

Голосовые агенты становятся все совершеннее, буквально каждый месяц появляются новые интересные наработки. Одна из них — немецкий проект по созданию детектора лжи для колл-центров. Речь идет о создании системы, которая может с высокой степенью вероятности определить, говорит звонящий в колл-центр абонент правду либо же пытается приврать/приукрасить свои утверждения или скрыть намерения.
Система базируется на специфическом дата-сете, сформированном из аудио-записей нескольких десятков преподавателей и студентов. Добровольцы участвовали в дебатах, обсуждая острые темы вроде смертной казни и платного обучения, а произносимые речи записывались на диктофон. О результатах проекта — под катом.
Модель обучали на архитектуре, которая включала сверточные нейронные сети (CNN) и долгую краткосрочную память (LSTM). Точность модели в итоге составляет 98%.
После изучения результатов проекта модель признали пригодной для анализа широкого спектра процессов обслуживания, с уклоном в коммуникацию с клиентами по телефонной связи. Разработанный алгоритм может применяться в любой ситуации, когда сотруднику колл-центра нужно знать, говорит ли клиент искренне.
Зачем? Подобное может понадобиться, например, при анализе сомнительных страховых случаев или оценки утверждений соискателя при приеме на работу. Если он будет делать ложные заявления, система сможет выявить неправду. В итоге алгоритм сможет не только снизить операционные потери сервисных компаний но и уменьшит количество неправдивых утверждений со стороны абонентов.
Подробнее о дата-сете
В отсутствие подходящего общедоступного дата-сета на немецком языке исследователи из Университета прикладных наук Ной-Ульма (HNU) собрали собственный. Для этого пришлось привлекать добровольцев. Авторы идеи решили их найти при помощи простейшего метода — раздачей информационных материалов. Листовки раздавались и расклеивались в университете и местных учебных заведениях. В итоге было отобрано 40 добровольцев в возрасте от 16 лет. Волонтерам платили подарочными картами Amazon на 10 евро — никакого другого вознаграждения не предусматривалось.
Встречи добровольцев проводились по модели дискуссионного клуба, призванной резко поляризовать мнения и вызвать сильные заявления на спорные темы. Это помогало привести к эмоциональному напряжению участников, которое может возникнуть в проблемных разговорах операторов колл-центров с клиентами по телефону.
Участникам дискуссий можно было три минуты выступать перед другими добровольцами на такие темы:
- Следует ли вернуть в Германии смертную казнь и публичные наказания?
- Следует ли в Германии взимать плату за обучение, покрывающую расходы государства?
- Следует ли легализовать в Германии употребление тяжелых наркотиков, таких как героин и метамфетамин?
- Следует ли запретить в Германии сети ресторанов, предлагающих нездоровую фаст-фуд еду, например McDonald’s или Burger King?
Обработка данных
В ходе обработки данных предпочтение отдавалось подходу автоматического распознавания речи (ASR), а не подходу НЛП (где речь анализируется на лингвистическом уровне с определением «температуры» дискуссии.
Предварительно обработанные образцы записей были проанализированы сначала при помощи Мел-кепстральных коэффициентов (MFCC). Это весьма надежный, зарекомендовавший себя ранее метод, который весьма популярен среди специалистов по анализу речи. Этот метод был впервые предложен в 1980 году. Он не требует использования значительных вычислительных мощностей и не особо требователен к качеству записей. Это особенно важно, поскольку качество аудиопотока в колл-центрах далеко не всегда можно назвать высоким.
Комбинация этих методов позволила создать весьма надежную модель обработки звука, которая вполне работоспособна без привлечения значительных ресурсов и в условиях не самого высокого качества аудиозаписей.
Последние обрабатывались еще и с использованием алгоритма быстрого преобразования Фурье (БПФ) для получения спектрального профиля каждого «аудиокадра» перед окончательной фиксацией для шкалы Мела.
Обучение, результаты и ограничения
Во время обучения извлеченные векторы признаков передаются на слой сверточной сети с распределением по времени, выравниваются и затем передаются на уровень LSTM.
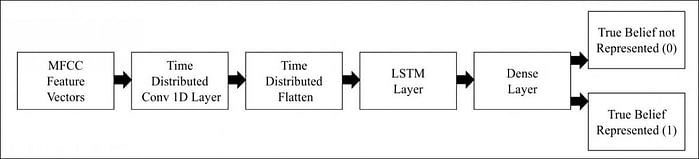
В результате обучения точность системы составила 98,91% с точки зрения распознавания намерений (т.е. когда заявленное голосом действие или намерение может не отражать реального положения вещей).
Конечно, для того, чтобы утверждать, что проект успешен на все 100%, желательно иметь более объемную исходную базу данных, т.е. дата-сет не из 40 аудиозаписей. Кроме того, любой язык специфичен и модель, обученная на немецком языке, может не подходить для работы с пользователями, которые говорят на других языках. Поэтому проект требует доработки, но его результаты и точность модели позволяют говорить о том, что модель вполне надежна.
Комментарии (29)

anonymous
00.00.0000 00:00
GospodinKolhoznik
29.07.2021 09:13Не правду и не неправду, они говорят пустоту по составленному шаблону, особо не пытаясь вникнуть в суть вопросов.

shushu
29.07.2021 06:22А вот мне бы хотелось узнать более технические подробности этого :)
Например как вообще происходит захват звука в риалтайм для скормления потока в AI API?
Ну и я так понимаю что AI API должен поддерживать стриминговые данные?

barbaris76
29.07.2021 07:17Ну, то есть, судя по методике сбора датасета, фактически модель определяет не то, что поцыэнт говорит правду или неправду, а то, что он волнуется, слишком сильно эмоционирует и т.п.

C4ET4uK
29.07.2021 07:38Мне вот интересно, а насколько это законно, не получат ли множественные иски от 2% ложно-положительных?

DmitriiR
29.07.2021 07:55Скорей всего решение ИИ будет поводом для более глубокой проверки.
GospodinKolhoznik
29.07.2021 08:47+2Нет, оно будет поводом для отказа. Глубокую проверку слишком дорого и неэффективно с точки зрения ведения бизнеса проводить.
DmitriiR
29.07.2021 09:42"при анализе сомнительных страховых случаев "
для проверки...

vikarti
02.08.2021 10:32Не получится вмешаться в голос же на телефоне.
Скорее уж всякие Zadarma (у которых IP-телефония) сделают такую доработку.
А потом сделает ТиньковМобайл, в рамках Олега (в голосовой поток они умеют уже лазить же)
GospodinKolhoznik
29.07.2021 08:37+2Немецкий проект по созданию детектора лжи для колл-центров в ходе исследования на аудио-записях нескольких десятков преподавателей и студентов доказали эффективность собственного детектора лжи на 98%.
Ну вот совсем незаангажированное исследование. Ни один детектор лжи до сих пор не смог доказать статистическую значимость при проведении объективного эксперимента, а эти ребята утверждают, что их шайтан машинка не такая.
Все существующие детекторы определяют не ложь, а в лучшем случае волнение человека. И этот не исключение.
Я уверен, что их детектор такой же лженаучный, как все прочие, но к моему глубокому сожалению боссы многих компаний по всему миру скажут "А почему бы и нет? Внедряем!" И будут заворачивать людей на основании мало того, что аморальных методов, так ещё и лженаучных.

abutorin
29.07.2021 08:40+240 добровольцев по 3 часа? И ИИ начинает отличать правду от неправды в 98% случаев? Тесла с принятием луны за желтый сигнал светофора (https://habr.com/ru/news/t/569702/) на дата-сете не меньше десятков тысяч часов нервно курит в сторонке.
GreySS
29.07.2021 09:31+1Я так понимаю скоро начнут появляться приложения для смартфонов, для обфускации голоса.


olehorg
29.07.2021 12:06+3представьте себе условную "яжемать", которая (например) разворачивалась через двойную сплошную и "допустила проишествие".
она - хоть какой интеллект будет анализировать ее голос - будет внутренне абсолютно уверена в своей правоте "потому что мне надо и я включила поворотник".
в то же время профессиональный водитель (который был вторым участником) будет корить себя за то что начал тормозить на секунду позже - и это сомнение будет выявлено искусственным интеллектом.
очень много людей, совершающих преступления, искренне уверены в своей правоте и правомочности. Если ориентироваться на голос как на уверенность - то все психи-преступники будут на свободе (или будут получать незаслуженные ништяки от кол-центров компаний).


Stormwalker
29.07.2021 13:03Это автоматизация предрассудков. Очень соблазнительная технология, которая, конечно, найдет некоторых лжецов, но мне страшно представить, сколько людей с настоящими проблемами она заклеймит лжецами.

Tyusha
29.07.2021 13:14+1— Здравствуйте, это робот Олег. Хотите взять кредит?
— Нет. Отстаньте.
— Вы всё врёте: вы хотите взять кредит! Согласно п. 5.6.4 раздел (д) параграф 7 по тембру вашего голоса акцепт договора кредитования от вас получен...
...
— Пожалуйста, после разговора помолчите немного в трубку. По вашему молчанию наш робот Олег определит, на как ещё услуги нашего банка вы даёте автоматическое согласие в будущем.

cahbe
29.07.2021 14:46Тех поддержка:
-Я ничего не нажимала оно само...
Там в 102% случаев врёт. Раз они такие молодцы может придумают переводчик с бухгалтерского "У меня тут это, а вчера было то, но в другом месте, и вы исправьте, а то ведь работать не возможно"

ss-nopol
Хорошо бы наоборот, мне как клиенту хотелось бы знать, говорит ли сотрудник коллцентра правду.
Andrey_Epifantsev
Сотрудник колл-центра идёт жёстко заданному алгоритму. Он говорит то, что ему велели говорить. Скорей всего он даже не знает, говорит ли он правду или неправду.
shushu
Ну тут как раз всё просто, если он не знает - то скорее всего он доверяет работодателю и верит что говорит правду. Алгоритм то определяет что говорящий говорит осознанную неправду! Даже если на самом деле эта неправда - правда :)
Всё относительно :)
awoland
shushu
т.е. вера не относится к категории признаков и параметров, опрелеяющих инстинность
shushu
Дык, алгоритм то не определяет истину/ложь. Алгоритм орюпределяет аномалии в речи, которые свойственны человеку, который говорит осознанную неправду.
BalinTomsk
Много раз сталкивался с тем что сотрудники коллцентра врут, при чем когда я ловил их на вранье они на ходу переобувались. Нельзя говорит что они всегда озвучивают по бумажке.
Элемент продажи морали там тоже бывает присутствует.