
Привет, чемпион!
Я работаю в юните rdl by red_mad_robot. В рабочее время вместе с коллегами мы разрабатываем ML решения для тяжелой промышленности, а в свободное время участвуем в чемпионатах по анализу данных на Kaggle.
Так мы недавно потратили месяц на соревнование «UW-Madison GI Tract Image Segmentation» и не взяли золото. Золотую медаль не взяли, но теперь у каждого из нас есть первая бронза. И сейчас мы кратко расскажем про сработавшие подходы в сегментации. А еще расскажем, что можно было сделать, чтоб все-таки золото забрать. (Спойлер: мы были в шаге от золота ????)
Задача
В этом конкурсе надо было создать модель для автоматического сегментирования желудка и кишечника на МРТ-сканах. Снимки МРТ взяты у реальных пациентов онкологического центра UW-Madison Carbone, которые прошли 1-5 МРТ в разные дни во время лучевой терапии.
Подробнее о лучевой терапии...
Подробнее о лучевой терапии и смысле задачи: примерно половине пациентов, у которых диагностирован рак желудочно-кишечного тракта, показана лучевая терапия, обычно проводимая в течение 10-15 минут в день в течение 1-6 недель. Онкологи-радиологи пытаются доставить высокие дозы радиации, используя рентгеновские лучи, направленные на опухоли, избегая при этом желудка и кишечника. Благодаря новейшим технологиям, таким как интегрированная магнитно-резонансная томография и системы линейных ускорителей, также известные как MR-Linac, онкологи могут визуализировать ежедневное положение опухоли и кишечника, которое может меняться изо дня в день. При этих сканированиях онкологи-радиологи должны вручную наметить положение желудка и кишечника, чтобы отрегулировать направление рентгеновских лучей, чтобы увеличить дозу, доставляемую к опухоли, и избежать попадания в желудок и кишечник. Это трудоемкий процесс, который может продлить лечение с 15 минут до часа в день, что может быть трудно для пациентов. Метод автоматической сегментации желудка и кишечника значительно ускорит процедуру и позволит большему количеству пациентов получить более эффективное лечение.
Ограничения:
Время инференса не более 9 часов
На ресурсах Kaggle: 13Gb RAM, 16Gb GPU, 2core CPU
Без доступа к Интернет
???? Данные
Данные представляли из себя наборы слайсов (от 80 до 110) МРТ снимков за 1 или несколько дней, разделенные по пациентам - изображения в формате .png и координаты масок в формате rle. Метрики соревнования: Dice coefficient и 3D Hausdorff distance
???? Подходы
Классическая задача сегментации медицинских данных: просмотрев публичные ноутбуки, выделили 3 основных подхода к решению:
Семантическая или инстанс сегментация на 2D данных. Тут все слайсы с масками подаются в сеть и сегментируются.
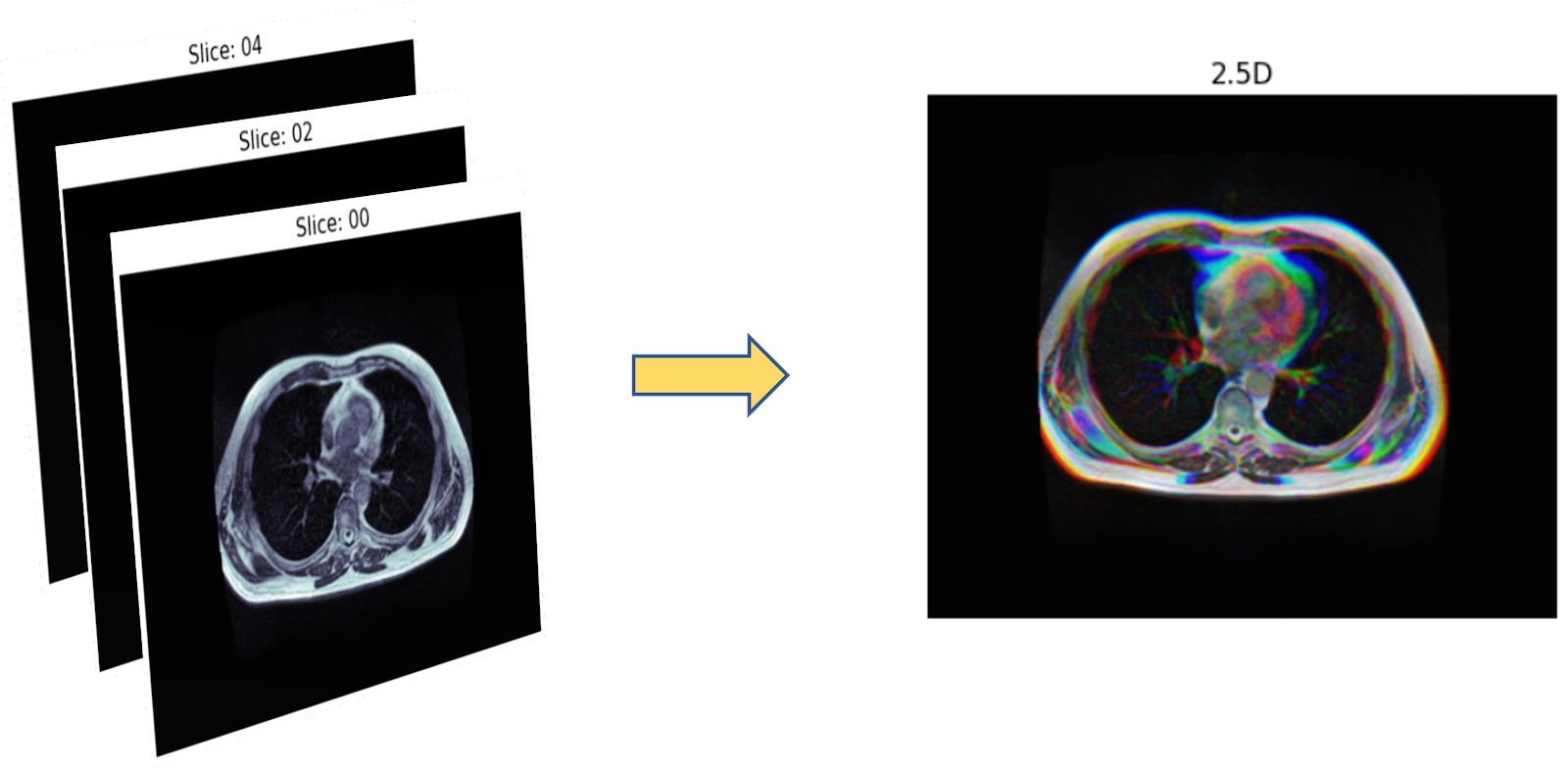
Семантическая или инстанс сегментация на, так называемых 2.5D данных. (Тут мы объединяем слайсы в тройки, вырезая разные цветовые каналы, получая что-то похожее на стереокартинки). Архитектуры для сегментации 2D и 2.5D изображений: SegNet, Unet с различными бэкбонами, различные комбинации с вижн-трансформерами например, TransResUnet и пр.
Семантическая сегментация на 3D данных - склеиваем все слайсы в один объект и подаем в нейросеть. Архитектуры: Squeeze-and-Excitation UNet, SegResNet
Как думаете какой подход в итоге оказался в топе?
????Что пробовали?
Так как заходили в соревнование уже ближе к окончанию, решили сразу изучить какие подходы уже были в топе лидерборда. Сходу было принято решение разделить ресурсы команды и сосредоточиться на 2.5D и 3D данных. В лучших традициях соревновательного Data Science, мы решили обучить побольше различных архитектур, чтобы обеспечить устойчивость итоговой модели, параллельно экспериментируя с различными loss-функциями, scheduler'ами, аугментациями. И в конце, если останется время, попробовать сблендить маски от 2.5D и 3D сеток (чисто поржать - посмотреть, что получится). Не забываем, что на инференс всего 9 часов, - тесты показали, что инференс 1 фолда занимает больше часа. То есть всего можно было использовать не более 8 фолдов. Стало быть, предстоял жесткий отбор. От изначального плана сблендить 30 сеток быстро пришлось отказаться.
Что там по 2D архитектурам?
Начали с 2D архитектур. Попробовали классический вариант - Unet c бэкбоном «пожирнее» (EfficientNet-b7). Однако, он плохо себя показал. Слили затею.
В итоге, остановились на TransResUnet. Это довольно свежая (~2021) архитектура для медицинских данных с ResNet и трансформером в качестве feature extractor'а. Взяли для ансамбля разные комбинации loss-функций и вариант с более тяжелым трансформером. Ансамбль лучших фолдов этих моделей уступал на паблик части лидерборда всего 0.006 ансамблю 3D архитектур. Забегая вперед, на прайвате разрыв вырост до 0.018.
А что по 3D архитектурам? Пытаемся побить Unet бейзлайн.
Для работы с 3D мы начали с подбора хороших моделей. Мы запарились и изучили серию статей победителей двух медицинских соревнований по 3D сегментации. Первая статья использовала модификацию squeeze and excitation UNet (Iantsen et al head and neck tumor) , авторы которой выиграли чемпионат по "Head and neck tumor segmenation" в 2020 году. Вторая статья была от NVIDIA, где авторы выиграли "BRATS 2021 brain tumor nvidia" сегментация опухоли мозга. Использовался простой UNet, который был оптимизирован с помощью библиотеки nnUnet на GitHub. Squeeze and excitation UNet показал результаты лучше, чем бейзлан с жирным Unet. Настройка либы nnUnet заняла бы слишком много времени, а его уже было в обрез. Решили вместо nnUnet взять альтернативу DynUnet из библиотеки MONAI. MONAI топовая либа для мед сегментации, включает модели, аугментации, лоссы, метрики, и тд. DynUnet - это динамический Unet который можно настраивать для определенной задачи. Однако, результаты оказались чуть хуже, чем Unet бейзлайн его мы не стали брать в обойму.
Идем дальше и тестируем SwinUNETR и Segresnet из MONAI. Архитектура SwinUNETR показывала топовые результаты на многих задачах сегментации, но в нашей задаче скор оказался хуже, чем бейзлайн Unet. Segresnet одна из топовых моделей 2019 года, использующая skip connections ResNet внутри Unet. И вот тут уже, результаты оказались лучше, чем бейзлайн! Ура! Удачная архитектура найдена. Что дальше?
✈️ Верно выбранная архитектура ничего не решает. Что делать?
Как только определились с архитектурой, тут же начали тестировать другие конфигурации обучения. Лосс-функции: dice loss, tversky loss, bce loss, focal loss и их комбинации. Как итог, комбинация bce loss и dice loss и комбинация bce loss и tversky loss сработали лучше всего.
Также пробовали два типа scheduler'а: polynomial (использовали в Nvidia) и cosine annealing with warm restarts (использовали Iantsen et al). Cosine annealing with warm restarts дал лучшие результаты.
Выжимая максимум из архитектуры, мы перебрали десятки разных аугментаций из MONAI. На основе локальной валидации отобрали аугментации: flipping, rotation (15 degrees), gamma correction, gaussian noise and smoothing, pixel shuffling, pixel drop out, elastic deformation, intensity related augmentations. Аугментаций было много и обучение длилось больше 1000 эпох.
В погоне за стабилизацией модели, мы добавили test time augmentation. Такая техника, где 3D картинка переворачивается во время инференса, и далее усредняется конечный аутпут.
Все готово, теперь собираем конечный ансамбль из 7 моделей с весами пропорционально метрикам на лидерборде.
???? Работа сделана, но мы все еще не в медалях, проиграли?!
На Kaggle можно выиграть двумя способами. Первый - это сразу сделать сильную модель с хорошим скором. Главное для этой модели - это удержаться на приватной выборке. (Укротить шейк-ап). Второй способ победы - это стабилизировать и диверсифировать финальную модель. Тогда даже если финишировать далеко от топа не с самым лучшим скором, то можно хорошо подняться из грязи в князи на приватной выборке, попав в медальную зону. Именно такую стратегию в условиях дефицита времени мы выбрали для себя. Хорошо валидируем модель и собираем ансамбль из разных подходов.
⚔️ Смешиваем 2.5D и 3D модели и крестимся.
Имея на руках ансамбли обученных моделей с отобранными лучшими фолдами, которые выдавали скор в медальном топе (или рядом с ним), решили в последние 3 дня попробовать всё-таки блендинг 2.5D и 3D подходов. Оставалось 15 сабмишенов на всё. При этом ещё параллельно продолжают доучиваться другие архитектуры, которые тоже надо было проверять на лидерборде.

Не откладывай блендинг моделей на конец!
До этого момента все шло гладко, но на смешивании 2.5D и 3D подходов начались проблемы. Сетки выдавали тензоры разных размеров, по-разному декодировались маски. Командным брут-форсом мы смогли исправить эту проблему. Закрыв одну проблему, пришла новая...
Решение перестало проходить по памяти. Что ж, снова командный брут-форс. В 6 рук мы начали оптимизировать и переписывать код, вроде бы процесс пошел...
Внезапно Kaggle нанес дополнительный удар ножом в спину. Оказалось, что неудачные сабмишены (падающие из-за ошибки) засчитываются за попытки. Неприятно, но пытаемся спрогнозировать потенциальные ошибки и стабилизировать решение.
???? Решающий момент и выбор решения
В конце сложилась кинематографичная ситуация - Встал выбор, на что потратить последнюю попытку?
Ещё раз проверить бленд двух архитектур, который может зафейлиться?
или испытать свежую комбинацию доучившихся фолдов с другими весами?
Что бы выбрали вы? Будучи не в медальной зоне, мы не стали рисковать и ставить все на кон. Мы выбрали второй вариант. Оказалось, не зря...
После публикации прайват части лидерборда, благодаря ансамблю 3D архитектур, нашу команду шейкапнуло сразу на 90 мест в первую сотню (92 место). Вдох-выдох и вот заслуженная бронза! Хоть подход с 2.5D моделями нам тоже нравился, эти модели сильнее просели на прайват части. Большинство решений над нами именно по этой причине полетели вниз.

???? А кто забрал золото?
А что же у тех, кто в золоте? Правильно! - блендинг 2D и 3D архитектур! Смешивание этих подходов давало возможность попасть в золотые медали. Ребята опытнее нас, раньше осознали, что эти два подхода принципиально разные, а значит их ансамбль должен дать наибольший перфоманс. Они не ошиблись. Мы тоже понимали, но ... не успелось.
???? Мысли и рефлексия
Всегда обидно не успеть попробовать все запланированные гипотезы, особенно, если это могло привести к более высоким позициям. После финиша соревнования, мы все же попытались заслать ансамбль из 2.5D и 3D. После несколько дней попыток, мы так и не смогли решить проблемы с памятью на Kaggle. Это нас успокоило, значит не лопухнулись, а действительно просто не справились. Это менее обидно. В следующий раз будем начинать заранее.
✅ Итоги и выводы
Не откладывай всё на последний день
Учи много моделей, пробуй разные подходы.
Делай то, что другие не пробовали.
Играй в команде! Вместе можно параллелить проверку гипотез.
Ты не проиграл, пока нет результатов с прайвата.
Прайват всех расставит по местам, поэтому пристегивайся!
Покупай сервак помощнее, сможешь запускать сетки пожирнее =)
Спасибо, что дочитал до конца. Следи за нашими следующими победами в телеграмм канале. Пока ты читаешь эту статью, возможно мы выиграли еще что-то, завоевав новые медали на Kaggle.
Авторы статьи:
Александр Миленькин (@Aleron75)
Иван Александров (@ivanich_spb)
Отабек Назаров
MiXaiLL76
Пробовали выбрать топовые модели и запустить на пару дней Optuna?
Это конечно не прям best practices, но вполне рабочая схема для точечного улучшения выбранной модели.
Aleron75 Автор
Привет, Михаил!
Подбирать параметы Optuna'ой не пробовали, не хватило бы мощностей. Архитектуры слишком тяжелые для перебора параметров. А так идея хорошая, на текущем HubMap может быть попробуем. Там обучении модели занимает часа два как раз.