn:REAL10
local _2pin:REAL10
local k:DWORD
local n:DWORD
and r8, 0ffffffffh
mov n, r8d
mov r11, rcx
xor rcx, rcx
mov r9, r8
dec r9
shr r9, 1
mov r10, r8
sub r10, 2
shl r10, 3
finit
fld _2pi
fild n
fdivp st(1), st
fstp _2pin
fld1
fild n
fsqrt
fdivp st(1), st
;
mov rax, r11
mov rcx, r8
fldz
@loop0:
fadd QWORD PTR [rax]
add rax, 8
loop @loop0
fmul st, st(1)
fstp QWORD PTR [rdx]
fstp sqrtn
add rdx, 8
mov k, 1
@loop1:
mov rax, r11
fld QWORD PTR [rax]
fld st(0)
add rax, 8
fld _2pin
fild k
fmulp st(1),st
fsincos
fld1;=u
fldz;=v
mov rcx, r8
dec rcx
@loop2:
fld st(1)
fmul st(0),st(4)
fld st(1)
fmul st,st(4)
faddp st(1),st
fxch st(1)
fmul st, st(4)
fxch st(2)
fmul st,st(3)
fsubrp st(2),st
fld st(0)
fadd st, st(2)
fmul QWORD PTR [rax]
faddp st(5), st
fld st(0)
fsubr st, st(2)
fmul QWORD PTR [rax]
faddp st(6), st
add rax, 8
loop @loop2
fcompp
fcompp
fld sqrtn
fmul st(1), st
fxch st(1)
fstp QWORD PTR [rdx]
fmulp st(1), st
fstp QWORD PTR [rdx+r10]
add rdx,8
sub r10, 16
inc k
dec r9
jnz @loop1
test r10, r10
jnz @exit
mov rax, r11
fldz
mov rcx, r8
shr rcx, 1
@loop3:;[
fadd QWORD PTR [rax]
fsub QWORD PTR [rax+8]
add rax, 16
loop @loop3;]
fld sqrtn
fmulp st(1), st
fstp QWORD PTR [rdx]
@exit:
ret
ht_asm ENDPОбратите внимание: тут нет ни разворачивания цикла, ни SSE/AVX, ни косинусных таблиц, ни снижения сложности за счёт «быстрого» алгоритма преобразования. Единственная явная оптимизация — это итеративное вычисление синуса/косинуса во внутреннем цикле алгоритма непосредственно в регистрах FPU.
Поскольку речь идёт об интегральном преобразовании, то помимо скорости, нас ещё интересует точность вычисления и уровень накопленных погрешностей. В данном случае посчитать её очень просто — делая два преобразования подряд, мы должны получить (в теории) исходные данные. На практике они будут слегка отличаться, и можно будет посчитать ошибку через среднеквадратическое отклонения полученного результата от аналитического.
Результаты авто-оптимизации программы на c++ также могут сильно зависеть от настроек параметров компилятора и выбора допустимого расширенного набора инструкций (SSE/AVX/etc). При этом есть два нюанса:
- Современные компиляторы склонны всё возможное вычислять на этапе компиляции – поэтому вполне возможно в откомпилированном коде вместо алгоритма увидеть заранее посчитанное значение, что при замере производительности даст преимущество компилятору в 100500 раз. Во избежание этого в моих замерах используется внешняя функция zero(), добавляющая неопределённости входным параметрам.
- Если компилятору указать «не использовать AVX» — это ещё не значит, что в полученном коде будет отсутствовать AVX. Внешние библиотеки сами проверяют доступный набор команд на текущей платформе и выбирают соответствующую реализацию. Поэтому единственно надёжный способ сравнения производительности в таком случае – испытывать код на платформе, где AVX отсутствует в принципе.
Самый интересный параметр оптимизации – это Floating Point Model, принимающий значения Precise|Strict|Fast. В случае с Fast компилятору разрешается делать любые математические преобразования на своё усмотрение (в том числе и итеративные вычисления) – собственно, только в этом режиме и происходит автоматическая векторизация.
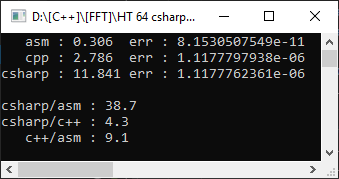
Итак, компилятор Visual Studio 2019, целевая платформа AVX2, Floating Point Model=Precise. Чтобы было ещё интереснее — будет измерять из проекта на c# на массиве из 10000 элементов:
C# ожидаемо оказался медленнее с++, а функция на ассемблере оказалась быстрее в 9 раз! Однако ещё рано радоваться — установим Floating Point Model=Fast:
Как видно, это помогло значительно ускорить код и отставание от ручной оптимизации составило всего лишь в 1.8 раз. Но вот что не изменилось – так это погрешность. Что тот, что другой вариант дал ошибку в 4 значащих цифры – а это немаловажно при математических вычислениях.
В данном случае наш вариант оказался и быстрее, и точнее. Но так бывает не всегда – и выбирая FPU для хранения результатов мы неизбежно будем терять в возможности оптимизации векторизацией. Также никто не запрещает комбинировать FPU и SSE2 в тех случаях, когда это имеет смысл (в частности, такой подход я использовал в реализации double-double арифметики, получив 10-кратное ускорение при умножении).
Дальнейшая оптимизация преобразования Хартли лежит уже в другой плоскости и (для произвольного размера) требует алгоритма Блюстейна, который также критичен к точности промежуточных вычислений. Ну а этот проект можно скачать на GitHub, и в качестве бонуса там также присутствуют пара функций для суммирования/масштабирования массивов для FPU/SSE2/AVX (в образовательных целях).
Что почитать
Литературы по ассемблеру навалом. Но можно выделить несколько ключевых источников:
1. Официальная документация от Intel. Ничего лишнего, вероятность опечаток минимальна (кои в печатной литературе встречаются повсеместно).
2. Официальная документация от Microsoft.
3. Онлайн справочник, спарсенный из официальной документации.
4. Сайт Агнера Фога, признанного эксперта по оптимизации. Также содержит образцы оптимизированного кода на C++ с использованием интринсиков.
5. SIMPLY FPU.
6. 40 Basic Practices in Assembly Language Programming.
7. Все, что нужно знать, чтобы начать программировать для 64-разрядных версий Windows.
Appendix: Почему бы просто не использовать интринсики (Intrinsics)?
Скрытый текст
С тех пор, как были придуманы интринсики, этот вопрос возникает каждый раз, как только заходит речь о какой-либо оптимизации на ассемблере — ведь они для того и были придуманы, чтобы иметь возможность использовать SIMD-инструкции без необходимости программирования на ассемблере. Поэтому короткий ответ — используйте.
Длинный ответ:
Длинный ответ:
- Не вся оптимизация делается векторизацией. Если во времена DOS оптимизация делалась за счёт экономии тактов и количества обращений к памяти, то сейчас основной инструмент оптимизации – это организация оптимальной работы с памятью во избежание промахов кеша.
- Интринсики к новым инструкциям появляются с некоторым запаздыванием. Недостающие интринсики нельзя добавить простым включением заголовочного файла – их поддержка должна быть реализована на уровне компилятора.
- Не на все инструкции возможно сделать интринсики. Когда оптимизация касается точности математических выражений, можно добиться значительных улучшений, программируя непосредственно на математическом сопроцессоре (FPU). Для команд сопроцессора же интринсики отсутствуют. Они также отсутствуют для команд, на результат которых влияют флаги переноса/переполнения/etc.
- Интринсики не представляют из себя какой-либо высокоуровневый фреймворк – по факту, это не более чем лишь ещё один уровень мнемоник над ассемблерными инструкциями, мало чем отличающийся от ассемблерных вставок. Что автоматически означает, что код вовсе не становится более читаемым, а при его написании так или иначе нужно придерживаться ассемблерного стиля мышления.
- Также, из C++ кода вовсе не очевидно, что существуют какие-то ограничения на количество одновременно используемых SIMD-регистров. В 32-х битном ассемблере вы не можете использовать XMM8 наравне с XMM0 / XMM7 – код просто не откомпилируется. А интринсиками вы можете определить хоть тысячу одновременно используемых регистров — и компилятор вынужден будет сам решать, что хранить в регистрах, что в памяти, и как между собой их оптимально комбинировать. В таком случае применение интринсиков не даёт никаких преимуществ в плане увеличения производительности – компилятор работает с ними так же, как и с обычными структурами на C++.
- Программировать на ассемблере не так уж и сложно, особенно если не пытаться делать на нём хитрые высокоуровневые конструкции. Многое можно почерпнуть, изучая ассемблерный листинг простых алгоритмов в режиме отладки и с различными уровнями оптимизации – компилятор от Microsoft производит достаточно лёгкий для понимания и в то же время эффективный код, комментируя его исходным кодом на C++.
nckma
Честно говоря пару раз пробовал переписать сишную функцию на ассемблере. Как я не старался прироста в производительности не получил.
byman
Так то Intel, там и компилятор нормальный. А я вот как не напишу функцию на ассемблере для своего VLIW DSP — все раз в 10 быстрее чем на Си.
Nagg
Напишите проверку что аргумент ф-ции делится на 10 без остатка на чистом асме и сравните с Си.
OvO
Так язык не увеличивает производительность, он расширяет возможности. Перед переписыванием нужно понимать что ты сможешь сделать лучше компилятора.
nckma
Ну и откуда взять это понимание?
Я помню времена, когда просто посчитав количество инструкций в функции можно было бы примерно оценить ее производительность. Но сейчас такое не работает. Глядя на количество строк кода невозможно в уме прикинуть быстр этот код или нет.
А вот компилятор скорее всего все это знает.
OvO
Очевидно, из архитектуры процессора и эмпирической оценки времени выполнения команд. Как-то смотришь на результат компиляции и находишь команды, которые можно объединить, переставить или убрать исходя из общего смысла кода.
По крайне мере, у меня получалось векторизация в циклах лучше, чем gcc 4.8.x c -O3.
А целые программы ассемблере писать можно только с большого горя — когда стека нет, например.
Int_13h
Вот, например, отреверсенная программа после С-компилятора, архитектура со стеком и всеми делами:
Штуки КАПСОМ на всю строку без команд — это метки.
OvO
И что из этого следует? Если нужна оптимизация, то надо для начала смотреть код и настройки компилятора.
picul
Вы сравниваете теплое с мягким — очевидно, что тривиальная программа при прочих равных медленнее/менее точна чем программа с итеративным вычислением тригонометрии. Так что непонятно, на что списывать разницу в результатах — на ассемблер или на алгоритм. Нужно реализовать итеративную тригонометрию на C# и сравнить ассемблер с ней.
Ну и странно, что fsincos вызывается n раз — можно посчитать функции только для phi, а дальше все по формулам.
Refridgerator Автор
Сравнение конечно же несправедливое. Компилятор использует новейший набор инструкций AVX2, а я — устаревшую технологию, медленную по определению. Никто же этим фактом не возмутился. Сравниваются же подходы к оптимизации в первую очередь — машинное против человеческого. Итеративное вычисление ко/синусов компилятору вполне доступно (как минимум в теории) — ведь это же по сути просто комплексное умножение.
fsincos вызывается n раз во внешнем цикле — потому что регистров сопроцессора не хватило бы, чтобы их все там держать. Пришлось бы сохранять их во внешних переменных — а это слегка бы нарушило чистоту эксперимента. А так мы получаем повышение точности вычислений без явного определений переменных расширенной точности.
Refridgerator Автор
Вот сравнение с исправленным вариантом от teology (cpp2 и csharp2) также на 10000 элементах:

Результат стал получше, но не в разы — причём с си-шарпом практически сравнялись. А вот падение точности — катастрофическое, 3 значащих цифры только осталось.
teology
kovserg увидел ошибку в моем коде, надо ввести временную переменную tmp, в которой сохранить предыдущее значение cos_w и cos_dw и использовать tmp при вычислении sin_w, sin_dw.
Оптимизатор настраиваете при компиляции на максимум -O3?
Refridgerator Автор
1. Да, tmp я и добавил. 2. Оптимизация — Maximum Optimization (Favor Speed) (/O2), /O3 в вариантах выбора нету. Есть /Ox, но по результату принципиально не отличается — и то в худшую сторону.
teology
Может long double?)
picul
Странные у Вас тайминги. Я не смог запустить Ваш ассемблер, но сварганил сравнение изначального C++ с оптимизированным — так у меня оптимизированный в 9 быстрее. Но точность — да, проседает, причем я даже не знаю почему, вроде бы вычисление тригонометрии должно быть менее точным чем сложения/умножения.
Вот код:
Refridgerator Автор
Тайминги в секундах. Мерил и из шарпа, и из плюсов — почти совпадают. А где, кстати, ваши? У вас же, я так понимаю, другой компилятор и возможно даже другая платформа.
picul
Windows/VS 2019. Но я понял, в чем было дело — я не включил поддержку AVX2. С ней происходит векторизация внутреннего цикла изначального варианта, вызываются функции "__vdecl_sin4"/"__vdecl_cos4", которые видимо обрабатывают по 4 аргумента за раз, и тогда соотношение времени выполнения двух алгоритмов у меня примерно совпадает с Вашим. Но тут стоит заметить, что для оптимизированного алгоритма компилятор векторизацию не сделал (хотя unroll на 10 итераций сделать смог), если доделать ее — результат должен улучшиться.
teology
Все просто объяснимо. Синус-косинус считается каждый раз заново и погрешность там возникает при вычислении 10-20 слагаемых и эта ошибка более-менее постоянна в течение всего алгоритма. А алгоритм с рекурсивной формулой накапливает ошибку при n^2 пересчетах. Проделайте вычисления самой первой итерации большого цикла вручную и поймете.
NBAH79
Шарп то тут при чем? Давайте бульдозером картофель копать… ;) Кроме того, если уж такая проблема и возникает, ничего не мешает шарпом подгрузить dll.
teology
Попробуйте:
1. Вместо умножений использовать инкремент.
2. Вместо вычислений sin/cos углов вычислять sin/cos суммы углов (текущий угол = предыдущий угол + инкремент).
3. На всякий случай закэшировать вычисление 1/sqrt(n), вдруг компилятор слабо оптимизирует.
Можете еще выбросить вычисление углов w и dw, но компилятор должен это сам сделать.
Итого: в циклах нет ни одного вычисления синуса и косинуса. Ускорение должно составить 40 крат?
picul
В ассемблере так и сделано, но только для внутреннего цикла, во внешнем считаются sin/cos каждую итерацию.
kovserg
1. Вам понадобиться временная переменная иначе, результат будет немного странный.
2. При больших n можно огрести проблемы с численной неустойчивостью.
3. Зачем w и dw если не используются
ps: БПФ ускорит гораздо лучше особенно при больших n
teology
Надо придумать преобразование без хранения во временной переменной.)
Refridgerator Автор
Ваш код даёт некорректный результат, в нём где-то ошибка. Даже если на это закрыть глаза — то он работает всего лишь в 2 раза быстрее (с компилятором c#) наивной реализации.
Refridgerator Автор
UPD: тормоза в вашем коде были связаны с тем, что там появлялся NaN. Исправленный вариант работает нормально (по скорости), результаты сравнения выше.
teology
Тогда этот код C# может оказаться быстрее ассемблера.
P.S. Я проверил, код эквивалентно работает, ошибок нет.