
При выполнении параллельной программы, активно задействующей CPU, нам часто необходимо, чтобы пул потоков или процессов имел размер, сопоставимый с количеством ядер CPU на машине. Если потоков меньше, то вы не будете использовать все преимущества ядер, если больше, то программа начнёт работать медленнее, так как несколько потоков будет конкурировать за одно ядро. Ну, или такова ситуация в теории.
Как же проверить, сколько ядер есть у компьютера? И действительно ли это хороший совет?
Оказывается, на удивление сложно определить, сколько потоков выполнять:
В стандартной библиотеке Python есть множество API для получения этой информации, но ни одного из них недостаточно.
Хуже того, из-за таких функций CPU, как параллельность на уровне команд и одновременной многопоточности (Hyper-threading в CPU Intel), количество ядер, которое можно эффективно использовать, зависит от того кода, который напишете вы!
Давайте разберёмся, почему так сложно определить, сколько ядер CPU может использовать программа, а затем подумаем над потенциальным решением.
Получение количества ядер CPU из Python
Если вы читали документацию стандартной библиотеки Python, то знаете, что в ней есть стандартная функция os.cpu_count(), возвращающая «количество логических CPU». Что значит «логических»? Мы вернёмся к этому чуть позже.
В документации также говорится, что «len(os.sched_getaffinity(0)) получает количество логических CPU, которым ограничен вызывающий поток текущего процесса». Ограничение процесса конкретными ядрами обеспечивается привязкой планировщика (scheduler affinity).
К сожалению, этого API тоже недостаточно. Например, в Linux есть API cgroups, используемый для реализации Docker и других контейнерных систем; он имеет множество способов ограничения нагрузки на CPU. В примере ниже мы ограничиваем CPU эквивалентом 2,25 ядер; механизм отличается, но результат будет схожим:
$ docker run -i -t --cpus=2.25 python:3.12-slim
Python 3.12.1 (main, Dec 9 2023, 00:21:37) [GCC 12.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import os
>>> os.cpu_count()
20
>>> len(os.sched_getaffinity(0))
20Одновременно мы можем использовать эквивалент 2,25 ядер, но ни один API не знает об этом.
Что такое логический CPU?
Опции операционной системы — лишь начало наших проблем, но прежде чем рассматривать пример, мы должны понять, что такое физические и логические ядра CPU. В моём компьютере установлен процессор Intel i7-12700K, обладающий:
12 физическими ядрами (8 высокопроизводительных ядер и 4 менее мощных).
20 логическими ядрами.
Современные ядра CPU способны параллельно исполнять несколько команд. Но что произойдёт, если CPU «зависнет», ожидая загрузки каких-то данных из ОЗУ? Он не сможет выполнять никакую работу, пока этого не произойдёт.
Чтобы позволить использовать эти потенциально впустую растрачиваемые ресурсы, вычислительные ресурсы физического ядра CPU могут предоставляться операционной системе как несколько ядер. В моём CPU каждое из восьми быстрых ядер можно представить как два ядра, что даёт суммарно 16 логических ядер. Пары логических ядер будут совместно использовать вычислительные ресурсы одного физического ядра. Например, если логическое ядро не полностью использует внутренние АЛУ, допустим, потому что оно ожидает загрузки из памяти, то код, выполняемый парным логическим ядром, всё равно сможет использовать эти простаивающие ресурсы.
Эта технология называется одновременной многопоточностью (Hyper-threading в терминологии Intel). Если у вас PC, то эту функцию часто можно отключить в BIOS.
Это объяснение очень неточное, и настоящая реализация может быть разной на различных моделях CPU, даже от одного производителя. Но главное здесь то, что логические ядра не совпадают с физическими ядрами, и этого объяснения достаточно для наших целей.
Итак, у нас возникает новый вопрос. Если забыть о привязке планировщика и тому подобном, нужно ли нам использовать количество физических или логических ядер в качестве размера пула потоков?
Неожиданный пример параллельности
Рассмотрим две функции, компилируемые в машинный код при помощи Numba. Чтобы обеспечить параллельность, мы отключим GIL.
Обе функции делают одно и то же, но одна гораздо быстрее другой. Мы можем запустить эти функции параллельно в нескольких потоках и теоретически получать линейный рост производительности, пока не закончатся ядра, просто благодаря параллельной обработке большего количества изображений.
from numba import njit
import numpy as np
@njit(nogil=True)
def slow_threshold(img, noise_threshold):
noise_threshold = img.dtype.type(noise_threshold)
result = np.empty(img.shape, dtype=np.uint8)
for i in range(result.shape[0]):
for j in range(result.shape[1]):
result[i, j] = img[i, j] // 256
for i in range(result.shape[0]):
for j in range(result.shape[1]):
if result[i, j] < noise_threshold // 256:
result[i, j] = 0
return result
@njit(nogil=True)
def fast_threshold(img, noise_threshold):
noise_threshold = np.uint8(noise_threshold // 256)
result = np.empty(img.shape, dtype=np.uint8)
for i in range(result.shape[0]):
for j in range(result.shape[1]):
value = img[i, j] >> 8
value = (
0 if value < noise_threshold else value
)
result[i, j] = value
return resultМы запустим функцию для изображения и замерим, как долго она выполняется:
rng = np.random.default_rng(12345)
def make_image(size=256):
noise = rng.integers(0, high=1000, size=(size, size), dtype=np.uint16)
signal = rng.integers(0, high=5000, size=(size, size), dtype=np.uint16)
# A noisy, hard to predict image:
return noise | signal
NOISY_IMAGE = make_image()
assert np.array_equal(
slow_threshold(NOISY_IMAGE, 1000),
fast_threshold(NOISY_IMAGE, 1000)
)Вот сколько времени требуется для выполнения каждой из функций на одном ядре:
%timeit slow_threshold(NOISY_IMAGE, 1000)90.6 µs ± 77.7 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)и
%timeit fast_threshold(NOISY_IMAGE, 1000)24.6 µs ± 10.8 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)Вам интересно, почему быстрая функция намного быстрее? Возможно, стоит прочитать книгу об оптимизации низкоуровневого кода, над которой я работаю.
Масштабируемся до нескольких ядер
Теперь, когда у нас есть пара функций, можно обработать список изображений при помощи пула потоков; при этом каждый поток будет обрабатывать по 10 изображений за раз:
from multiprocessing.dummy import Pool as ThreadPool
def apply_in_thread_pool(
num_threads, function, images
):
with ThreadPool(num_threads) as pool:
result = pool.map(
lambda img: function(img, 1000),
images,
chunksize=10
)
assert len(result) == len(images)Далее мы создадим графики времени выполнения при разных количествах потоков различных функций при помощи библиотеки benchit (можно также использовать perfplot, но учтите, что она имеет лицензию GPL):
import benchit
benchit.setparams(rep=1)
# Через каждый поток будет обработано 4000 изображений:
IMAGES = [make_image() for _ in range(4000)]
def slow_threshold_in_pool(num_threads):
apply_in_thread_pool(num_threads, slow_threshold, IMAGES)
def fast_threshold_in_pool(num_threads):
apply_in_thread_pool(num_threads, fast_threshold, IMAGES)
# Измеряем показатели двух функций с использованием от 1 до 24 потоков:
timings = benchit.timings(
[slow_threshold_in_pool, fast_threshold_in_pool],
range(1, 25),
input_name="Number of threads"
)
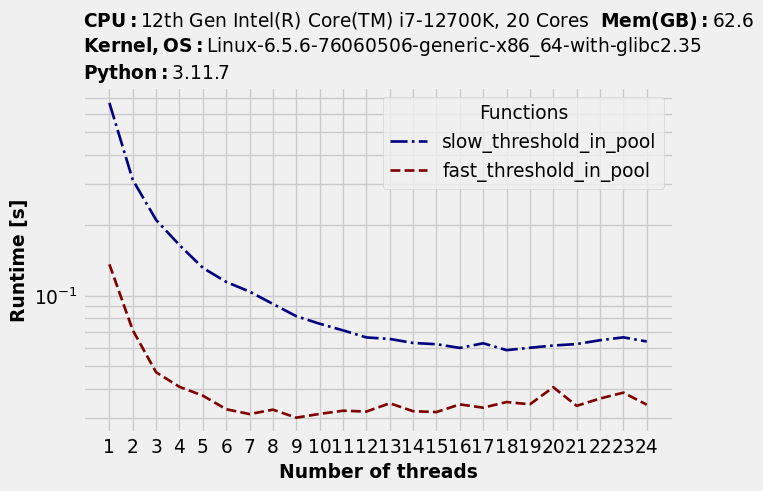
timings.plot(logy=True, logx=False)
Обратите внимание, что время исполнения снижается с увеличением количества потоков... до определённой точки. После неё время исполнения снова начинает повышаться. Этого мы и ожидали. Но есть и нечто неожиданное: оптимальное количество потоков для двух функций различается.
timings.to_dataframe().idxmin(axis="rows")Функции |
Оптимальное количество потоков |
|---|---|
slow_threshold |
19 |
fast_threshold |
9 |
Оптимальный уровень параллельности также зависит от вашего кода
Медленная функция, по сути, способна использовать преимущества всех логических ядер. Возможно, один поток не использует полностью всю доступную вычислительную мощь конкретного физического ядра, так что логические ядра обеспечивают бОльшую параллельность.
И наоборот, более быстрая функция может использовать преимущества не более чем девяти ядер; при увеличении их количества начинается замедление. Возможно, она упирается в какое-то другое узкое место, не в вычислительные ресурсы, например, в пропускную способность памяти.
Не существует размера пула потоков, оптимального для обеих функций.
Другой подход: эмпирические измерения
При определении оптимального количества потоков мы столкнулись с несколькими проблемами:
Сложно получить точное количество ядер с учётом всевозможных способов, которыми операционная система способна ограничивать используемые ресурсы CPU.
Оптимальный уровень параллельности, то есть количество потоков зависит от рабочей нагрузки.
Количество ядер — не единственное узкое место.
Бонусная проблема: если вы исполняете код в облаке, то используете «vCPU», что бы это ни значило. Например, в разных инстансах используются разные модели CPU.
Есть и другой подход: определять оптимальное количество потоков эмпирически, во время исполнения. В показанном выше примере мы измеряли оптимальное количество потоков для конкретного фрагмента кода. Если у вас длительная задача по обработке данных, долго исполняющую один и тот же код в нескольких потоках, то можно сделать так же. То есть потратить немного времени в начале процесса, чтобы эмпирически замерить оптимальное количество потоков, возможно, с какими-то эвристиками для компенсации шума.
Если в среде исполнения вы используете эмпирические измерения, то вам не нужно беспокоиться о том, почему оптимально конкретное количество потоков. Вне зависимости от оборудования, конфигурации операционной системы или облачной среды вы будете использовать оптимальный уровень параллельности.
Комментарии (22)

theurus
29.12.2023 11:15-1Захотелось мне однажды найти все счастливые ip адреса. Написал на питоне программу которая перебирала 4млрд адресов и считала суммы чисел внутри адреса.
Запустил на одном ядре, понял что не дождусь.
Запустил на всех ядрах, понял что не дождусь.
Попросил чатгпт переписать на си. Сишная версия отработала на одном ядре за 5 секунд.

MountainGoat
29.12.2023 11:15+3Вы меня сподвигли на эксперименты.
Наивнейшая реализация
octet = list(range(1,255)) counter = 0 for i1 in octet: print (f"{i1}", end='\r') for i2 in octet: for i3 in octet: for i4 in octet: if i1+i2 == i3+i4: counter += 1 print (counter)Заняла 4 минуты 13 секунд. Попробовал использовать модуль array - время совсем не изменилось. Удивился, думал хоть немного спасёт.
Переписываем, чуть-чуть включив мозги.
Вариант с мозгами
from collections import defaultdict from timeit import default_timer as timer start_t = timer() octet = list(range(1,255)) variantos = defaultdict(int) for i1 in octet: print (f"{i1}", end='\r') for i2 in octet: summ = i1+ i2 variantos[summ] += 1 counter = 0 for k, v in variantos.items(): counter += v*v print (counter) end_t = timer() print(end_t - start_t)Причём первый цикл наверное не нужен - я просто не уверен, что список возможных сумм непрерывный, а проверять влом.
Получилось 0.012 секунд. Ой.
Результат, кстати, 10924794

squaremirrow
29.12.2023 11:15Как насчет такой тупой реализации, обернутой в нумбу?
Тупой вариант с нумбой
import numba as nb import numpy as np from timeit import default_timer as timer start_t = timer() @nb.njit def fast_counter(): octet = np.arange(1, 255, dtype=np.uint8) counter = 0 for i1 in octet: #print (f"{i1}", end='\r') for i2 in octet: for i3 in octet: for i4 in octet: if i1+i2 == i3+i4: counter += 1 return counter fast_counter() end_t = timer() print(end_t - start_t)MountainGoat
29.12.2023 11:15+10.7611 секунд. И ещё ждать, пока нумба установится...
0.6482 секунд, если заменить
dtype=np.uint8наdtype=np.int320.5804 секунд, если не использовать numpy и вернуть list как было.

9982th
29.12.2023 11:15Вы считаете сумму октетов, а не сумму цифр в октетах, это заметно быстрее.
9982th
29.12.2023 11:15Не так уж и заметно, оказывается. Если рассчитать сумму цифр возможных значений октета заранее, то выходит 4:28 на моей машине.
Hidden text
sum_of_digits = [sum(int(x) for x in str(number)) for number in range(256)] counter = 0 octet = tuple(range(0, 256)) for i1 in range(1, 256): print (f"{i1}", end='\n') for i2 in octet: for i3 in octet: for i4 in octet: if sum_of_digits[i1] + sum_of_digits[i2] == sum_of_digits[i3] + sum_of_digits[i4]: counter += 1 print(counter)Если переписать на C, то получается (на более слабой машине)
real 0m9.139s user 0m9.133s sys 0m0.005s

Sly_tom_cat
29.12.2023 11:15Ну если еще чуть подумать, то
variationsможно еще быстрее собрать (О(n) вместо О(n^2)).Sly_tom_cat
29.12.2023 11:15Хотя если еще подумать, то и собирать
variationsне зачем там вообще один цикл на самом деле нужен:l = 256 t = 0 for s in range(1, l): t += s*s * 2 t += l*l print(t)Да, и ответ у вас неверный. Вы почему-то считаете, что октет может иметь значения от 1 до 254 (включительно) хотя он от 0 до 255. И хотя некоторые счастливые IP v4 и зарезервированы как служебные и никто их выдать не может, но абстрагируюясь от этого ответ будет 11184896. Зарезервированные счастливые можно при желании вычесть.
Варианты: ваш "умный", мой с O(n) при построении variations и тот что выше:
11184896
0.010685138004191685
11184896
0.00014450500020757318
11184896
4.1819999751169235e-05



Andrey_Solomatin
29.12.2023 11:15+12Вам интересно, почему быстрая функция намного быстрее? Возможно, стоит прочитать книгу об оптимизации низкоуровневого кода, над которой я работаю.
Два раза заполнить массив и один раз заполнить массив. Что здесь низкоуровневого?
Может сначала надо научиться пользоваться оптимизациями numpy?
Зачем вам умный контейнер для быстрых вычислений над элементами, если вы делаете всё снаружи?
Если вам надо сделать один массив из другого, да еще и одинаковой размерности, то надо все делать внутри.from timeit import timeit import numpy as np def f_bad(img, noise_threshold=5): result = np.empty(arr.shape, arr.dtype) for i in range(result.shape[0]): result[i] = 0 if img[i] < noise_threshold else img[i] return result def f_good(img, noise_threshold=5): return np.where(img < noise_threshold, 0, arr) if __name__ == "__main__": arr = np.array(list(range(100))) print(timeit("f_bad(arr)", globals=globals())) # 15.4994 print(timeit("f_good(arr)", globals=globals())) # 1.2924

Dominux
29.12.2023 11:15+4При выполнении параллельной программы, активно задействующей CPU, нам часто необходимо, чтобы пул потоков или процессов имел размер, сопоставимый с количеством ядер CPU на машине
Распараллеливание CPU-bound задач сводится к их непосредственному запуску процессов на разных ядрах CPU. Потоки, в данном случае, не подходят в принципе, т.к. процесс исполняется на одном ядре, и сколько потоков не выделяй -- они все будут исполняться в рамках одного.
Конкретно Python располагает не малым арсеналом встроенных механизмов распараллеливания задач на разных ядрах. Так, например, могу порекомендовать посмотреть в сторону ProcessPoolExecutor, т.к. он предоставляет весьма удобный интерфейс для управления пулом процессов на высоком уровне
Количество ядер, которое можно эффективно использовать, зависит от того кода, который напишете вы!
Интересно, а как интерпретатор должен догадаться за вас, что, когда и как ему нужно распараллеливать. Это уже какое-то чтение мыслей получается
Прибавив ещё и то, что автор берет
numpyи не знает, что это обёртка над C-библиотекой, которая спрашивает о выделении процессов у ОС, а не у CPython, и выходит, что статья написана в стиле "Я тут зашел в ваш Python и чет он ничего не может"
P.s.: считаю, что на хабре кроме редактуры на грамматику необходимо также ввести цензор на ошибочные или глупые статьи, а то пока мы имеем вот такие статьи, где автор искренне негодует по поводу того, что интерпретатор не может сам догадаться и исполнить его код так, как он хочет, а потоки почему-то не исполняются в рамках разных ядер
slonopotamus
29.12.2023 11:15+3Потоки, в данном случае, не подходят в принципе, т.к. процесс исполняется на одном ядре, и сколько потоков не выделяй -- они все будут исполняться в рамках одного.
Эммм... Нет. В питоне многопоточность убита GIL'ом, но во-первых в данном примере его выключили, а во-вторых, в других языках GIL'а может и не быть вовсе. При этом использование потоков вместо процессов позволяет создавать более быстрые программы, за счёт отсутствия необходимости пересылать данные между адресными пространствами.

atd
29.12.2023 11:15+1Замеры были на 12700k /thread
ну и вообще, переводите ещё и комменты к оригинальной статье, там автору уже напихали в панамку за бенчмарк непонятно чего непонятно как
Casus
Если очень нужен питон и по другому ни как, то конечно можно.. но вообще дичь, просто неиспользуйте питон там где не надо.
А то как в известной мысли про молоток и гвозди.
Andrey_Solomatin
Вы точно читали статью?
Все вычисления далаются не на Питоне. В общем Питон вообще можно убрать из заголовка, это будет справедливо для всех языков.
Casus
С чего бы для всех?
С go пропорции рутин и тредов вообще мало кого волнуют, а тех кого волнует не редко пишут на c++/rust.
Проблем с определением количества ресурсов нет, с cgroups тоже, пример: go, jvm, c# и куча прочих.
А если вы про сишную либу под капотом.. ну давайте поговрим о трединге/асинке в php? Там тоже ведь сишные либы подкапотом...
Andrey_Solomatin
В Golang по тем же критериям можно выбирать значение для GOMAXPROCS.
Размер ThreadPool в джаве и С++ тоже нужно как-то устанавливать. Думаете там всё по другому? И они умеют найти нужное количество процессоров изнутри докера?
Если эти либы использовать эффективно, то есть один раз положить туда дынные и один раз достать то скорость будет близка к скорости самой либы. Вне зависимости от языка который это всё оркестрирует. Так всё машинное обучение на Питоне работает.
В любой задаче, где вам нужно будет перемалывать числа, вам придётся подбирать количество процессоров под ваш кейс. Чем более эффективен язык, тем с большей погрешностью это можно делать.