
В первой части статьи мы рассматривали основы теории компиляции C и C++ проектов, в частности особое внимание уделили алгоритмам компоновки и оптимизациям. Во второй части мы погрузимся глубже и покажем ещё одно применение межмодульного анализа. Но в этот раз не для оптимизаций исходного кода, а для улучшения качества статического анализа на примере PVS-Studio.

Статический анализ
По своей сути большинство статических анализаторов, в том числе и PVS-Studio представляют собой frontend компилятора. Для разбора кода строится схожая модель и применяются те же алгоритмы обхода. Поэтому в этой части статьи будет приведено много терминов из области теории компиляции. Многие из них разобраны в первой части, поэтому приглашаю вас прочитать её, если вы это ещё не сделали.
Межмодульный анализ уже давно успешно реализован и функционирует в ядре анализатора для C#. Это возможно благодаря инфраструктуре, которую предоставляет платформа Roslyn.
Когда же только начиналась разработка межмодульного анализа для C и C++, мы столкнулись с рядом проблем, мешающих реализовать механизм. Хочется поделиться интересными решениями, которые мы применили.
Первая проблема связана с архитектурой нашего анализатора, которая, естественно, не была готова к такому. Рассмотрим следующую схему:

Анализатор выполняет синтаксический и семантический разбор текста программы и затем применяет диагностические правила. Проблема заключается в том, что трансляция и семантический анализ, в частности анализ потока данных, осуществляется за один проход. Такой подход позволяет экономить память и хорошо работает.
Это работает до тех пор, пока анализу не требуется заглядывать вперёд. В таком случае приходится заранее собрать артефакты анализа и обработать их после трансляции. И это, к сожалению, добавляет накладные расходы по памяти и увеличивает сложность алгоритма. Причиной тому стал наш легаси код, который пришлось поддерживать и адаптировать под нужды статического анализа. В будущем мы очень хотим переработать эту часть. Тем не менее, пока перед нами не стояла задача реализации межмодульного анализа, это не вызывало существенных проблем.
В качестве примера рассмотрим следующий рисунок:
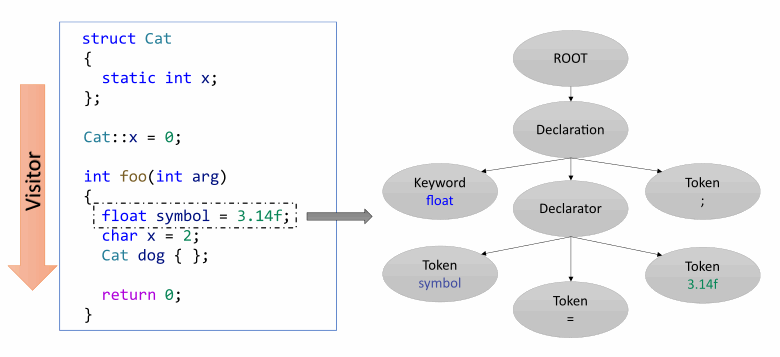
Предположим, анализатор строит внутреннее представление для транслируемой функции foo. Для неё последовательно по инструкциям строится дерево разбора, которое будет уничтожено, когда анализатор выйдет из контекста единицы трансляции. Если нам потребуется снова исследовать тело последней, придётся снова транслировать её и все символы, которые в ней используются. Что не очень эффективно по производительности. Причём в режиме межмодульного анализа может потребоваться перетранслировать множество функций в разных файлах.
Первый вариант решить эту проблему – сохранить промежуточные результаты разбора кода в файлы, чтобы потом можно было их использовать повторно. При таком подходе нам не придётся множество раз транслировать один и тот же код, что намного быстрее и удобнее. Но тут есть одна проблема. Внутреннее представление кода программы в памяти анализатора может отличаться от исходника. Некоторые незначительные для анализа фрагменты могут удаляться или модифицироваться. Поэтому не представляется возможным связать представление с исходным файлом. Кроме того, есть сложности с сохранением данных семантического анализа (data flow, символьные вычисления и т. д.), которые хранятся только в контексте блока, где они собраны. Поэтому компиляторы, как правило, преобразуют исходный код программы в обособленное от языкового контекста промежуточное представление (так точно делают GCC и Clang). Часто его можно представить в виде отдельного языка со своей грамматикой.
Это хорошее решение. Над таким представлением проще выполнять семантический анализ, так как в нём имеется достаточно ограниченный набор операций над памятью. Например, в LLVM IR сразу понятно, когда происходит чтение или запись в стековую память. Это происходит с помощью инструкций load/store. Но, в нашем случае реализация промежуточного представления потребует серьёзных изменений в архитектуре анализатора. Это заняло бы слишком много времени, которого у нас не было.
Второй вариант – запустить семантический анализ (без применения диагностических правил) на всех файлах и собрать информацию заранее. После чего в каком-то виде сохранить её, чтобы использовать на втором проходе. Такой подход потребует доработки архитектуры, но его возможно реализовать в разумные сроки. Кроме того, у него есть и свои плюсы:
глубина анализа регулируется количеством проходов. Это избавляет нас от необходимости следить за зацикливаниями. Дальше по тексту будет подробнее рассказано об этом. Отмечу, что на момент написания статьи в своей реализации мы ограничились одним анализирующим проходом;
процесс анализа хорошо распараллеливается, ведь у нас нет общих данных на первом прогоне;
существует возможность заранее подготовить модуль с семантической информацией для сторонней библиотеки при наличии её исходного кода и подкачать его вместе с ней. Но, пока что это только в планах.
При такой реализации нам потребовалось как-то сохранять информацию о символах. И тут становится понятно, к чему я столько о них расписывал в первой части. По сути, нам пришлось написать свой компоновщик, только вместо слияния объектного кода он занимается объединением результатов семантического анализа. Несмотря на то, что работает он проще, чем в компиляторах, алгоритмы, которые в них применяются, в нашем случае подошли как нельзя кстати.
Семантический анализ
Отдохнём немного от размышлений и перейдём к анализу семантики. В процессе того, как обходится исходный код программы, также собирается информация о типах и символах.

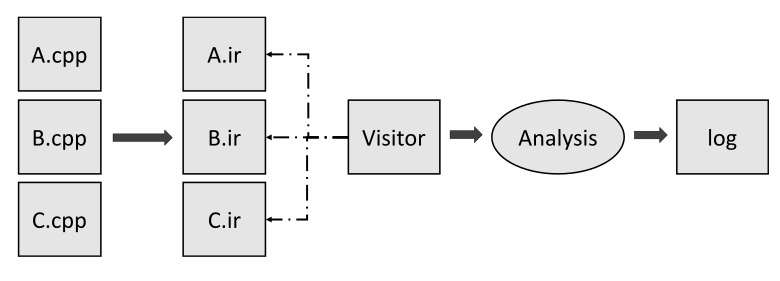
Помимо общей информации также собираются расположения всех объявлений. Эти факты нужно сохранять между модулями для того, чтобы выводить потом сообщения в диагностических правилах. Вместе с этим производятся символьные вычисления и анализ потока данных. Результат записывается в виде фактов, связанных с символами. В качестве примера рассмотрим рисунок:

В функции check происходит разыменование указателя, который, к тому же, не был проверен. Анализатор может запомнить это. Далее в функции bad тоже без проверки в неё передаётся nullptr. В этом месте уже точно можно выдавать предупреждение о разыменовании нулевого указателя.
Идея реализации как межпроцедурного, так и межмодульного анализа заключается в том, чтобы сохранять в таблицу вместе с символами и семантические факты – набор выводов, которые сделал анализатор в процессе рассмотрения кода.
Data Flow Object
Мы подходим к самому интересному. Встречайте! Наш формат представления двоичных данных семантического анализа – Data Flow Object (.dfo).
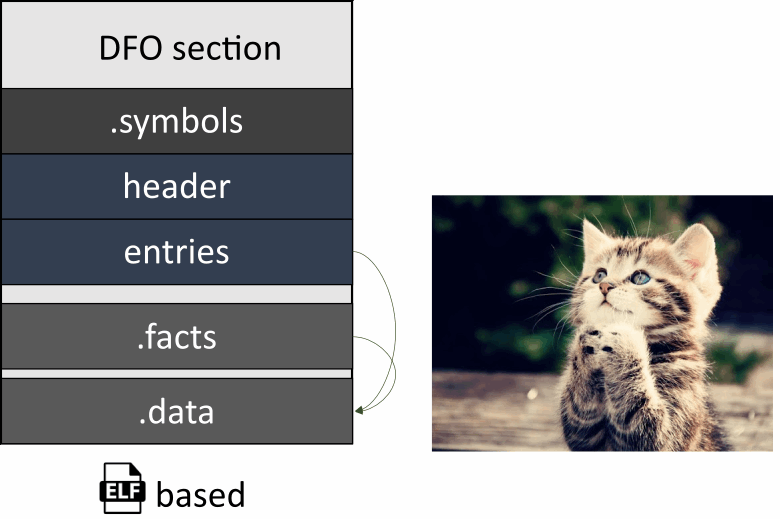
У нас стоит задача сохранять информацию о символах и данных для них в каждой единице трансляции. Пусть она хранится в соответствующих файлах в специальном формате. Однако, чтобы её потом использовать, нужно объединить их в один для дальнейшей загрузки на втором проходе.

Напоминает компоновщик, не так ли? Поэтому мы не стали изобретать велосипед, и сделали наш формат DFO похожим на ELF. Предлагаю взглянуть на него детальнее.
Файл разбит на секции: DFO section, .symbol, .facts и .data.
В DFO section находится вспомогательная информация:
Magic – идентификатор формата;
Version – понятно из названия;
Section offset – адрес начала секций;
Flags – вспомогательный флаг. Пока не используется;
Section count – количество секций.
Далее идёт секция с символами.
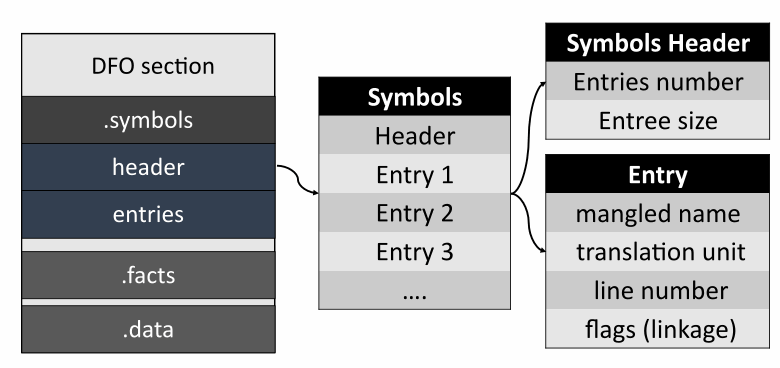
Header содержит информацию о количестве записей в таблице. Каждая такая запись содержит декорированное имя типа, расположение символа в файле с исходным кодом, информацию о типе связывания и storage duration.
И, наконец, секция с фактами.
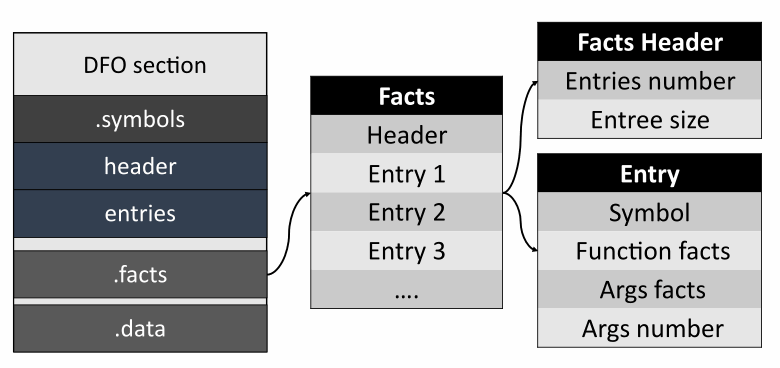
Как и в случае с символами, header содержит информацию о количестве записей, которые, в свою очередь, состоят из ссылок на символы, и различных фактов для них. Сами факты же закодированы как кортеж постоянной длины, что облегчает их чтение и запись. На момент написания статьи факты сохраняются только для функций и их аргументов. Мы пока что не сохраняем информацию о произведённых анализатором символьных вычислениях для возвращаемых значений функций.
В секции с данными находятся строки, на которые ссылаются другие записи в файле. Это позволяет сделать механизм интернирования данных для экономии памяти. Кроме того, все записи выравниваются ровно так же, как они хранятся в памяти в виде структур. Вычисляется выравнивание по простой формуле:
additionalBytes = (align - data.size() % align) % align
Например, если у нас в файле уже записаны данные в таком виде:

и мы хотим вставить туда число типа int.
Align(x) = alignof(decltype(x)) = 4 bytes
Size(x) = sizeof(x) = 4 bytes
data.size = 3 bytes
additionalBytes = (align - data.size() % align) % align =
= (4 - 3 % 4) % 4 = 1 byte;
Получаем сдвиг на 1 байт. Теперь можно вставить число.

Теперь рассмотрим подробнее этап объединения .dfo файлов в один. Анализатор последовательно загружает информацию из каждого и собирает в общую таблицу. Кроме того, как и компоновщику, анализатору приходится разрешать конфликты между символами с одним именем и сигнатурой. Схематично всё выглядит просто:
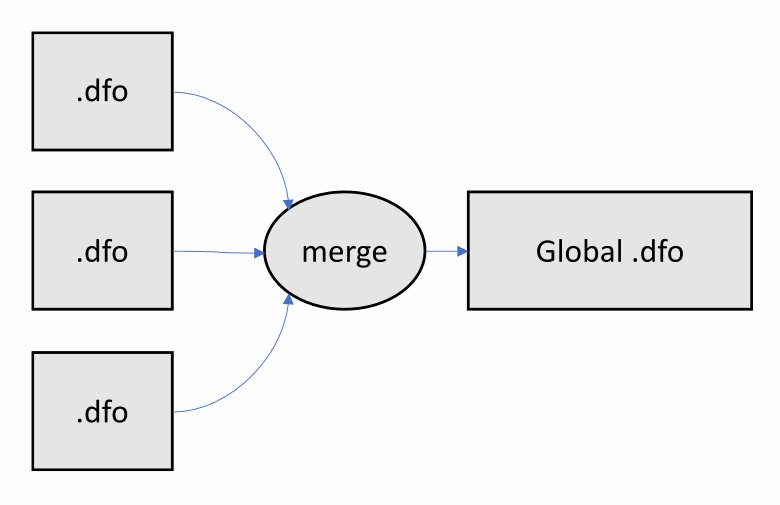
Однако есть несколько подводных камней.
Некоторое время назад мой коллега писал статью "30 лет ядру Linux: поздравление от PVS-Studio". По случаю предлагаю почитать – интересное вышло чтиво. После того как он запустил анализ ядра Linux, он получил общий .dfo файл размером в 30 ГБ! Когда мы стали выяснять, в чём дело, то обнаружили, что совершили ошибку. Несмотря на то, что к этому моменту мы уже умели определять категорию связывания символов, в общий .dfo файл мы записывали их все. Так было сделано для того, чтобы уточнить анализ в конкретных единицах трансляции, в которых эти символы определены. Рассмотрим картинку:

Как я уже писал выше, после того, как .dfo файлы сгенерированы для каждой единицы трансляции, они сливаются в один общий. Далее PVS-Studio использует только его и исходные файлы для дальнейшего анализа.
В нашем же случае при проверке ядра Linux символов с внутренним типом связывания оказалось на порядок больше, чем с внешним. Это и привело к такому большому объёму итогового .dfo файла. Решение напрашивается само собой. Объединять нужно только символы с внешним типом связывания на этапе слияния. А при анализе на втором проходе последовательно подгрузить 2 .dfo файла – объединённый и полученный после первого этапа. Это позволяет объединить все символы с внешним типом связывания, полученных после анализа всего проекта, и символы с внутренним типом связывания для конкретной единицы трансляции. Теперь, после доработки объем не превышает 200 МБ.

А что делать в случае, когда встречаются 2 символа с одинаковым именем и сигнатурой и один из них имеет внешний тип связывания? Налицо нарушение ODR. В компилируемой программе такого происходить не должно. Но у нас может произойти конфликт между символами, если на вход анализа попадут файлы, которые на самом деле не связываются. Например, CMake генерирует один общий compile_commands.json для всего проекта без учёта команд компоновщика. Подробнее я об этом напишу дальше. Благо, даже при нарушении ODR, если семантическая информация у символов совпадает, мы всё ещё можем продолжить анализ. В таком случае можно просто выбрать какой-то один из них. Если информация не совпадает, придётся убрать все символы с этой сигнатурой из таблицы. Тогда анализатор просто потеряет часть информации, но сможет продолжить работу. Например, такое может возникнуть при включении одного и того же файла в анализ несколько раз, при условии, что его содержимое меняется в зависимости от флагов компиляции (например, через #ifdef).
Глубокий анализ
Сразу отмечу, что на момент написания статьи эта функциональность ещё не реализована. Но мне хочется поделиться идеей, как это можно сделать. Возможно, она появится в следующих версиях, если мы не придумаем что-то получше.
Мы остановились на том, что умеем передавать информацию из одного файла в другой. Но как быть, если цепочка передачи данных длиннее? Рассмотрим пример:

Нулевой указатель передается через main -> f1 -> f2. Анализатор может запомнить, что в f1 передаётся указатель дальше, а в *f2 *происходит его разыменование. Но он не увидит, что в f2 через цепочку передаётся именно нулевой указатель. Для этого ему нужно сначала провести межмодульный анализ функции main и f1, чтобы понять, что указатель ptr нулевой. После чего еще раз проверить функции f1 и f2. При текущей реализации этого не произойдёт. Посмотрим на схему:
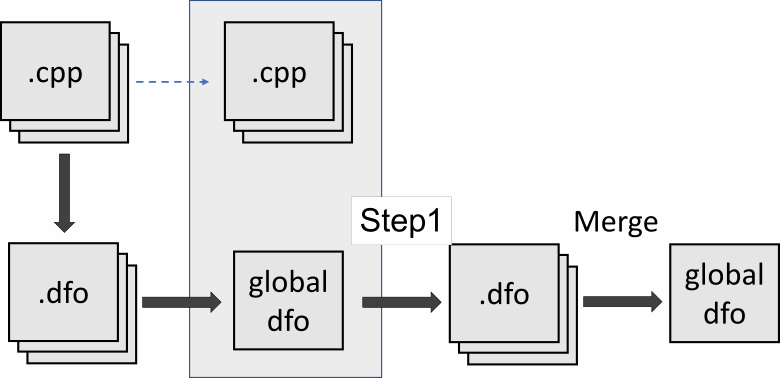
Мы видим, что после шага merge анализатор больше не имеет возможности продолжить межмодульный анализ. Это, конечно, минус нашего подхода. Ситуацию можно исправить, если отдельно ещё раз разобрать нужный нам файл, после чего выполнить слияние существующего суммарного .dfo файла и новой информации:

Вот только как понять, какие именно единицы трансляции повторно анализировать? Тут бы нам помог анализ внешних вызовов из функций. Для этого потребуется построить граф вызовов. Вот только у нас такого нет. Мы очень хотим его сделать в будущем, но на момент написания статьи такая функциональность отсутствует. Кроме того, как правило, внешних вызовов во всей программе достаточно много. И не факт, что это будет эффективно. Остаётся только повторно разобрать все единицы трансляции и перезаписать факты. Каждый такой проход увеличит глубину анализа на 1 функцию. Да, это долго. Но такие прогоны можно делать раз в неделю по выходным. Уже лучше, чем ничего. В будущем, когда мы сделаем промежуточное представление, эта проблема решится.
Тут мы закончили с внутренней частью функции межмодульного анализа. Однако есть несколько интересных моментов, связанных с интерфейсной частью. Так что предлагаю перейти от ядра анализатора к инструментам, которые его запускают.
Инкрементальный анализ
Представим ситуацию. Вы пишете проект, который уже проверен статическим анализатором. Вы не хотите каждый раз после изменения нескольких файлов перезапускать полный анализ. По аналогии с компиляцией у нас предусмотрена функция, которая запускает его только на измененных файлах. Можно ли сделать то же самое с межмодульным анализом? К сожалению, тут не всё так просто. Самый простой вариант – собрать информацию из изменённых файлов и объединить её с общей. После чего прогнать на них же анализ. При глубине анализа в единицу это даже сработает. Но мы потеряем ошибки в других файлах, которые могли быть вызваны новыми изменениями. Поэтому единственное, что тут можно оптимизировать, — это этап сбора семантических данных. Рассмотрим рисунок:
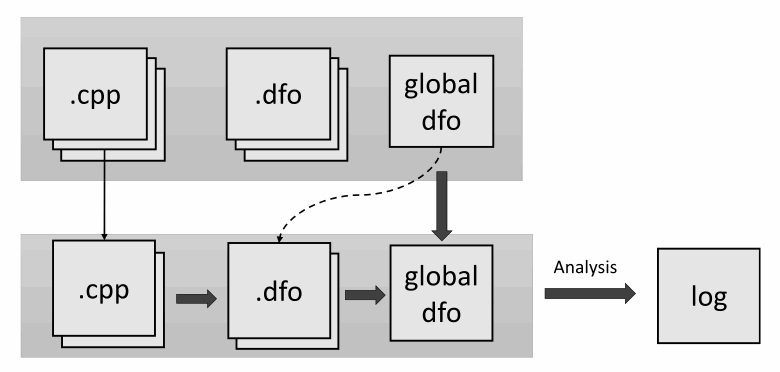
На первой строчке изображено состояние всего проекта. На нижней – тех файлов, которые были изменены. После чего:
производится генерация .dfo файлов для изменённых исходных файлов;
производится слияние полученных файлов с общим;
происходит полный анализ всех файлов проекта.
Анализ составных проектов
Чаще всего проект с исходным кодом программ состоит из нескольких частей. Причём в каждой может быть свой набор символов. Нередко случается ситуация, когда один и тот же файл связывается с несколькими из них. В таком случае ответственность за передачу правильных параметров компоновщику передаётся на программиста. Современные системы конфигурации и сборки проектов делают этот процесс относительно удобным. Но таких систем много, и не все из них позволяют отследить команды компиляции.
PVS-Studio поддерживает 2 формата проектов на C++ – Visual Studio (.vcxproj), JSON Compilation Database. В случае с первым из них всё хорошо. Формат предоставляет всю необходимую информацию для определения составных частей проекта. Но вот со вторым...
JSON Compilation Database (он же compile_commands.json) предназначен для инструментов анализа кода, таких как clangd, например. И до сих пор с ним проблем не было. Однако есть одно "но" – все команды компиляции в нём записаны в плоской структуре (одним списком). И, к сожалению, в них не включены команды для компоновщика. В случае когда один файл используется в нескольких составных частях проекта, команды для него будут записаны друг за другом без какой-либо дополнительной информации. Приведу пример. Для генерации compile_commands.json будем использовать CMake. Пусть у нас есть общий проект, и 2 его составных части:
// CMakeLists.txt
....
project(multilib)
....
add_library(lib1 A.cpp B.cpp)
add_library(lib2 B.cpp)
> cmake -DCMAKE_EXPORT_COMPILE_COMMADS=On /path/to/source-root
// compile_commands.json
[
{
"file": "....\\A.cpp",
"command": "clang-cl.exe ....\\A.cpp -m64 .... -MDd -std:c++latest",
"directory": "...\\projectDir"
},
{
"file": "....\\B.cpp",
"command": "clang-cl.exe ....\\B.cpp -m64 .... -MDd -std:c++latest",
"directory": "...\\projectDir "
},
{
"file": "....\\B.cpp",
"command": "clang-cl.exe ....\\B.cpp -m64 .... -MDd -std:c++latest",
"directory": "....\\projectDir "
}
]
Как мы видим, в полученном compile_commands.json при компиляции всего проекта дважды повторяется команда для B.cpp. В данном случае анализатор прогрузит символы одной из команд, так как они полностью совпадают. Но если сделать содержимое файла B.cpp зависимым от флагов компиляции, с помощью директив препроцессора например, то такой гарантии не будет. На момент написания статьи эта проблема не решена должным образом. Мы планируем заняться этим, но пока что приходится работать с тем, что есть.
Как вариант, мне удалось найти возможность управлять содержимым compile_commands.json через CMake. Однако он не очень гибкий, так как приходится модифицировать CMakeLists.txt вручную. Начиная с CMake 3.20, присутствует возможность указать для цели свойство EXPORT_COMPILE_COMMANDS. Если оно установлено в TRUE, для цели запишутся команды в итоговый файл. Итак, добавив несколько строчек в свой CMakeLists.txt, можно сгенерировать необходимый набор команд:
CMakeLists.txt:
....
project(multilib)
....
set(CMAKE_EXPORT_COMPILE_COMMANDS FALSE) #disable generation for all targets
add_library(lib1 A.cpp B.cpp)
add_library(lib2 B.cpp)
#enable generatrion for lib2
set_property(TARGET lib2 PROPERTY EXPORT_COMPILE_COMMANDS TRUE)
Далее запускаем анализ на compile_commands.json:
pvs-studio-analyzer analyze -f /path/to/build/compile_commands.json ....
Обращу внимание, что если задать это свойство сразу для нескольких целей сборки, то их команды компиляции также сольются в один список.
PVS-Studio предоставляет способ запускать анализ с помощью Compilation Database непосредственно через CMake. Для этого нужно подключить специальный CMake модуль. Подробнее можно почитать в документации. На момент написания статьи поддержка межмодульного анализа в нём не реализована, но направление перспективное.
Другим вариантом будет отслеживать команды компоновщика, как мы это делаем для команд компиляции через нашу утилиту CLMonitor или через strace. Возможно, мы поддержим такой вариант в будущем, но у него тоже есть минус в том, что необходимо произвести сборку проекта, чтобы отследить все вызовы.
Подключение семантического модуля для сторонней библиотеки
Представим ситуацию. У вас есть основной проект, который нужно проанализировать. В него подключаются заранее скомпилированные сторонние библиотеки. Будет ли для них работать межмодульный анализ? К сожалению, ответ "нет". Если в вашем проекте нет команд компиляции для сторонней библиотеки, то на них не будет происходить семантический анализ, ведь у нас есть доступ только к заголовочным файлам. Однако существует теоретическая возможность заранее подготовить модуль семантической информации для библиотеки и подключить его к анализу. Для этого нужно произвести слияние этого файла с основным для вашего проекта. На момент написания статьи это можно сделать только вручную, но мы хотим автоматизировать этот процесс. Идея заключается в следующем:
Нужно заранее подготовить объединённый .dfo файл для сторонней библиотеки, проанализировав её код.
Выполнить первый этап межмодульного анализа и подготовить .dfo файлы для каждой единицы трансляции основного проекта.
Выполнить слияние всех семантических модулей проекта вместе с файлом сторонней библиотеки. Если при этом не нарушается правило единственного определения, всё пройдёт гладко.
Выполнить третий этап межмодульного анализа.
При этом нужно помнить, что пути в .dfo файлах хранятся в абсолютном виде, поэтому нельзя перемещать исходники сторонней библиотеки или передавать файл на другие машины. Нам ещё предстоит придумать удобный способ конфигурировать сторонние семантические модули.
Оптимизации
Что ж, разобрались с алгоритмами анализа. Далее хотелось бы обсудить две оптимизации, которые кажутся нам интересными.
Интернирование строк
Тут я имею в виду кэширование данных в общем источнике так, чтобы отовсюду можно было на них ссылаться. Чаще всего, такую оптимизацию делают со строками. К слову, последних в наших файлах довольно много. Потому что в DFO файле сохраняется позиция для каждого символа или факта. И каждая такая позиция хранится в виде строки. Вот, например, как это могло бы выглядеть:

Как мы видим, данные часто дублируются. Если сложить все уникальные строки в секцию .data, то объём файла, а также время чтения и записи в него значительно уменьшатся. Реализовать такой алгоритм можно довольно просто с помощью ассоциативного контейнера:
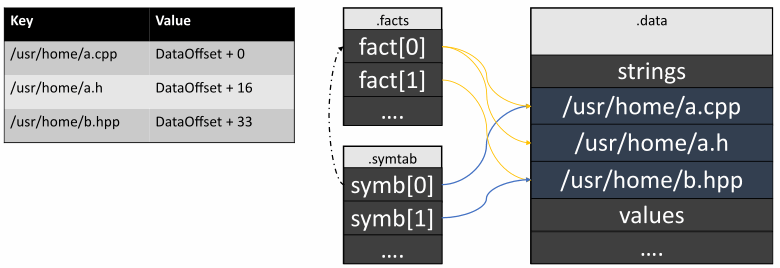
Теперь во всех секциях, кроме секции данных, хранятся только соответствующие адреса строк.
Префиксное дерево
Несмотря на то, что строчки теперь уникальны, данные в них всё ещё дублируются. Например, на этом рисунке у всех путей одинаковая первая часть, или префикс:

И такая ситуация повторяется очень часто. Префиксное дерево решает эту проблему.

В таком представлении конечные узлы (листья) будут являться ссылками. Ситуаций, когда строчка полностью совпадает с префиксом другой, у нас возникать не должно, так как мы работаем с файлами, которые уникальны в системе. Восстановить полную строку можно обратным проходом до корня дерева. Операция поиска в таком дереве прямо пропорциональна длине искомой строки. Проблемы могут быть в регистронезависимых файловых системах, где два разных пути могут указывать на один файл, но в нашем случае это можно не учитывать, так как это обрабатывается позже при сравнении. Однако в .dfo файлах всё же можно хранить исходные пути, уже прошедшие нормализацию.
Заключение
Межмодульный анализ открывает множество ранее недоступных возможностей и позволяет находить интересные ошибки, которые сложно обнаружить простым прочтением кода. Тем не менее, нам предстоит проделать ещё много работы по оптимизации и расширению функциональности. Межмодульный анализ можно попробовать уже сейчас. Он доступен, начиная с версии PVS-Studio v7.14. Загрузить самую свежую версию можно с нашего сайта. Подробнее о том, как его использовать можно прочитать в предыдущей статье. Если у вас возникнут проблемы или идеи, вы можете написать нам, мы обязательно постараемся помочь. Обратите внимание, что при запросе триала по приведённой ссылке вы можете получить Enterprise-лицензию на 30 дней. Надеемся, что этот режим окажется полезным в исправлении ошибок в вашем проекте.
datacompboy
И снова граф вызовов помог бы :)
datacompboy
Ну или схалявить и воспользоваться тем, что память дешевая и процессоры мощные -- данные писать пропуская через xz/gz/lz/хз :)
Minatych Автор
Была такая идея. Можно совместить подходы)
datacompboy
Дожатие после убирания энтропии не так эффективно... Ну сожмется на 5-7%. То оэли. Дело 80-90%!
Minatych Автор
Тоже верно) Тут только практика покажет.
Minatych Автор
Да, действительно. Но, не факт, что такой подход будет быстрым с учётом того, чего ждут от инкрементального анализа. Тут мы сталкиваемся с той же задачей, что и при глубоком анализе. Чтобы передать информацию об эффектах, которые передаются через несколько вызовов функций необходимо несколько раз выполнить проверку файлов с исходным кодом. Подробнее об этой проблеме описано в разделе глубокого анализа.
datacompboy
Не обязательно же. Можно построить граф зависимостей, провести топологическую сортировку и пройти по функциям (не файлам!) в этом порядке.
Граф вызовов и проход по ф-ям так же позволит моментальный проход на изменения. Это же как формулы в экселе!
Minatych Автор
После того, как анализатор собрал всю информацию из единицы трансляции вся память сбрасывается. Так сделано потому что внутреннее представление анализатора для всех модулей программы просто не влезет в адекватные объемы. Из-за этого, чтобы снова разобрать функцию, нужно полностью транслировать файл. При чем не получится читать только тело функции, так как в ней могут быть различные сайд эффекты и типы данных. Например, глобальные переменные, или вызов других функций. Всю эту информацию придется собирать заново. Если функция вызывает другую функцию, определение которой находится в другой единице трансляции, то и эту единицу трансляции тоже придется анализировать целиком. И так по цепочке. Все это усугубляется возможными циклическими вызовами.
Идея конечно неплохая. Но, для реализации необходимо промежуточное представление, при чем связываемое с исходным кодом. Такое, чтобы его трансляция была быстрой и давала всю необходимую информацию. Сделать такое уже по сути сравнимо с написанием полноценного компилятора. Да и будет ли это достаточно эффективно - открытый вопрос.
datacompboy
Да, держать в памяти всё из всех единиц трансляции -- не пыщ пыщ, по любому. Но из статьи я не понял почему нельзя генерить объектники с полным результатом анализа, в который и заглядывать если файл не поменялся -- перечитать, если поменялся.
Да, инкрементальные обновления этого представления во время редактирования это дорого и сложно, нужна совершенно другая архитектура и представление, которое позволяет "наслаивать" изменения для хотя бы простых отмен; возможна ли структура которая позволит инкрементально менять дерево в обе стороны (дописали букву a после int lo => определение lo убрали, определение loa добавили, если где-то есть доступы к lo пометили как проблемные и пр)... Ну точнее возможна-то возможна, а вот возможна ли эффективно и в разумные затраты человекочасов?