

В приложении ЦИАН размещены десятки тысяч объявлений о недвижимости. Нашим пользователям важно видеть географическое расположение этих объявлений на карте. Самым популярным способом отображения оказался вариант, когда каждое объявление показано отдельной точкой. Внутри команды такой вариант мы назвали «Горошек на карте».
Проблема в том, что объявлений очень много: в одной только Москве более 10 000. Из-за этого наша карта работала не очень стабильно: при зуме и движении были тормоза, дёргалась и лагала картинка. С этим нужно было что-то делать. Чтобы разобраться в причинах проблем и найти решения, мы засучили рукава и начали копаться в используемых механизмах. Под катом подробно опишем весь путь оптимизации карт в Android-приложении: от постановки задачи до результата.
1. Постановка задачи
Введение
Для начала давайте разберёмся, для чего был выбран именно такой метод отображения объявлений. Ведь можно применить кластеризацию и просто повесить над Москвой один огромный пин с циферкой 10 000 посередине. Так почему же мы в итоге остановились на варианте «одно объявление — одна точка»?
Это красиво.
Легко читается плотность объявлений в конкретном районе.
Все объявления на своих местах, и при масштабировании каждая точка остаётся на своём месте.

В качестве альтернативы мы также рассматривали решение с использованием тайлов. Это отдельный слой карты, состоящий из заранее подготовленных растровых картинок, на которых можно рисовать всё что угодно. Для нас это решение не подошло, так как пришлось бы отдельно генерировать изображения для пересечений каждого из 40+ фильтров друг с другом.
Как было реализовано
Для отображения у нас используются Яндекс.Карты. Общая логика работы выглядела следующим образом:
Пользователь заходит на карту либо перемещается по ней.
Когда камера останавливается, мобильное приложение запрашивает у сервера объявления в области видимости; для этого мы передаём координаты левого верхнего и правого нижнего углов.
Сервер с помощью ElasticSearch находит объявление в данной области и возвращает их мобильному приложению.
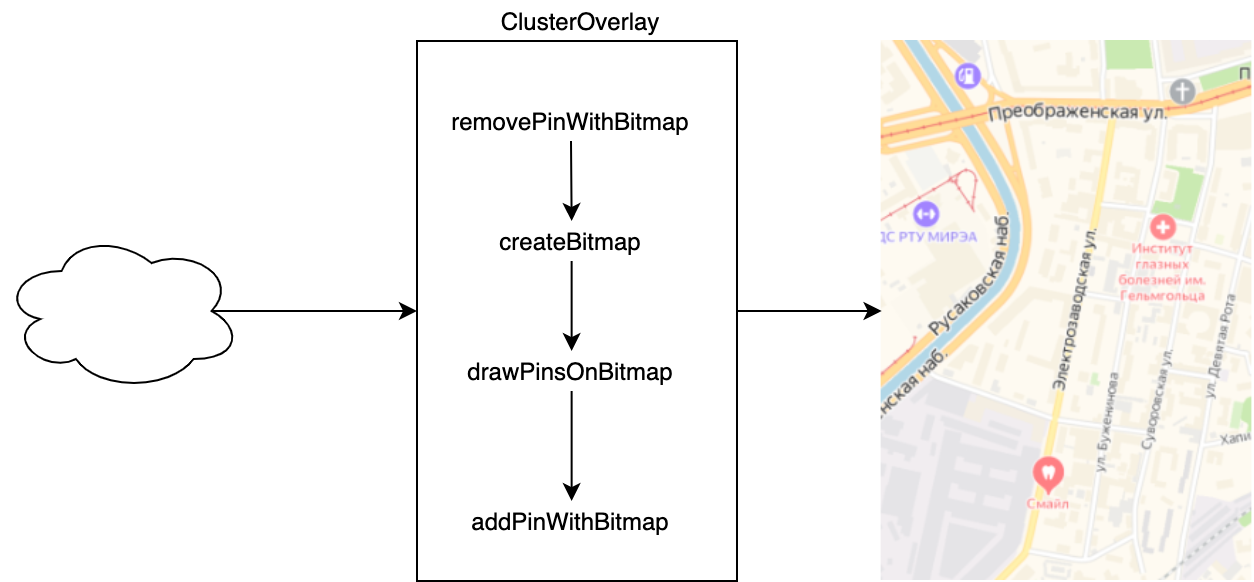
Переводим координаты объявления в позицию на экране.
Если на карте уже отображается пин Яндекс.Карт, то удаляем его.
Создаём Bitmap-картинку и через Canvas рисуем на ней точки объявлений в тех позициях, где они сейчас должны находиться.
В самом центре экрана добавляем пин Яндекс.Карт и в качестве картинки вставляем наш Bitmap с нарисованными на нём объявлениями.
Возвращаемся к шагу 1 и повторяем алгоритм, пока пользователь не уйдёт с карты.
Правда, тут есть нюанс: у Яндекс.Карт есть ограничение на размер вставляемой в пин картинки: 2048x2048. И если попытаться такую растровую картинку приблизить, то получится некрасиво:

Чтобы обойти это ограничение, после того как мы нарисовали объявления на большой Bitmap-картинке, мы делим её на четыре части. То есть разбиваем экран посередине на четыре области, каждая из которых отрисовывается на своём отдельном Bitmap.

Как это работало, мы разобрались. Теперь давайте посмотрим, что с этим подходом было не так.
Основные проблемы
С момента получения данных с сервера до отображения точек на карте проходит около секунды. Пользователю приходится долго ждать, чтобы увидеть объявления.
Точки «моргают» после появления на карте. Мы синхронно добавляем четыре пина, а вот под капотом Яндекс.Карт они добавляются уже асинхронно. Из-за это возникает эффект, когда сначала появляются объявления в правом нижнем углу, затем в левом верхнем и так далее. Всё это происходит достаточно быстро, и карта выглядит как новогодняя ёлка.
Карта тормозит и подлагивает при взаимодействии с ней.

Причины проблем
Вся работа с отрисовкой точек на карте у нас происходила в классе PeasFourBitmapOverlay. Метод отрисовки отрабатывал очень медленно: в среднем 800 миллисекунд на Xiaomi Mi A3.

Также у Яндекс.Карт очень много методов, которые должны выполняться на главном потоке. На это мы повлиять никак не можем. Поэтому погрузимся в код именно с нашей стороны.
Разберём подробнее логику работы PeasFourBitmapOverlay. По сути, в одном методе происходило следующее:
-
Сначала на главном потоке:
рассчитываем размер Bitmap-картинки;
конвертируем широту и долготу объявлений в точки на экране.
-
Переходим на фоновый поток:
создаём Bitmap;
рисуем на нём точки объявлений;
делим Bitmap на четыре куска.
-
Возвращаемся на главный поток:
убираем предыдущие пины;
рассчитываем ScaleFunction — это помогает Яндекс.Картам понять, насколько нужно увеличить или уменьшить Bitmap при зуме;
добавляем новые пины Яндекс.Карт с Bitmap в качестве изображения пина;
выставляем ScaleFunction.
Всё это происходит хоть и в многопоточном режиме, но синхронно.

Из описанного видно, что:
Следует разбить процесс на шаги.
Слишком много работы происходит в главном потоке, и только три действия — в фоновом.
Рисование занимает слишком много времени.
Выставление ScaleFunction тоже долгое: может занимать до 200 миллисекунд.
2. Решение
Создать конвейер
Что за конвейер? По сути это набор шагов, которые должны выполниться друг за другом; каждый из этих шагов изменяет или дополняет какой-то объект, который как бы движется по конвейеру. Отсюда и название. При этом результат следующих шагов зависит от предыдущих, например:
Рассчитываем размер Bitmap-картинки.
Конвертируем широту и долготу объявлений в точки на экране.
Создаём Bitmap; для этого нужны размеры из шага 1.
Рисуем на этом Bitmap точки объявлений; для этого Bitmap должен быть создан в шаге 3.
Делим Bitmap на четыре куска; для этого точки должны быть нарисованы в шаге 4.

Теперь перейдём к нашей реализации. Объектом, который будет двигаться по конвейеру, является ConveyorData. Это immutable-объект, содержащий всю информацию, которая может понадобиться любому из шагов. Под шаг конвейера сделали интерфейс ConveyorStep на Rx.
internal interface ConveyorStep {
fun step(conveyorData: ConveyorData): Single<ConveyorData>
}Метод step, по сути, является основным: в нём делается вся работа, предписанная конкретному шагу. Для этого в него передаётся ConveyorData, полученный от предыдущего шага, а сам метод возвращает Single от ConveyorData, который изменяет изначальный ConveyorData в результате работы шага.
Если хоть один из шагов отрабатывает с ошибкой, то весь результат работы конвейера сбрасывается, так как последующие шаги не смогут выполнить свою работу из-за недостатка данных.
Получается следующая схема работы:

Параллельный конвейер
Если очень пристально всматриваться в картинку выше, то можно заметить, что для создания шага «Создаём большой Bitmap» необходим только результат шага «Расчёт размера Bitmap», а вот результат «Конвертации геоточек в точки на экране» этому шагу не нужен. А значит, эти шаги можно выполнить параллельно друг другу: сразу после «Расчёта размера Bitmap» можно запустить «Создаём большой Bitmap», а «Конвертация геоточек в точки на экране» будет идти параллельно.

Вот и первые признаки оптимизации! За счёт того, что «Создаём большой Bitmap» делается в фоновом потоке, мы сможем выиграть немного времени. Правда, теперь придётся научить наш конвейер выполнять шаги параллельно.
Для работы с параллельным выполнением интерфейс ConveyorStep придётся немного усложнить. Добавляем метод isAvailable(); в нём шаг может проверить, достаточно ли у него данных для выполнения. Шаг вернёт true, если он готов выполнить свою работу.
За счёт этого частичное распараллеливание потоков происходит автоматически. В конвейер добавляется 10 параллельных шагов, и происходит проверка, может ли выполниться каждый из них. Если да — шаг выполняется; если нет — ждёт завершения предварительных шагов.
Только теперь появляется проблема: если несколько шагов у нас могут выполняться параллельно, а ConveyorData является immutable, то как потом объединить результат их усилий? Ведь каждый шаг работает со своим экземпляром ConveyorData. Конечно, можно сделать объект mutable и передавать одну и ту же ссылку во все шаги, но это очень опасно. Так как мы не знаем, что делает отдельный шаг в конкретный момент времени, может возникнуть ситуация, когда несколько шагов одновременно используют и изменяют один и тот же набор данных. Самым простым и быстрым, но далеко не самым лучшим способом является добавление метода merge() в наш интерфейс. В нём мы будем объединять ConveyorData в один объект, после того как доступные (isAvailable == true) шаги закончат свою работу.
В итоге наш ConveyorStep выглядит следующим образом:
internal interface ConveyorStep {
fun isAvailable(conveyorData: ConveyorData): Boolean
fun step(conveyorData: ConveyorData): Single<ConveyorData>
fun merge(original: ConveyorData, updated: ConveyorData): ConveyorData
}Как работает конвейер
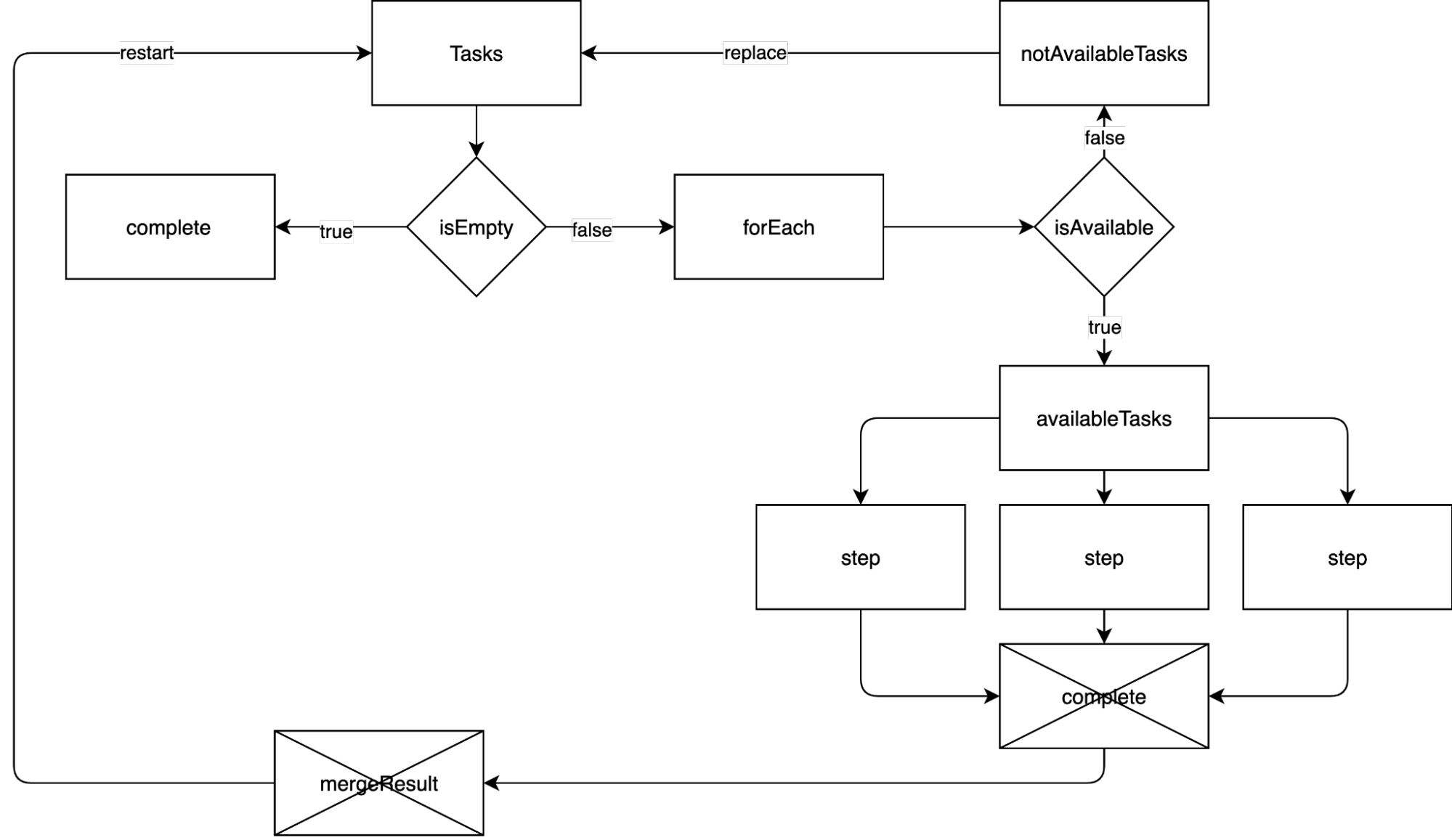
Давайте разберёмся, как теперь работает конвейер. Логика работы следующая:
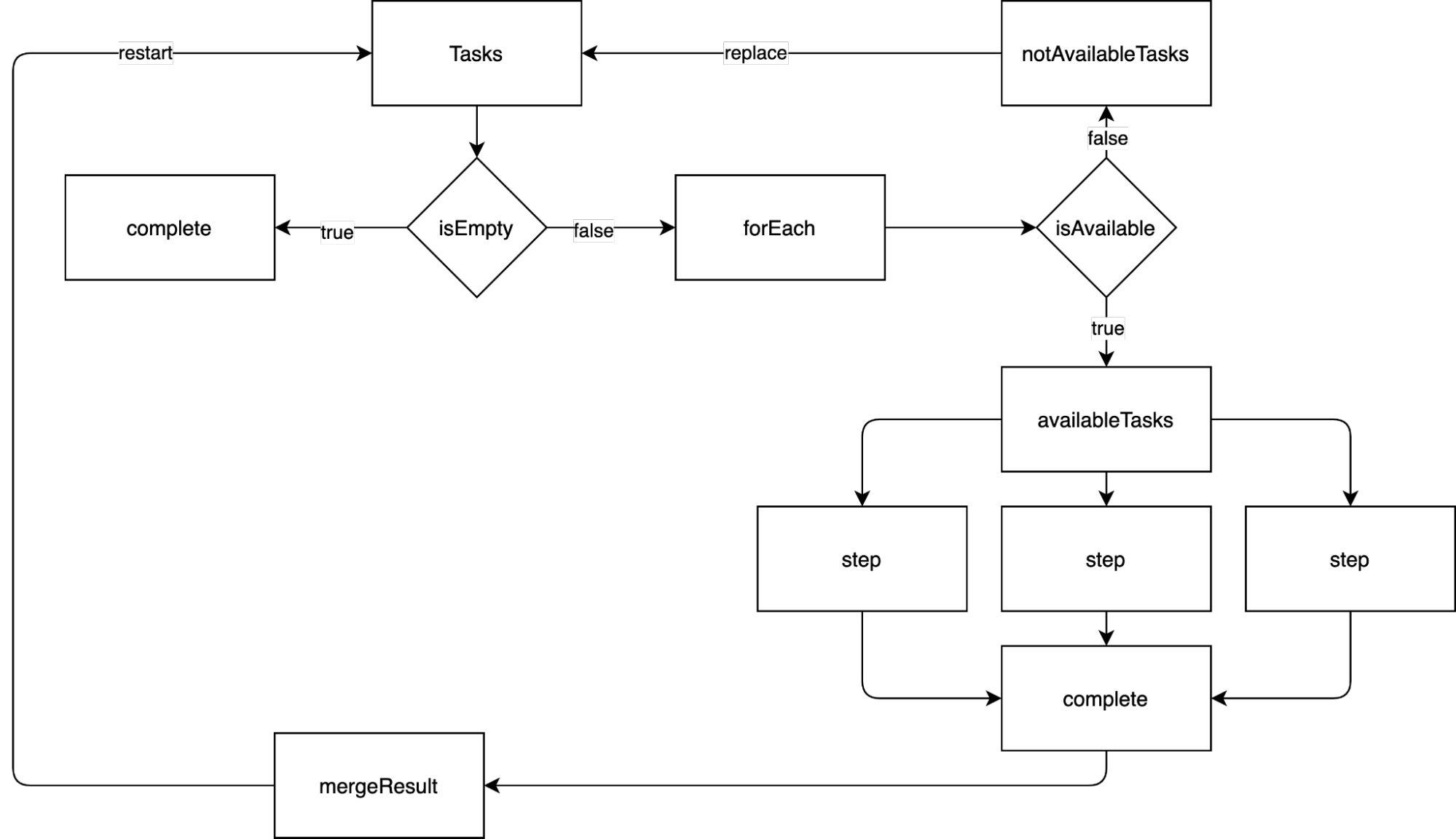
Есть список ещё не выполненных шагов (Tasks), и мы проверяем его содержание. Если список пустой, то это значит, что конвейер выполнил свою работу.
Если список не пустой, то у каждого шага в списке спрашиваем, доступен он или нет.
Недоступные шаги заменяют собой список ещё не выполненных шагов.
Доступные шаги начинают выполняться параллельно.
После выполнения всех доступных шагов объединяем их результат.
Возвращаемся в начало.
Шаги конвейера
Для нашей задачи в итоге получились следующие шаги:
CreatePlaceMarksStep — создание объектов Яндекс.Карт.
CalcBitmapSizeStep — расчёт размера Bitmap-картинки в зависимости от входных данных. Картинка должна быть качественной, но при этом её размер не должен превышать 4096x4096 и не должен быть кратно больше, чем разрешение экрана.
CalcScreenPointsStep — конвертация расположения объявлений из географических координат в координаты положения точек на экране устройства.
CreateBitmapsStep — создание итоговых Bitmap-картинок, которые будут передаваться на отрисовку карте.
CalcScaleFunctionStep — расчёт функции масштабирования в зависимости от зума.
CalcDrawDataStep — нахождение центра экрана в географических координатах для пинов Яндекс.Карт, а также расчёт смещения картинки пина относительно его центра.
SetWorldPointStep — изменение местоположения пина на карте.
DrawStep — замена картинки у пина.
SetScaleFunctionStep — установка функции масштабирования в зависимости от зума.
ShowPlaceMarksStep — отображение новых пинов.
HidePlaceMarksStep — скрытие предыдущих отображённых пинов.
В итоге получился параллельный конвейер, где в главном потоке мы создаём объекты карты, а затем параллельно выполняем большую часть шагов. Потом снова возвращаемся на главный поток и запускаем шаги, которые требуется выполнить последовательно: скрываем старые пины и затем показываем новые, чтобы они друг на друга не наложились. Синхронность в конце помогает решить проблему с «морганием».
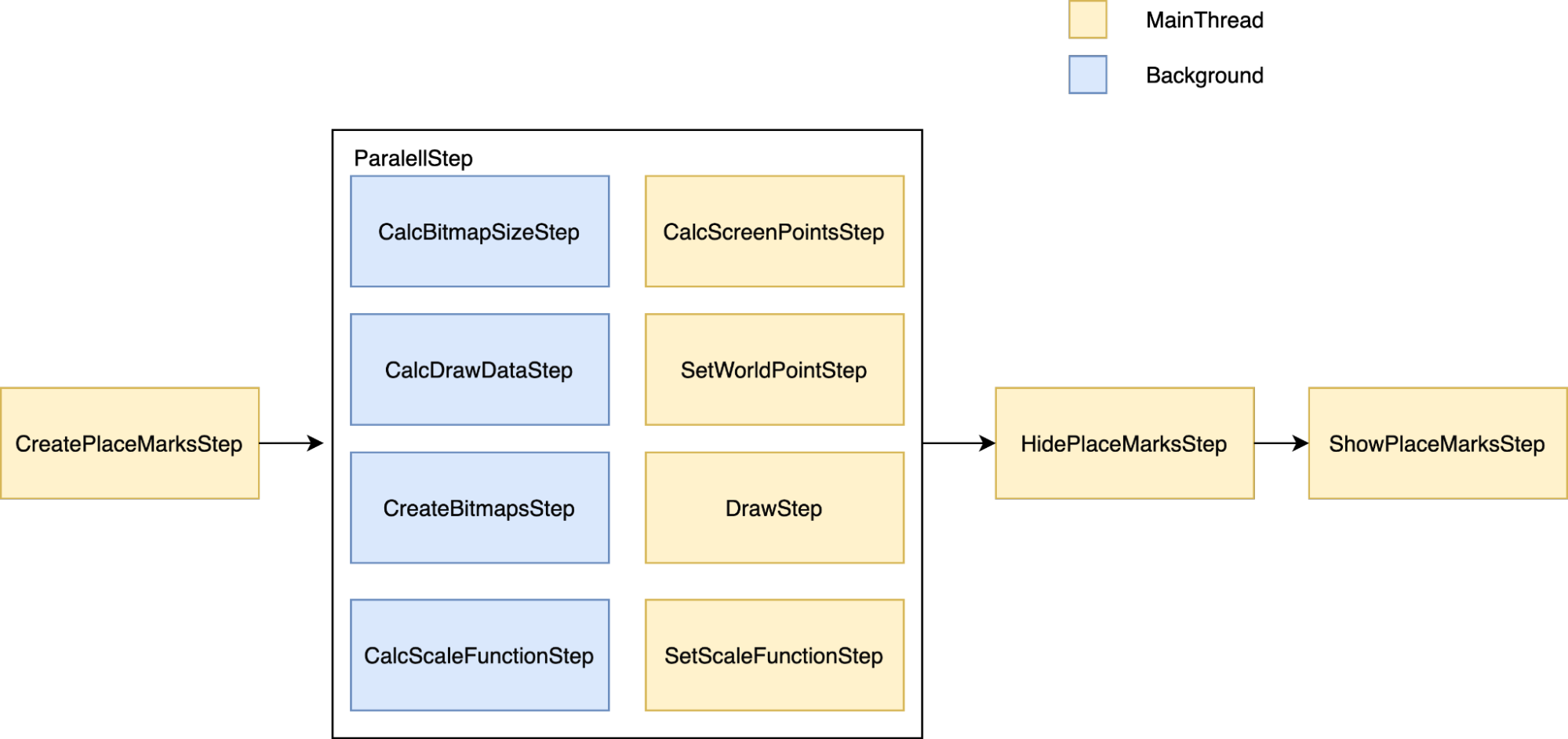
Конвейер из конвейеров
Важной особенностью конвейерного подхода является то, что его легко масштабировать. Можно сделать разные конвейеры для разных ситуаций (например, если пользователь подвигал карту или приблизил/отдалил). Что это даст? При зуме можно использовать красивую анимацию, которая не нужна при движении. Для этого после создания объектов карты проверяем, изменился ли зум, и в зависимости от этого фактора запускаем разный набор шагов.

Оптимизировали MainThread
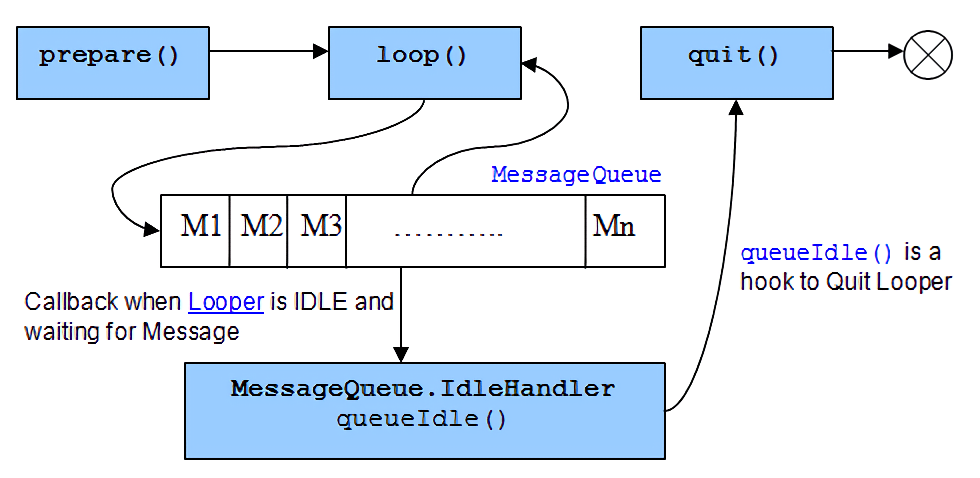
Как можно заметить, в главном потоке всё ещё выполняется большое количество действий. Это вынужденная мера, так как все эти шаги взаимодействуют с Яндекс.Картами, а они, в свою очередь, требуют обращения именно в главном потоке. Так что же, получается, лаги останутся и ничего не исправить? На самом деле после разбиения на шаги проблем уже стало ощутимо меньше. Чтобы понять, почему так происходит, давайте посмотрим, как происходила отрисовка раньше.
Представим, что у нас экран с частотой обновления 60 Гц, — а это значит, что каждые 16 миллисекунд RenderThread отрисовывает результаты работы нашего потока. Ранее все действия выполнялись в одном методе — а значит в одном сообщении Looper главного потока — следовательно, следующий кадр не рисовался, пока работа этого метода не завершится. Выглядело это примерно так (красным отмечены кадры, которые должны были отрисоваться, но не смогли из-за долгого выполнения метода):

Теперь же мы вынесли каждый шаг в отдельное сообщение главного потока — а значит, после выполнения какого-либо шага RenderThread уже может рисовать следующий кадр, что избавляет от лагов. По сути, мы разбили огромную работу в главном потоке на маленькие кусочки, которые успевают отрабатывать, пока рисуется кадр, или немного залезают на соседние — в результате лаги сильно сократились.

Серьёзная проблема остаётся только с SetScaleFunctionStep, но с ней придется разбираться отдельно. Далее все остальные оптимизации касаются отдельных шагов.
Закешировали объекты Яндекс.Карт
В первом шаге CreatePlaceMarksStep вместо пересоздания пинов Яндекс.Карт мы теперь сохраняем их в двух кешах — текущие пины и предыдущие — которые меняем местами с каждым приходом новых данных. Два кеша вместо одного нужны, чтобы мы могли одновременно показывать анимации появления и исчезновения пинов; с одним набором кеша такое не провернуть. Таким образом экономим время в обмен на оперативную память.

Натянули цилиндр на сферу/эллипсоид
Шаг CalcScreenPointsStep, который переводит координаты объявлений из координат (lat, lon) в координаты пикселя на экране, тоже занимает много времени и не всегда успевает выполниться за 16 миллисекунд. Ведь даже очень простое действие может затянуться, если повторять его для более чем тысячи объявлений.
Кажется, что тут должна быть простая математическая операция перевода координат, так в чём же проблема? В том, что Земля сферическая (точнее, эллипсоидная), а карты квадратные, по сути являющиеся цилиндром. Для того чтобы превратить сферу в цилиндр, используется проекция Меркатора.
Превращение из сферы в цилиндр идёт по формуле:

Так делают Google Maps.
А вот превращение из эллипсоида в цилиндр уже происходит по сложной формуле:
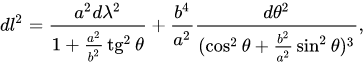
И в Яндекс.Картах как раз используют эллипсоид, что, как видно, делает нашу задачу заметно сложнее.
В процессе поиска решения мы рассматривали три варианта этого шага:
CalcScreenPointsAccuracyStep — считает максимально точно, но долго.
CalcScreenPointsMediumStep — считает неточно, но быстрее.
CalcScreenPointsFastStep — самый быстрый способ, но с погрешностью в 2–3 пикселя.
CalcScreenPointsAccuracyStep
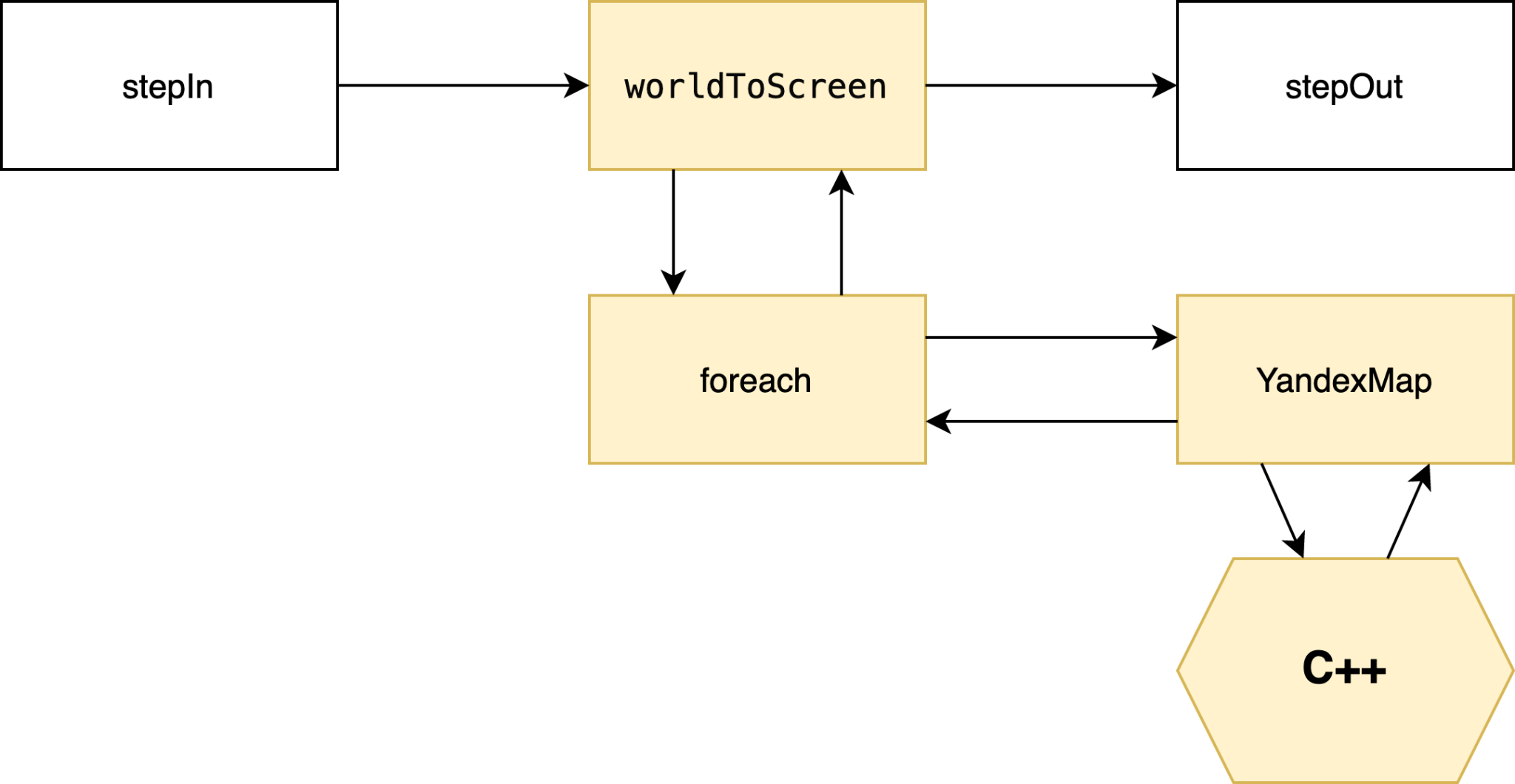
В API Яндекс.Карт есть метод worldToScreen — в него можно передать координаты объявления и получить координаты на экране в пикселях. Но он может быть вызван только в главном потоке; в итоге для большого количества точек требуется много времени главного потока, что вызывает лаги.
CalcScreenPointsMediumStep

Помимо worldToScreen, в API Яндекс.Карт есть класс Projection — он делает за нас часть работы, переводя широту и долготу в x и y на карте, и, что самое прекрасное, не требует главного потока. Нам же остаётся определить координаты видимой на экране части карты. Дальше рассчитать положение точки на экране — это дело техники.
Звучит очень красиво, но есть один нюанс. В классе Projection точки передаются по одной, и для каждой требуется отдельный вызов C++-метода.
Прямой вызов невиртуального метода занимает 25 наносекунд. Если метод виртуальный — то уже 50 наносекунд. Кроме того, метод вызывается из Java в С++ — в итоге вызов занимает 225 наносекунд, то есть в 4,5 раза больше.

При этом отдельный вызов приходится делать для каждого из объявлений на карте, а их в нашем случае может быть до 10 000. Простые расчёты показывают, что только лишь на вызовы методов, не считая времени их выполнения, мы можем потратить 2,25 миллисекунды, что составляет ⅛ всего времени, что у нас есть. В итоге этот шаг хоть и быстрее предыдущего, но всё же ещё далёк от оптимального варианта.
CalcScreenPointsFastStep
Пробуем вычислять сами в Java-коде, быстро и с погрешностью. Для этого нам нужны три точки: верхний левый угол, нижний правый угол и вычисляемая точка. Определяем, на какой относительной высоте и ширине находится точка (например, в 60 % от ширины и 20 % от высоты), и ставим её в соответствующее место. Таким образом мы просто игнорируем проекцию Меркатора и считаем без неё — в итоге появляется погрешность. И чем сильнее отдаление, тем она больше, так что этот метод подходит только при достаточно большом приближении карты.
Итоговый CalcScreenPointsStep

Из трёх описанных вариантов шагов конвертации мы выбрали CalcScreenPointsMediumStep с использованием кеша. Если x- и y-точки на карте уже вычислялись ранее, то берём результаты вычислений из кеша и экономим время на отказе от вызова C++-метода.
Сгладили пин
Всё ещё помните квадратные точки из начала статьи? Изначально мы исправили их увеличением разрешения, но есть ещё один способ — использовать сглаживание. Для этого при рисовании точки нужно выставить в классе Paint соответствующий флаг isAntiAlias как true. И хотя при большом приближении круг выглядит не лучше, чем раньше, при отдалении, когда точек тысячи, они смотрятся нормально.
При десятикратном увеличении:

То же самое, но в нормальном размере:

Это позволяет немного уменьшить разрешение Bitmap, сохраняя качество и вместе с тем повысив производительность шагов, связанных с рисованием на Bitmap и работой с пином Яндекс.Карт.
Раз уж мы заговорили о рисовании, то хочется обсудить ещё один момент. Раньше у нас каждая точка на Bitmap рисовалась с помощью отдельного вызова drawCircle у Canvas. Такой метод не вполне оптимален, так как каждый раз идёт процесс растеризации — превращение круга в набор пикселей. Это довольно затратная операция, даже учитывая малое разрешение отдельной точки.
Более производительным решением является использование спрайтов. Мы просто создаём отдельный Bitmap, на котором рисуем точку; такой Bitmap и будет являться нашим спрайтом.
Затем вызываем метод drawBitmap у Canvas и передаём в него координаты и наш спрайт. Bitmap является простой матрицей. Ускорение достигается за счет того, что при отрисовке на нём другого Bitmap произойдёт перемножение матриц, а это достаточно дешёвая математическая операция.

Оптимизировали масштабирование
Шаг SetScaleFunctionStep нужен для корректного масштабирования Bitmap при зуме. По умолчанию изображение в пине Яндекс.Карт при зуме вообще не изменяется; в нашем же случае при приближении карты Bitmap тоже должен увеличиться, чтобы объявления остались на своих местах. Для этого мы можем указать, какого размера должен быть Bitmap на конкретном уровне приближения. Сам расчёт — дело несложное. Проблема в том, что выставление этой функции для пина Яндекс.Карт занимает много времени, и при этом оно должно быть выполнено на главном потоке. Избежать этого или оптимизировать процесс никак нельзя. Но если призадуматься, то можно понять, что эта задача не является срочной, — а значит, можно использовать IdleHandler, чтобы избежать части видимых лагов.
Когда в главном потоке ничего не происходит из-за отсутствия задач, начинается idle-время, и можно подсунуть нашу задачу с помощью IdleHandler. То есть SetScaleFunctionStep выполнится в тот момент, когда на главном потоке ничего не будет происходить, а значит, прочие действия не будут задерживаться из-за долгого исполнения этого шага, и визуальных задержек не случится.
Оптимизировали стили
В Яндекс.Картах есть возможность убирать с карты часть элементов, например светофоры и прочие объекты, которые могут быть не очень важны при выборе квартиры.

3. Заключение
Это все основные оптимизации, которые мы применили. В целом мы достигли результата, который нас устроил, хотя тут ещё, конечно, поле непаханное для дальнейших оптимизаций.
А теперь давайте оценим результат всех наших доработок.
Для сравнения посмотрим, как было:
И как стало теперь:
Что ещё можно оптимизировать?
Напоследок хотелось бы пофантазировать, что ещё можно было бы улучшить, если когда-либо нам понадобится дальнейшая оптимизация.
Запрашивать точки большей области.
Можно запрашивать точки за пределами области, отображённой на экране. Тогда при движении карты граница области, для которой загружены объявления, будет появляться не так резко.
Попытаться предсказать действия пользователя.
Многие действия на карте являются довольно предсказуемыми. Например, если пользователь несколько раз приблизил карту к определенному району, скорее всего, он продолжит приближение, а значит, где-то в фоновом потоке можно попробовать начать готовить данные. Но в целом это оптимизация из разряда фантазий.

Кешировать точки, полученные с бэкенда.
Можно складывать все полученные от сервера объявления в базу, и если пользователь уже просматривал данную область, то и на сервер ходить незачем.

Готовые расчёты с сервера.
Что-то из области Backend-Driven UI. Сервер может возвращать уже готовые расчёты под область экрана — в итоге половину шагов можно будет выкинуть.

Улучшить ParallelStep.
Сейчас конвейер дожидается выполнения доступных шагов и только потом приступает к следующим. Но лучше сразу после завершения шага объединять его результат с остальными данными и проверять доступность шагов.
Комментарии (18)

fransua
09.09.2021 13:50Вы разбиваете экран на 4 части, а можно попробовать разбивать по границам тайлов и рисовать каждый из них отдельно. Тогда при смещении нужно будет только по краям прямоугольника дорисовать немного.
Координаты меркатора можно 1 раз посчитать для каждого дома и сохранить в эластик.
А в вебе оно также устроено, рисуется на канвасе в отдельном потоке?

princeparadoxes Автор
09.09.2021 14:38+1Тут на самом деле очень много способов как сделать лучше)
На вебе у нас, насколько мне известно, используется кластеризация, а не "одно объявление - одна точка".

sse
09.09.2021 14:18+2Очень понравилось изложение, спасибо большое, по сути - самодельный event loop. А что думаете о переносе большей части логики в NDK?
princeparadoxes Автор
09.09.2021 14:32О переносе в NDK думали вскользь. У нас в приложении кроме этих расчетов особо и нечего выносить в NDK, а ради сотни строк перенастраивать сборку, CI парится с объяснениями работы JNI и С++ тоже не очень хочется. Нам проще эти расчеты тогда на бэкенд утащить

movl
10.09.2021 03:02Что-то может не до конца понимаю специфику задачи и андройда, но не проще ли было просто разбивать массив точек на отдельные чанки, и параллельно рисовать в шаренную память? Да и различные граничные значение, если они необходимы можно точно также искать.
princeparadoxes Автор
10.09.2021 17:51Не до конца понял про "параллельно рисовать в шаренную память". Тут проблема не только и не столько в рисовании, а в том как потом добавить это на карту.
Пробовали например вместо 4 объектов с большими Bitmap добавлять на карту 16-32-64 объекта на карту с Bitmap меньшего размера. Но по производительности получалось хуже.

Ztare
10.09.2021 11:44А почему координаты точек не передавать в виде бинарного блоба и рендеринг тайлов не вынести в мобилу? Выглядит что для мобилы это должна быть типовая задача
princeparadoxes Автор
10.09.2021 17:47+1Да, я в заключении предложил получать координаты с сервера как развитие оптимизации. В бинарном виде действительно может быть наилучшим вариантом.
А по поводу рендеринга тайлов на мобиле - мы пробовали и визуально нам это меньше понравилось, поэтому развивали наш текущий подход
Вот пример из экспериментов тайлами
https://youtu.be/39_qCY_ij9Y

black_list_man
10.09.2021 17:52Почему-то прочитав заголовок, подумал что речь пойдет об OpenGL.
Не знаю позволяет ли yandex api создавать пользовательские слои, но если бы я думал о решении данной задачи, то в первую очередь смотрел бы в сторону собственного слоя с OpenGL контекстом.
Для рендеринга сглаженного круга достаточно нарисовать прямоугольник, все остальное сделает специальный фрагментный шейдер. В том числе сразу с обводкой. Чтобы не было 100к вызовов отрисовки, батчим все прямоугольники в один буфер и рисуем всю сцену за 1 вызов.
Если же использовать современный OpenGL ES c (AEP) и поддержкой геометрических шейдеров, то для каждой метки достаточно добавить в буфер одну вершину, причем без проекции, а проекцию координат и создание прямоугольника доверить геометрическому шейдеру.
princeparadoxes Автор
10.09.2021 17:57+2У Яндекс.Карты есть возможность добавлять свои слои, но там весьма ограниченный набор функций и к сожалению возможности работать с OpenGL напрямую там нет.
https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/layers/package-summary.html
В целом бы конечно свой слой с OpenGL по сути решил бы многие проблемы)
akhmelev
14.09.2021 09:34Просто мысль. Может тогда в самом приложении можно повесить прозрачный слой с OpenGL над вьюшкой с картами? Нижний идёт к Яндексу, верхний на ваш rest к базе. Андроид толком не знаю, но представляется маловероятным, что это невозможно.
Кроссплатформенность конечно улетит в даль далёкую и для браузера/айфона будет(ут) уже другое(ие) решение(я). Поэтому бек скорее всего не сильно полегчает. Но на войне как на войне, оптимизации - это почти всегда адский ад, зоопарк и раздутый код.

lim14
15.09.2021 16:29Можно еще попробовать сделать оптимизацию точек. Чтобы при изменении масштаба карты масштаб точек тоже изменялся, не дожидаясь подгрузки нового масштаба карты и других данных
Nihiroz
А не рассматривали вариант использования других карт? Ну или хотя бы движка карт. Часто они взаимозаменяемые за счет того, что можно движку предоставить свой доставщик тайлов
princeparadoxes Автор
Рассматривали, но у большинства альтернатив есть проблемы с детализацией в регионах, особенно если город не является областным центром. Тоесть в Москве, Казани, Екатеринбурге все хорошо, а например в Калачинске в Омской области уже могут отсутствовать многие дома, дороги или пятиэтажки отмечены как частные дома.
Яндекс.Карты в плане детализации в нашей стране все-таки впереди всех. Поэтому пытались "притереться" именно к ним
Nihiroz
А яндекс не умеет возвращать тайлы? Их можно было бы вставлять в довольно низкоуровневый OSMDroid
Nihiroz
К тому же на этих тайлах можно было бы сразу и точки рисовать
princeparadoxes Автор
Да, на тайлы смотрели.
"В качестве альтернативы мы также рассматривали решение с использованием тайлов. Это отдельный слой карты, состоящий из заранее подготовленных растровых картинок, на которых можно рисовать всё что угодно. Для нас это решение не подошло, так как пришлось бы отдельно генерировать изображения для пересечений каждого из 40+ фильтров друг с другом."
Поэтому на бэкенде их готовить не очень удобно.
Если говорить про генерацию изображения для тайла уже в приложении, то в итоге качество изображения получалось сильно хуже чем с таким подходом, при одинаковом выделении оперативы под Bitmap'ки.
Не знаю получится ли нормально объяснить текстом, но общая суть в том, что может быть виден лишь небольшой уголок тайла, при этом мы должны создать Bitmap под всю его площадь. При этом если попытатся вставить в тайл изображение с высоким разрешением, то при подгрузке тайла случался лаг.
В целом я думаю эти проблемы можно побороть если сильно постараться.
Для нас проблема использования тайлов скорее в том, что при изменении зума они довольно резко и непоследовательно подгружаются самой картой. Выглядит очень похоже как у нас было до оптимизации. Чисто визуально наш подход нам больше понравился.
JediPhilosopher
Решали похожую задачу по отображению генплана города-миллионника, с несколькими сотнями тысяч объектов (в основном полигональных и линейных, всякие земельные участки, территориальные зоны и т.п. ), плюс у нас там были фильтры, тоже несколько десятков.
В принципе генерация тайлов на сервере оказалась вполне рабочим решением. Да, такие тайлы не получится эффективно кешировать, так как слишком много вариантов фильтров, но мы их просто без кеширования на лету генерировали, и получалось быстро. Правда, при условии быстрого доступа к объектам. У нас они лежали в памяти сервера в квадродереве, без БД. На генплан города-миллионника в принципе нам хватало памяти обычного недорогого сервера.
Оказалось что это простое лобовое решение хорошо работает. При этом у тайлов есть плюс - они грузятся по кусочкам и человек сразу видит прогресс загрузки - тут прогрузились, тут, тут - можно сразу начинать смотреть и не ждать, пока загрузится один большой запрос на выборку всех объектов в поле видимости, например.
Не знаю, сколько у вас там объявлений, но вряд ли больше чем кадастровых участков в городе.