

Всем привет!
Не так давно на Хабре появился занятный пост о разработке процессора, и я понял, что созрел для своей первой статьи как раз в этом направлении.
Тема разработки эмуляторов олдскульных микропроцессоров типа того же Intel 8080 не нова. Если вы уже разбираетесь в вопросе, то для вас этот пост не будет чем-то новым, разве что вы увидите еще один подход к реализации такого проекта. Для тех, кто ничего об этом не слышал – прошу под кат.
Предыстория
Как-то в один из вечеров в августе 2023 года я листал тогда еще стабильно работающий YouTube, и у меня, как, наверное, у многих читателей, лента рекомендаций пестрела в основном техническим материалом разного толка: «GTA 3 Code Review», «Lua in 100 Seconds», «How NASA writes space‑proof code», «6502 CPU Emulator in C++»... Так, стоп, а вот последний ролик кажется интересным!
В этом плейлисте на 35 видео автор с ником Dave Poo показал процесс разработки эмулятора микропроцессора MOS6502 на C++, как, собственно, и говорится в названии. Если не считать пояснительных и вводных роликов, то структура этого плейлиста такая: видео «тесты для инструкции X», видео «реализация инструкции X». Так продолжается до самого конца, пока автор не описал полный набор инструкций MOS6502.
Имея за плечами образование в сфере радиоэлектроники и нереализованные инженерные амбиции, я был крайне заинтересован этим проектом, а поскольку опыта в эмуляторах и ассемблере у меня до этого было ровно ноль, я воспринял эту задачу как личный вызов. Решил попробовать просто повторить проект, но не думал, что эта тема так меня затянет.
Кто такой этот ваш эмулятор?
Для того чтобы ответить на этот вопрос, нужно понять, как работает реальный процессор и каким образом он обрабатывает команды. Здесь точно не будет лекции по микроэлектронике, но к концу прочтения поста вы будете чуть лучше понимать этот процесс, а пока я опишу это в двух словах: у процессора есть регистры для хранения значений (как правило, временных) и декодер инструкций, который понимает какую инструкцию нужно выполнить, и как именно это сделать. Процессор считывает N байт, которыми закодирована инструкция, и выполняет ее в течение M тактов. В результате изменяется содержимое регистров и/или значения в ячейках памяти.
Современные программисты пишут код на языках достаточно высокого уровня: Python, Go, Rust, Ruby, C/C++ и прочих, и я думаю, ни для кого не секрет, что процессор ничего не знает об этих языках. Для того чтобы вы увидели заветный "Hello World!", код на любом языке программирования, даже если он не относится к компилируемым, преобразуется в ассемблер. Даже виртуальная машина Java, какой бы виртуальной она ни была, всё равно работает не в вакууме, а с вполне реальным процессором вашего компьютера. Ассемблер затем преобразуется в машинный код, и вот именно здесь начинается работа декодера и всех связанных с ним сущностей.
Так что же такое эмулятор микропроцессора? Это программа, которая имитирует обработку инструкций реальным процессором, гарантируя при этом корректность его поведения. В эмулятор загружается машинный код, который выполняется точно так же, как его выполнял бы реальный процессор.
Существует несколько классификаций эмуляторов, среди которых есть, например, функциональные, заточенные на точность выполнения инструкций в заданные временные рамки, или, физические, которые точно соблюдают протекающие физические процессы. В данном случае речь идет именно о функциональном эмуляторе.
Путешествие начинается
Первым делом – открываем ISA (Instruction Set Architecture). Это спецификация инструкций для данного процессора. Я пошел вслед за Dave Poo и впервые вбил в поисковик заветную фразу "MOS6502 ISA". Здесь началось мое путешествие в мир 8-битных компьютеров.
Минимальный необходимый функционал для нашего эмулятора такой: чтение/запись в память и декодирование/выполнение инструкций. Начать же нужно со скелета: памяти и процессора. Структуру памяти Memory я реализовал в виде обертки над массивом (даже не std::vector), которая предоставляет интерфейс для операций чтения/записи, поэтому не вижу особого смысла приводить реализацию. Структура процессора, в свою очередь, полностью повторяет своего "железного" собрата:
struct MOS6502 {
WORD PC; // Program Counter
BYTE SP; // Stack Pointer (+ 0x100 offset)
BYTE A; // Accumulator
BYTE X; // X Register
BYTE Y; // Y Register
MOS6502_Status Status; // Status Register
}
struct MOS6502_Status {
BYTE C :1; // Carry Flag
BYTE Z :1; // Zero Flag
BYTE I :1; // Interrupt Disable
BYTE D :1; // Decimal Mode
BYTE B :1; // Break Command
BYTE NU :1; // Not Used
BYTE V :1; // Overflow Flag
BYTE N :1; // Negative Flag
}Здесь описаны регистры процессора, в том числе регистр указателя на текущую инструкцию и регистр указателя на стек, а также регистр статуса. Если посмотреть на страницу в Википедии, то увидим, что схема регистров идентична написанному коду, и отличается разве что порядком:

BYTE и WORD – алиасы для uint8_t и uint16_t соответственно. Просто для удобства.
Структура процессора MOS6502 не раскрыта полностью. Детали будут добавляться по ходу повествования.
Немного ассемблера
Прежде чем мы перейдем к деталям реализации, стоит вернуться чуть назад, к процессору, и рассмотреть работу какой-нибудь конкретной инструкции, чтобы лучше понимать механизмы взаимодействия процессора с регистрами и памятью.
Стоит заметить, что каждой инструкции соответствует свой код, который можно найти в ISA. При этом у каждой инструкции есть своя сигнатура, которая определяет количество аргументов.
В качестве примера возьмем что-нибудь достаточно простое, например, инструкцию AND, которая, как можно догадаться по названию, реализует операцию "Логическое "И", но если посмотреть в ISA, то увидим, что, на самом деле, существует не одна вариация записи этой инструкции:
AND
AND LL
AND LL,X
AND HHLL
AND HHLL,X
AND HHLL,Y
AND (LL,X)
AND (LL),Y
У неподготовленного читателя может возникнуть вопрос: почему для одной операции существует целых восемь вариаций записи. Не стоит бежать впереди паровоза, это всего лишь разные режимы адресации, которые сообщают, откуда брать данные.
На самом деле, восемь режимов адресации – это мало. Современные процессоры насчитывают десятки разных способов обратиться в то или иное место памяти.
Описание инструкции, взятое с очень удобного сайта, гласит, что "инструкция осуществляет побитовое логическое "И" регистра А (аккумулятор) с байтом данных из памяти", таким образом, у программиста из далекого 1975 (или у бесподобного Ben Eater) есть целых (или всего) восемь способов выбрать, откуда именно взять число, с которым к регистру А будет применена операция "Логическое "И". Каждый тип адресации обслуживает свои задачи: одни дают возможность удобно работать с массивами данных, другие позволяют использовать быструю, так называемую нулевую, страницу памяти, третьи позволяют работать с таблицами указателей, но давайте уже перейдем к примерам...
Вносим конкретику
Есть такие задачи, которые нужно разбирать с конца. Во время работы над проектом я этим способом, к сожалению, не воспользовался, но у меня есть возможность подать материал правильно, по крайней мере на бумаге. На примере инструкции AND мы начнем погружаться в работу эмулятора и плавно, вы даже не заметите как, перейдем к тонкостям.
Итак, нам нужна операция "Логическое "И" регистра А с байтом данных, так и запишем:
void GenericAND(MOS6502 &cpu, const BYTE value) {
cpu.A &= value;
}И всё! А вы думали будет что-то более сложное? Правильно, мы же не зря говорили о режимах адресации.
AND
Так называемый Immediate режим, он же "режим с непосредственным операндом", когда операнд (байт данных) располагается сразу после кода инструкции, работает только с константами, не работает с переменными:

В коде такой режим выглядит следующим образом:
AND #$0A ; знак "#" используется как маркер Immidiate-режимаА в эмуляторе реализуется так:
void MOS6502_AND_IM(Memory &memory, MOS6502 &cpu) {
const BYTE value = cpu.FetchByte(memory);
GenericAND(cpu, value);
}Метод FetchByte возвращает следующий после инструкции байт данных, который передается в GenericAND. При таком режиме адресации инструкция выполняется за 2 машинных цикла и занимает 2 байта памяти (код инструкции + байт данных).
Достаточно прямолинейно, не правда ли? Идем дальше!
AND LL
Режим с чтением из "нулевой страницы" памяти (ZeroPage). При таком режиме адресации сразу после инструкции идет также байт, но это уже не значение операнда для операции "И", а адрес этого операнда в нулевой странице. Похоже на обращение к переменной в стеке.
Нулевой страницей называется первая страница памяти с адресами 0x00-0xFF. Этот режим является наиболее экономным по времени выполнения (после Immidiate), потому что значение адреса занимает один байт (вместо двух при абсолютном режиме адресации), а значит, для доступа к конечным данным нужно произвести всего одну дополнительную операцию чтения. По этой причине здесь хранят, как правило, часто используемые данные.

Такой режим адресации в коде будет выглядеть так:
AND $03А в контексте эмулятора так:
void MOS6502_AND_ZP(Memory &memory, MOS6502 &cpu) {
const BYTE value = cpu.GetZeroPageValue(memory);
GenericAND(cpu, value);
}И снова две строчки... Хотя в этот раз вместо FetchByte идет функция GetZeroPageValue. Пусть вас это не пугает, потому что под капотом она делает ровно то, что показано на рисунке выше: читает байт-адрес и получает значение по этому адресу:
BYTE GetZeroPageValue(const Memory &memory) {
const BYTE targetAddress = FetchByte(memory);
return ReadByte(memory, targetAddress);
}Так как добавилась дополнительная операция чтения из памяти, в таком режиме адресации инструкция выполняется уже 3 цикла. В памяти она занимает по-прежнему 2 байта (код инструкции + байт-адрес). Данные в нулевой страницы в сделку не входили в подсчетах не участвуют.
AND LL,X
Все тот же режим адресации нулевой страницы, но уже с индексацией по регистру Х (ZeroPage,X). Это значит, что к адресу нулевой страницы дополнительно будет добавлено смещение из регистра Х. Этот режим, по аналогии с предыдущим, чем-то напоминает массив в стеке. В такой ситуации нужно всего лишь инкрементировать регистр Х, повторяя одну и ту же инструкцию.

В ассемблере такой режим адресации будет записан так:
AND $04,XВ эмуляторе он, как можно догадаться, тоже несильно отличается от предыдущего варианта:
void MOS6502_AND_ZPX(Memory &memory, MOS6502 &cpu) {
const BYTE value = cpu.GetZeroPageValue(memory, cpu.X);
GenericAND(cpu, value);
}Метод GetZeroPageValue вдобавок к получению адреса нулевой страницы выполняет описанную операцию смещения по регистру X:
WORD GetZeroPageAddress(const Memory& memory, const BYTE offsetAddress) {
const BYTE targetAddress = FetchByte(memory);
cycles++;
return targetAddress + offsetAddress;
}
BYTE GetZeroPageValue(const Memory& memory, const BYTE offsetAddress) {
const BYTE targetAddress = GetZeroPageAddress(memory, offsetAddress);
return ReadByte(memory, targetAddress);
}Кто-то уже заметил загадочный инкремент cycles? Этот инкремент эмулирует дополнительный машинный цикл на сложение адреса с регистром Х.
Подробнее о счетчике циклов мы поговорим чуть позже, но я опишу его предназначение в двух словах: я во многом стремлюсь соответствовать ISA, в котором, помимо прочего, указано и количество циклов на инструкцию. Я точно знаю, что, например, инструкция AND в режиме Immediate выполняется за 2 цикла: 1 цикл – на Fetch и 1 цикл – на декодирование. В тестах, вместе с результатом операции, я также проверяю и количество затраченных циклов. Если все совпало, значит, инструкция реализована корректно, а если нет, где-то закралась ошибка.
В таком варианте инструкция все еще занимает в памяти 2 байта (код инструкции + байт-адрес), но выполняется 4 цикла, за счет дополнительного цикла на смещение.
Идем дальше, осталось немного!
AND HHLL
Режим абсолютной адресации (Absolute). В таком режиме в качестве операнда выступает 2-байтовый адрес, из которого будет читаться байт данных для выполнения операции "И". В этом режиме можно получить данные из любого места памяти, поскольку в адресации участвует 2 байта, однако и выполняется эта инструкция дольше. Похоже на обращение к переменной в куче.

В коде этот режим адресации имеет следующий вид:
AND $2000Реализация в эмуляторе уже не должна вызывать лишних вопросов:
void MOS6502_AND_ABS(Memory &memory, MOS6502 &cpu) {
const BYTE value = cpu.GetAbsValue(memory);
GenericAND(cpu, value);
}... ровно как и доступ по адресу:
BYTE GetAbsValue(const Memory& memory) {
const WORD targetAddress = FetchWord(memory);
return ReadByte(memory, targetAddress);
}При таком режиме адресации инструкция занимает в памяти 3 байта (код инструкции + 2 байта адреса) и выполняется в течение 4 циклов.
AND HHLL,X / AND HHLL,Y
Эти две инструкции я решил описать в одном месте, потому что они используют общий механизм действия. Как и в ZeroPage,X, к абсолютному адресу добавляется смещение из индексного регистра. Работает как обращение к массиву в куче.

Ассемблерный вид инструкции в таком режиме выглядит так:
AND $2000,X
или
AND $2000,YРеализация на C++ также не должна вызывать вопросов:
void MOS6502_AND_ABS(Memory &memory, MOS6502 &cpu, BYTE affectingRegister) {
const BYTE value = cpu.GetAbsValue(memory, affectingRegister);
GenericAND(cpu, value);
}
void MOS6502_AND_ABSX(Memory &memory, MOS6502 &cpu) {
MOS6502_AND_ABS(memory, cpu, cpu.X);
}
void MOS6502_AND_ABSY(Memory &memory, MOS6502 &cpu) {
MOS6502_AND_ABS(memory, cpu, cpu.Y);
}Методы доступа к памяти тривиальны:
WORD GetAbsAddress(const Memory& memory, const BYTE offsetAddress) {
const WORD absAddress = FetchWord(memory);
const WORD targetAddress = absAddress + offsetAddress;
if (IsPageCrossed(targetAddress, absAddress))
cycles++;
return targetAddress;
}
BYTE GetAbsValue(const Memory& memory, const BYTE offsetAddress) {
const WORD targetAddress = GetAbsAddress(memory, offsetAddress);
return ReadByte(memory, targetAddress);
}Единственная интересная деталь здесь – проверка IsPageCrossed. В режиме абсолютной адресации со смещением нужно дополнительно проверить, была ли пересечена страница памяти (0xXX00 - 0xXXFF), и если да, то затрачивается лишний цикл. Таким образом, инструкция занимает в памяти 3 байта, и выполняется 4 цикла (+1, если была пересечена страница памяти).
AND (LL,X)
Такой режим адресации называется Indexed Inderect. Он очень похож на ZeroPage,X – мы точно так же читаем байт-адрес нулевой страницы, так же прибавляем к нему смещение из регистра X, но здесь добавляется еще один уровень косвенности – из полученного адреса в нулевой странице мы читаем очередной адрес, из которого уже получим значение операнда. Картинка наводит на мысли о массиве указателей, который находится в стеке.

Давайте здесь повторим словами: прочитать байт данных после инструкции, прибавить к полученному байту значение регистра X, по полученному адресу прочитать два байта абсолютного адреса и уже по полученному адресу взять значение для использования в операции "И". Становится сложновато, но не унывайте, мы почти закончили.
Ассемблер выглядит безобидно:
AND ($04,X)Реализация как всегда в две строчки:
void MOS6502_AND_INDX(Memory &memory, MOS6502 &cpu) {
const BYTE value = cpu.GetIndXAddressValue(memory);
GenericAND(cpu, value);
}Под капотом уже чуть сложнее:
WORD GetIndXAddress(const Memory& memory) {
const BYTE targetAddress = FetchByte(memory) + X;
cycles++;
return ReadWord(memory, targetAddress);
}
BYTE GetIndXAddressValue(const Memory& memory) {
const WORD targetAddress = GetIndXAddress(memory);
return ReadByte(memory, targetAddress);
}В памяти такая инструкция занимает два байта (код инструкции + байт-адрес), но выполняется уже за целых 6 циклов. За дополнительные уровни косвенности нужно платить.
AND (LL),Y
Режим Indirect Indexed не просто так отличается от предыдущего режима лишь порядком слов – в нем немного другой алгоритм действий. Если говорить конкретно – смещение добавляется не к первому прочитанному байту, а к прочитанному из нулевой страницы адресу. Ну и участвует здесь уже регистр Y, а не X. В Indexed Inderect я провел аналогию с массивом указателей, здесь же корректнее будет говорить об указателе на массив, и в качестве индекса выступает регистр Y.

В ассемблере этот режим выглядит следующим образом:
AND ($04),YА в коде эмулятора... ну, впрочем, как всегда:
void MOS6502_AND_INDY(Memory &memory, MOS6502 &cpu) {
const BYTE value = cpu.GetIndYAddressValue(memory);
GenericAND(cpu, value);
}При вычислении адреса также учитывается пересечение страницы памяти:
WORD GetIndYAddress(const Memory& memory) {
const BYTE ZeroPageAddress = FetchByte(memory);
const WORD EffectiveAddress = ReadWord(memory, ZeroPageAddress);
const WORD TargetAddress = EffectiveAddress + Y;
if (IsPageCrossed(TargetAddress, EffectiveAddress))
cycles++;
return TargetAddress;
}
BYTE GetIndYAddressValue(const Memory& memory) {
const WORD TargetAddress = GetIndYAddress(memory);
return ReadByte(memory, TargetAddress);
}Таким образом, инструкция занимает всё те же два байта (код инструкции + байт-адрес) и выполняется за 5 циклов. Здесь так же необходима проверка на пересечение страницы памяти, поэтому к 5 циклам добавляется ещё 1, если была пересечена страница памяти.
Вот мы и разобрали все режимы адресации для инструкции AND. Я не зря уточняю, что именно для нее, поскольку существует еще несколько режимов, которые используются в других инструкциях. Я опишу их кратко, без подробностей:
Implicit – режим, в котором инструкция уже содержит внутри себя все необходимые данные и не требует операндов. К таким инструкциям относят, например, инструкцию
CLC– сброс флага переполнения.Accumulator – режим адресации, который позволяет в качестве операнда передавать регистр аккумулятор. Например, такой режим есть в инструкции
LSR– побитовый сдвиг вправо.ZeroPage,Y – отличается от описанного выше ZeroPage,X только регистром, который используется в качестве индекса.
Relative – специальный режим, который используется в инструкциях ветвления и позволяет задать относительное смещение, в том числе с использованием меток. Например,
BEQ LABELозначает "перейти на метку LABEL если выставлен флаг Zero", причем прыжок можно делать как вперед, так и назад.Indirect – режим адресации, который используется только в инструкции
JMP. Его суть заключается в том, что в качестве операнда передается абсолютный адрес, из которого читается другой абсолютный адрес. Например, если по адресу 0x4000 и 0x4001 записано 0xCD и 0xAB соответственно, то после выполнения инструкцииJMP ($4000)выполнение программы продолжится по адресу 0xABCD (не забываем про обратный порядок следования байтов).
На примере инструкции AND я хотел показать, из каких кирпичиков состоит код в проекте. Надеюсь, мне это удалось. Руководствуясь таким подходом, мне пришлось реализовать 55 инструкций, в каждой из которых было от 1 до 7 режимов адресации, в результате чего получился внушительный набор из 151 функции.
Примечание по реализации инструкций
В коде существует ряд "скрытых" сущностей. Одну из них – счетчик циклов – мы уже видели. Обещаю, совсем скоро мы раскроем эту тему подробнее, но прежде чем мы перейдем к следующему этапу разработки, нужно упомянуть еще одну такую сущность, которая носит название "регистр статуса".
Этот регистр уже упоминался в начале, когда я только-только перешел к описанию кодовой базы, но на всякий случай продублирую:
struct MOS6502_Status {
BYTE C :1; // Carry Flag
BYTE Z :1; // Zero Flag
BYTE I :1; // Interrupt Disable
BYTE D :1; // Decimal Mode
BYTE B :1; // Break Command
BYTE NU :1; // Not Used
BYTE V :1; // Overflow Flag
BYTE N :1; // Negative Flag
}Это структура на битовых полях. Она, как и в реальном процессоре, занимает 1 байт. Каждый бит в этом регистре отвечает за состояние процессора и результат последней операции. Названия флагов раскрыты в комментарии к коду, но я перечислю несколько из них:
Carry Flag – в результате вычислений в последней операции произошел перенос старшего бита.
Zero Flag – результат вычислений последней операции равен нулю.
Interrupt Disable – состояние обработчика прерываний.
Decimal Mode – Режим работы BCD.
и т.д. Пользуясь информацией с уже известного нам сайта, можно узнать, какие флаги меняют свое состояние в результате выполнения инструкции. Если рассматривать инструкцию AND, то увидим, что измениться могут флаги Zero (результат равен нулю) и Negative (результат отрицательный). В предыдущем разделе я показывал реализацию обобщенной функции GenericAND, которая состояла из одной строки. Помните? Я вас обманул. На самом деле, она состоит из двух строк, и я намеренно опустил этот факт, поскольку хотел сохранить ход повествования. Представляю вашему вниманию функцию GenericAND в ее истинном обличии:
void GenericAND(MOS6502 &cpu, const BYTE value) {
cpu.A &= value;
cpu.Status.UpdateStatusByValue(cpu.A, MOS6502_Status_Z | MOS6502_Status_N);
}Функция не сильно изменилась. В нее добавился вызов метода обновления регистра статуса на основе входного значения. В инструкции AND результат хранится в регистре A, соответственно, он передается в качестве первого аргумента. Вторым аргументом передается маска интересующих нас флагов. Ну а реализация, прямо скажем, прямолинейна:
void UpdateStatusByValue(const BYTE &targetRegister, const BYTE mask) {
if (mask & MOS6502_Status_Z)
Z = (targetRegister == 0);
if (mask & MOS6502_Status_N)
N = (targetRegister & MOS6502_Status_N) > 0;
}Вы же видите, что здесь встроена обработка ровно двух флагов? Возможно, здесь кроется архитектурная дыра, но тому есть логичное объяснение. Имея на руках лишь результат вычисления, можно выставить только эти два флага. У остальных флагов есть два пути:
они выставляются и сбрасываются без проверок: например, инструкция CLC принудительно сбрасывает флаг Carry.
им нужны дополнительные вычисления: например, флаги Overflow и Carry в инструкциях сложения (ADC) и вычитания (SBC) вычисляются в реализации и устанавливаются вручную. В этих случаях используется такая функция:
void SetStatusFlagValue(const BYTE statusFlag, const bool value) noexcept {
if (value)
*(BYTE *) (this) |= statusFlag;
else
*(BYTE *) (this) &= ~statusFlag;
}Да, возможно приводить this к BYTE* не самая лучшая идея, но оставим это для комментариев :)
О тестах и тонкостях
Dave Poo в своих роликах использовал разработку через тестирование. В своих домашних проектах я таким подходом не пользовался, поэтому ради разнообразия решил пойти по тому же пути.
В проекте используется GoogleTest, а тест выглядит как небольшой слепок памяти, на основе которого составляются гипотезы о конечном состоянии процессора после выполнения составленной микропрограммы.
Раз уж мы начали рассматривать инструкцию AND, то посмотрим на связанные с ней тесты. Вот код для теста инструкции AND ABS:
class MOS6502_ANDFixture : public MOS6502_TestFixture {
public:
...
void AND_ABS_CanDoAND(BYTE initialValue, BYTE memoryValue) {
// given:
cpu.A = initialValue;
mem[0xFFFC] = 0x00;
mem[0xFFFD] = 0xFF;
mem[0xFF00] = AND_ABS;
mem[0xFF01] = 0x80;
mem[0xFF02] = 0x44;
mem[0xFF03] = STOP_OPCODE;
mem[0x4480] = memoryValue;
cyclesExpected = 4;
// when:
cyclesPassed = cpu.Run(mem);
// then:
EXPECT_EQ(cpu.A, memoryValue & initialValue);
CheckCyclesCount();
}
...
}
...
TEST_F(MOS6502_ANDFixture, AND_ABS_CanDoAND) {
AND_ABS_CanDoAND(0xFF, 0xF);
}
TEST_F(MOS6502_ANDFixture, AND_ABS_CanAffectZeroFlag) {
AND_ABS_CanDoAND(0xFF, 0x0);
EXPECT_TRUE(cpu.Status.Z);
}
TEST_F(MOS6502_ANDFixture, AND_ABS_CanAffectNegativeFlag) {
AND_ABS_CanDoAND(0xFF, 0xFF);
EXPECT_TRUE(cpu.Status.N);
}
...Здесь явно нужны пояснения.
Метод AND_ABS_CanDoAND в Fixture-классе содержит в себе тело теста и тот самый микрокод, о котором мы говорили чуть выше. Метод нужен, просто чтобы избежать дублирования кода в аналогичных тестах с разными входными параметрами – я думаю, это не вызывает вопросов.
В качестве аргументов в метод передается исходное значение регистра А и значение в памяти, с которым будет производиться операция "Логическое "И". Заранее скажу, что я не особо разбираюсь в теме написания тестов, но старался оформлять их по GWT.
Секция given
В этой секции мы устанавливаем исходное состояние системы.
Первым делом запишем исходное значение регистра А, и если здесь вопросов нет, то дальше их не избежать, потому что мы переходим к "слепку памяти", и эту часть нужно начать с небольшого пояснения.
Первые два адреса выбраны совершенно не случайно, и вот почему: согласно документации, в момент подачи питания на микропроцессор, он читает стартовый адрес программы из строго определенного адреса – это FFFC/FFFD, соответственно, первым делом мы записываем в эти ячейки уже любой понравившийся нам адрес, с которого начнется выполнение программы. Это сделано с целью сохранения совместимости с реальными программами.
Запишем в FFFC/FFFD значение 00FF, что даст нам адрес FF00 (помним про обратный порядок байтов?).
По адресу FF00 пишется AND_ABS, это код инструкции (реализован в виде enum), который имеет значение 0x2D.
Далее в FF01/FF02 идет адрес, откуда будет читаться значение для операции "И", записанный в обратном порядке, это 0x80 и 0x44 соответственно (образует адрес 4480).
В адрес 4480 записывается значение операнда для инструкции, сюда подставляется второй аргумент, переданный в метод.
Далее в FF03 идет загадочный STOP_OPCODE.
В самом конце устанавливаем значение ожидаемого количества циклов, с которым впоследствии будем сравнивать реальное количество циклов, выданное нашим эмулятором.
Погодите, а что такое STOP_OPCODE? На самом деле, такого понятия не существует. Это своеобразное ухищрение, призванное завершить работу эмулятора. Так совпало, что в таблице инструкций для MOS6502 имеются пустые места, и я, недолго думая, зарезервировал одно из них для себя, как сигнал о том, что эмулятор должен закончить свою работу.
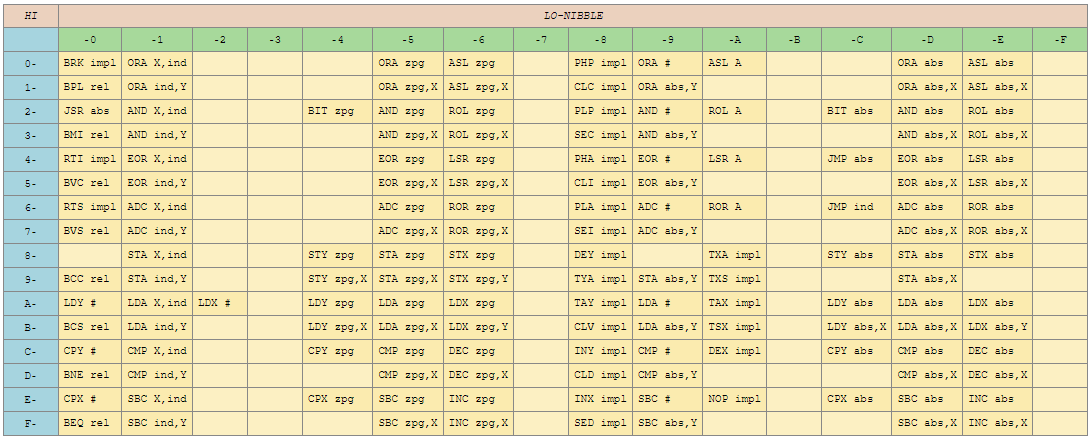
Как можно заметить, здесь достаточно много пустых ячеек. Есть также расширенный список, который занимает уже всю таблицу, и в нем основной набор инструкций дополнен так называемыми "нелегальными" инструкциями. Как я ни бился, так и не смог понять, что же это значит, но как минимум я узнал, что такие инструкции поддерживают только какие-то специфичные чипы, поэтому на данный момент я их поддержку не внедрял.
Секция when
В этой секции перечисляются действия, которые изменят состояние системы. В нашем случае это одна единственная строчка с вызовом метода Run для нашего процессора:
...
// when:
cyclesPassed = cpu.Run(mem);
...Этот метод, как несложно догадаться, запускает работу эмулятора и возвращает реальное количество циклов, затраченное на выполнение программы. Мы снова затрагиваем счетчик циклов, но его, как и сам метод Run, мы разберем чуть позже, а пока давайте примем это просто как данность. Прошу об этом в последний раз, честное слово!
Секция then
Здесь проверяется итоговое состояние процессора. В обобщенном методе AND_ABS_CanDoAND проверяется корректность результата операции и равенство ожидаемого и реального количества циклов. В индивидуальных тестах проверяются дополнительные состояния. Так, например, в тесте AND_ABS_CanAffectZeroFlag при аргументах 0xFF и 0x00, где результат равен нулю, проверяется состояние флага Z в регистре статуса, который, очевидно, должен быть равен единице.
Исполнение кода и счетчик циклов
Поздравляю! Вы дочитали до момента, где все станет еще сложнее интереснее! Итак, начнем с простого.
Счетчик циклов
Не секрет, что на каждую операцию процессору необходимо время. Это время выражается в машинных циклах, которые, в свою очередь, состоят из тактов. Неочевидный факт – в одном машинном цикле нефиксированное количество тактов. Почему так? Потому что одним машинным циклом описывают каждую примитивную операцию, но при этом каждая такая операция требует разное количество тактов. Запись байта в регистр – примитивная операция, ровно как и запись байта в память. Они занимают один машинный цикл, но при этом разное количество тактов. Как-то так...
В коде структуры MOS6502 вы счетчик не увидели, хотя я явно обращаюсь к нему как к полю, заметили? Да, всё так. Код уже успел претерпеть ряд существенных изменений, и структура микропроцессора стала классом, унаследованным от базовой реализации, и вот там уже лежит наша переменная U32 cycles.
Этот счетчик был введен, чтобы хоть как-то контролировать количество циклов, и он, как и полагается, инкрементируется в каждой элементарной операции. Вот несколько банальных примеров:
BYTE FetchByte(const Memory &memory) {
const BYTE Data = memory[PC++];
cycles++;
return Data;
}
WORD FetchWord(const Memory &memory) {
const BYTE Lo = FetchByte(memory);
const BYTE Hi = FetchByte(memory);
return Lo | (Hi << 8);
}
BYTE ReadByte(const Memory &memory, const WORD address) {
const BYTE Data = memory[address];
cycles++;
return Data;
}Я думаю, пояснения здесь излишни. Как уже говорилось – каждая примитивная операция сопровождается инкрементом счетчика циклов. Внеочередной инкремент в режимах адресации уже был продемонстрирован. Также если по ходу выполнения инструкции совершается дополнительное действие, то я так же инкрементирую счетчик по месту.
Например, дополнительный инкремент в операции битового сдвига:
void MOS6502_LSR_ACC(Memory &memory, MOS6502 &cpu) {
const bool Carry = cpu.A & 1;
cpu.A <<= 1;
cpu.cycles++;
cpu.Status.UpdateStatusByValue(cpu.A, MOS6502_Status_Z | MOS6502_Status_N);
cpu.Status.C = Carry;
}А вот еще один пример из набора инструкций по установке определенного флага регистра статуса:
void GenericSE(MOS6502 &cpu, const BYTE statusFlag) {
cpu.Status.SetStatusFlagValue(statusFlag, true);
cpu.cycles++;
}
void MOS6502_SEC_IMPL(Memory &memory, MOS6502 &cpu) {
GenericSE(cpu, MOS6502_Status_C);
}
void MOS6502_SED_IMPL(Memory &memory, MOS6502 &cpu) {
GenericSE(cpu, MOS6502_Status_D);
}
void MOS6502_SEI_IMPL(Memory &memory, MOS6502 &cpu) {
GenericSE(cpu, MOS6502_Status_I);
}Здесь всё вполне логично, но есть пара нюансов, о которых стоит упомянуть.
Существует ряд инструкций, которые как будто бы не затрачивают дополнительных машинных циклов, по крайней мере, судя по ISA и официальной технической документации. Помните реализацию инструкции AND? Там нет инкремента. У вас, возможно, пока недостаточно познаний, чтобы согласиться или не согласиться со мной, но я объясню на примере:
Инструкция AND в Immediate режиме занимает 2 машинных цикла: 1 цикл – на чтение и декодирование самой инструкции, и 1 цикл – на чтение байта из памяти. Всё! Циклы, судя по документации, закончились. А где цикл на логическое "И" или хотя бы на запись результата в регистр? Еще один пример – инструкция сравнения CMP. Количество затрачиваемых машинных циклов в ней точно такое же, как и в инструкции AND, хотя в CMP для сравнения используется вычитание, которое вроде как не бесплатно...
Теоретически я могу представить инженерное решение, при котором значение запишется в регистр одновременно с вычислением, но подтверждения этой догадки я так и не нашел.
Однако! Есть ситуации, когда циклов не хватает! Если мы смогли выработать, пусть и теоретическое, решение для ситуаций, когда инструкция как будто не затрачивает циклы, то в проекте есть как минимум два связанных места, где происходит перерасход циклов. Я долго бился над этой задачей, но так и не смог найти решение. Давайте покажу, в чем тут дело.
Имеется инструкция вызова программного прерывания и инструкция возврата из подпрограммы этого прерывания:
void MOS6502_BRK_IMPL(Memory &memory, MOS6502 &cpu) {
cpu.PushProgramCounterToStack(memory);
cpu.PushStatusToStack(memory);
cpu.PC = cpu.ReadWord(memory, 0xFFFE);
cpu.Status.SetStatusFlagValue(MOS6502_Status_B, true);
cpu.cycles--; // temporary fix extra cycle
}
void MOS6502_RTI_IMPL(Memory &memory, MOS6502 &cpu) {
cpu.PopStatusFromStack(memory);
cpu.PC = cpu.PopAddressFromStack(memory);
cpu.Status.SetStatusFlagValue(MOS6502_Status_B, false);
cpu.cycles--; // temporary fix extra cycle
}Уже увидели этот загадочный декремент с соответствующим комментарием? Все мои попытки докопаться до истины обернулись полным провалом. Я перепроверил все вызываемые функции в надежде на то, что я просто где-то что-то упустил, но везде все выставлено корректно. Не сходится,и всё тут! Как говорится "запишем в бэклог".
Для чего, вообще, сделан счетчик циклов? На данный момент этот счетчик – просто счетчик, который выдается нам после работы программы, и в текущей реализации он нужен только для тестов, а сам эмулятор работает на всю катушку хост-процессора. В будущем я хочу перевести весь эмулятор на систему тактирования, чтобы можно было запускать на нем программы, в которых многое завязано на таймингах, например, игры. Вы же знаете, что MOS6502 был основой многих приставок?
Исполнение кода
Перед вами – самый лакомый кусочек представленного эпоса. Мы разобрали каждый мелкий блок, из которого состоит эмулятор, рассмотрели концепции, вокруг которых строится вся функциональность, увидели неточности и недоработки, но все еще есть какое-то чувство неполноценности. Как будто бы все хорошо работает по отдельности, но неясно как оно связано между собой. Я верно описал ваши чувства?
Давайте, наконец, рассмотрим метод, который является самым главным во всем эмуляторе, потому что именно он реализует работу микропроцессора:
U32 MOS6502::Run(Memory &memory) {
PC = (memory[0xFFFD] << 8) | memory[0xFFFC];
bool DecodeSuccess;
do {
const BYTE opCode = FetchByte(memory);
DecodeSuccess = DecodeInstruction(opCode, memory, *this);
} while (DecodeSuccess);
cycles--; // revert fetch cycle
PC--; // revert extra PC increment of last fetch
return cycles;
}Мы уже знаем, что процессор первым делом читает стартовый адрес из FFFC/FFFD и складывает полученное значение в регистр указателя на инструкцию PC. После этого начинается бесконечный цикл Fetch->Decode, который прерывается, если декодирование закончилось ошибкой.
Метод FetchByte мы уже видели, но я на всякий случай продублирую:
BYTE FetchByte(const Memory &memory) {
const BYTE Data = memory[PC++];
cycles++;
return Data;
}Здесь происходит следующее: мы читаем байт из адреса, который хранится в регистре PC, после чего инкрементируем регистр и возвращаем прочитанный байт. Таким образом, с каждым фетчем мы будем смещаться вперед, за счет чего и обеспечивается последовательное чтение кода.
Да, чтение происходит только вперед, но никто не отменял инструкции перехода типа JMP, так что если мы начали выполнение с адреса FFF0, то это еще не значит, что в 16-разрядной памяти, где адреса заканчиваются на FFFF нам доступно всего 16 циклов выполнения.
Прочитанный байт передается в декодер, но прежде чем мы перейдем к нему, стоит объяснить, что значит "ошибка декодирования". Помните STOP_OPCODE? Он нужен именно для отслеживания этой ситуации: эмулятор будет работать либо бесконечно (если так задумано загруженной программой), либо до момента, пока он не встретит STOP_OPCODE (или любой другой опкод, которому не соответствует ни одна инструкция).
При выходе из цикла мы откатываем последний неудачный фетч и возвращаем количество циклов. Ну а теперь вишенка на торте!
Декодер
Вы хотя бы примерно представляете, как работает декодер? Это такой своеобразный черный ящик, которому на вход подается код инструкции (число), а внутри происходит выполнение этой самой инструкции. Звучит вроде несложно. А если разобраться?
В большинстве проектов эмуляторов, что я видел, декодер сделан на switch-case. Удивляет? Меня удивило. Для MOS6502 я еще хоть как-то могу представить такую реализацию, ведь инструкций с учетом всех режимов всего 151. Стоит ли пытаться передать свои эмоции, когда я увидел switch-декодер в эмуляторе Intel 8086, в котором с учетом режимов адресации получается несколько тысяч инструкций? Боюсь даже представить, как можно поддерживать такое огромное количество строк достаточно хитрого кода!
Dave Poo в своих видео не отличался от остальных и тоже начал с реализации на switch-case. Поначалу я пошел вслед за ним, а потом вдруг понял, что мне такой подход не нравится. Я представил трудности отладки, объемы кода, сложенного в одном месте, и решил разработать свой подход для решения этой задачи.
Я недолго думал над реализацией, и моя версия пережила ровно одну итерацию. Несложно догадаться, какой была первая, потому что тогда я подумал так: "У меня есть число, и этому числу соответствует функция". Каким может быть первое наивное решение? Конечно же, хэш-таблица. В тот вечер я с гордостью написал следующее:
std::map<BYTE, std::function<void(MOS6502&,Memory&)>> InstructionTable = { ... };Нужно ли описывать недостатки этого решения? Скорость, объем занимаемой памяти, накладные расходы на разворачивание std::function... А теперь давайте переработаем мою первую мысль: у нас есть не просто число, а вполне конкретный список чисел, каждому из которых соответствует вполне конкретная функция. Уже догадались, какой стала вторая и последняя итерация? Таблица вызовов!
Уже год эта конструкция выглядит следующим образом:
static void MOS6502_INVALID_OP(Memory&, MOS6502&) {}
using OpSignature = void (*)(Memory&, MOS6502&);
constexpr static OpSignature Ops[] =
{
#ifndef ADD_CALL
# define ADD_CALL(call) MOS6502_##call
# include "MOS6502/MOS6502_OpCodesList.h"
# undef ADD_CALL
#endif
};По порядку:
функция
MOS6502_INVALID_OPявляется заглушкой для всех неиспользуемых опкодов, в том числе для STOP_OPCODE.OpSignature– алиас для указателя на функцию, которая принимает ссылку на память и ссылку на процессор.constexpr static OpSignature Ops[]– таблица вызовов (массив указателей на функцию).
Конечно же, я не хотел вручную заполнять таблицу на 256 записей, поэтому написал макрос, который генерирует мне эту таблицу на этапе препроцессора. Макрос подхватывает файл OpCodesList и разворачивает ADD_CALL в объявление массива. Сам файл выглядит следующим образом:
ADD_CALL(BRK_IMPL), ADD_CALL(ORA_INDX), ADD_CALL(INVALID_OP),
ADD_CALL(INVALID_OP), ADD_CALL(INVALID_OP), ADD_CALL(ORA_ZP),
ADD_CALL(ASL_ZP), ADD_CALL(INVALID_OP), ADD_CALL(PHP_IMPL),
ADD_CALL(ORA_IM), ADD_CALL(ASL_ACC), ADD_CALL(INVALID_OP),
ADD_CALL(INVALID_OP), ADD_CALL(ORA_ABS), ADD_CALL(ASL_ABS),
...Конечно же, этот файл я тоже не хотел заполнять вручную. Его заполняет скрипт, написанный на Python, который, в свою очередь, парсит файл с enum, где перечислены опкоды. В общем, я облегчил себе работу настолько, насколько хватило фантазии.
А где же сам декодер? Да вот же он!
bool DecodeInstruction(const BYTE opcode, Memory &memory, MOS6502 &cpu) {
const auto &instruction = Ops[opcode];
if(opcode == STOP_OPCODE || instruction == MOS6502_INVALID_OP)
return false;
instruction(memory, cpu);
return true;
}Я надеюсь, сейчас ни у кого не возникает вопроса, зачем я писал все эти пояснения. Да, декодер занимает пять строчек кода, но теперь мы прекрасно понимаем назначение каждой из этих пяти строк: взяли по индексу интересующий нас указатель на функцию (инструкцию); определили является ли код инструкции валидным; выполнили инструкцию.
Прочитав весь этот текст, может показаться, что декодер, ядро эмулятора, выглядит до жути элементарным, и это ровно то, чего я добивался. Самое время перейти к послесловию.
Текущее состояние и планы
Сейчас я активно пытаюсь привлечь в проект неравнодушных людей, но из-за специфики направления, очевидно, испытываю с этим некоторые проблемы.
Одним проект в принципе не интересен, и таких людей я прекрасно понимаю: сложно испытывать интерес к битам и байтам в эпоху метапрограммирования. Другие интересуются, но не справляются с достаточно высоким порогом входа – нужно потратить определенное количество времени, внимания и сил, чтобы вкатиться в проект, и не потерять при этом интерес. Есть те, кто оказывает разовую помощь в том или ином вопросе, но все же моя цель – собрать вокруг проекта пусть и небольшое, но комьюнити.
На данный момент (начало октября 2024) проект находится в разработке чуть больше года. Репозиторий проекта лежит на домашнем GitLab с зеркалированием в GitHub, есть небольшая доска Trello, где набрасываются задачи.
Проектом я занимаюсь в свободное от основной работы время, и вот в каком состоянии проект сейчас:
MOS6502: полный набор инструкций, покрытие тестами, запуск небольших программ (например, расчет контрольной суммы CRC 8/16/32), возможность запускать свои программы, используя vasm.
I8080: полный набор инструкций, покрытие тестами.
I8086: начата работа над реализацией инструкций, готов декодер и обработка режимов адресации.
Планы по развитию грандиозные, причем позволяют расти как вертикально (повышение функциональности модулей процессоров и построение на их основе полноценных систем типа PPU), так и горизонтально (добавлять модули новых микропроцессоров типа Motorolla 68000 или Zilog Z80), при этом одной из ключевых целей роста я считаю разработку способа интерактивного взаимодействия с эмулятором, т.е. эмуляция хардварного ввода/вывода, чтобы запустить, например, интерпретатор BASIC.
На этом мой эпос окончен. Спасибо за уделенное время. Всех жду в комментариях! Контакты для связи в Telegram: @dimanchique, ну и конечно же, старая добрая почта.
Комментарии (16)

beeruser
15.10.2024 17:05В большинстве проектов эмуляторов, что я видел, декодер сделан на switch-case. Удивляет?
Не нужно думать, что вы умнее всех остальных разработчиков эмуляторов.
Switch/case это самое оптимальное решение, как раз потому, что код сложен в одном месте.
Уже догадались, какой стала вторая и последняя итерация? Таблица вызовов!
Компилятор превращает switch/case в таблицу автоматически.
Рекомендую ознакомиться с этим проектом (потактовый эмулятор 6502)
https://github.com/floooh/chips/blob/master/chips/m6502.h
Легко читать, легко понять.
построение на их основе полноценных систем
Тем более нужен потактовый эмулятор, потому что результат может меняться в зависимости от того, на каком такте команды вы запишете данные в регистр железки (или в память).

vadimr
15.10.2024 17:05На самом деле любой код операции в 6502 имеет предопределённую семантику, просто некоторые документированы, а некоторые нет. Если рассмотреть систему команд 6502 на более низком уровне, то отдельные биты в кодах команд отвечают за определённые микрооперации, исходя из чего и получается операционная семантика команды в целом.
В любом случае, вешать останов эмулятора на какой-то код команды – плохое для практического использования решение, потому что ситуация, когда исполнение начинает гулять по случайным байтам – не редкость. Архитектура 6502 гарантирует, что мы остановимся при этом на первом BRK (вот только не помню, нет ли дополнительных недокументированных опкодов у BRK, помимо $00).




sergeiiurtaev
15.10.2024 17:05Отличный проект. Спасибо что поделились. На старых процессорах хорошо если: register, direct, indirect, indexed - есть вообще. На старом Intel встречал: можно 8 bit , а можно - 16 bit двумя регистрами.

artptr86
15.10.2024 17:05А почему
MOS6502_Statusсделан байтами, а не битовыми полями? Как раз слово состояния процессора автоматически получилось.
sappience
15.10.2024 17:05Именно битовыми полями и сделан.
struct MOS6502_Status { BYTE C :1; // Carry Flag BYTE Z :1; // Zero Flag BYTE I :1; // Interrupt Disable BYTE D :1; // Decimal Mode BYTE B :1; // Break Command BYTE NU :1; // Not Used BYTE V :1; // Overflow Flag BYTE N :1; // Negative Flag }Тут единичка после двоеточия означает, что переменной из всего BYTE отведен только один бит.

axe_chita
15.10.2024 17:05Нельзя не напомнить, об одном из первопроходцев эмуляторостроения Марате Файзулине, и его странице посвященной эмуляции разных систем. Так же на этой странице находится статья "Как написать эмулятор Компьютера"

Gumanoid
15.10.2024 17:05У его коллеги тоже есть интересные статьи про эмуляцию, например «Семь видов интерпретаторов виртуальной машины. В поисках самого быстрого».
SIISII
В порядке "стилистических" придирок: лучше избегать таких типов, как WORD, потому что их трактовка различается от платформы к платформе. На ПК исторически сложилось, что слово = 16 разрядов независимо от разрядности процессора, но, скажем, на 32-разрядных ARM слово -- таки 32 бита, ну а на том же 6502 слов на уровне терминологии вообще не было. Так что я предпочитаю, чтобы разрядность подобных типов прямо у них и указывалась (лично я использую всякие там int8/uint8 и т.д. и т.п.).
Насчёт "множества режимов адресации": восемь -- это много, лишь немногие архитектуры имели больше, ну а десятков действительно разных режимов, возможно, нигде никогда и не было. Нет, если считать за разные виды адресации один и тот же вид, но с разными регистрами, то можно и сотни насчитать -- но разными они таки не будут.
Ну и, наконец, эмуляция процессора -- это хорошо, но она приобретает смысл лишь в случае эмуляции целого компьютера -- и таких проектов весьма много. А без этого... Ну, сделали выполнение команд, и что дальше? Даже не поиграешь в какую-нибудь древнюю игрушку для Эпла-2, Денди или нашего Агата, которые как раз на 6502 были :)
rukhi7
если считать для всех видов инструкций и для всех типов памяти например в AVR архитектуре то больше десятка насчитать наверно можно, там для разных диапазонов памяти свои инструкции. Например к регистрам можно обращаться как к памяти по адресу а можно как к регистрам, в самих регистрах есть веделенный диапазон с которым могут работать только определенные инструкции, память IO регистров - это другой специальный тип памяти там тоже есть спец-режимы для разных областей, а еще есть память программ в которой тоже можно данные хранить и есть спец инструкции для их извлечения, еще есть еeprom память, память подключаемая по внешней шине... Это то что помню навскидку.
SIISII
Десяток -- да, но не несколько десятков, думаю. В VAX-11, кажется, 12 было. В AVR8 -- да, примерно как Вы написали (точно уж не помню, писал под неё только один раз на асме, хоть и коммерческий проект был -- но 10+ лет назад, подробности, есно, давно выветрились).
А вот если говорить о памяти, подключаемой как внешнее устройство (скажем, EEPROM на I2C), то проц об этом ничего не знает и никаких особых видов адресации не имеет: там доступы выполняются к регистрам контроллера I2C или какая там шина используется.
vadimr
Насколько я помню, у 6502 было 13 документированных режимов адресации. Правда, были среди них и такие, которые, например, использовались только одной командой. И, действительно, 13 и даже 8 – это много.
Другое дело, что конкретно мнемокод AND допускает 8 документированных режимов адресации.