

Давным-давно,
NB перестал спрашивать, видимо, опасаясь раздражать явно более опытного собеседника.NB: - А как привести много посетителей на свой новый сайт?
GURU: - Ну можно ссылок «раскидать» на разных форумах и в соц. сетях. Поисковая оптимизация поможет и контент. Можно тизерные сети привлечь, а можно много раз посетить сайт через разные прокси ...
NB: - И чем же помогут такие посещения, ведь это иллюзия живых людей?
GURU: - Счетчик статистики от google или от yandex объяснит поисковикам, что сайт становится популярным. Да еще и реферер можно связать с посещаемыми сайтами по запросам. Подрастет позиция в поисковиках, а значит и подрастет поисковый трафик.
NB: - А где же взять такое количество прокси?
GURU: - Где?… Ну в интернете поищи...
GURU закатил глаза, как бы подчеркивая исчерпанность темы про прокси и замолчал…
Разумеется, GURU знал, что поисковый запрос (например по слову: прокси) очень скоро приведет NB к получению желаемого списка «адрес: порт». Но после первых экспериментов NB, так же быстро, поймет:
- Не все адреса в его списке рабочие;
- Не все прокси одинаково хороши;
- «Накликивать» сайт через прокси вручную — задача, требующая значительной воли;
- «Не правильный» прокси навредит ситуации, т.к. сайт может быть заподозрен скриптами гигантов в накрутке.
В этом материале я расскажу о том, как подручными (а главное универсальными) средствами
(без использования специфического проприетарного ПО, такого как ZennoPoster и пр… )
построить автоматизированный инструмент по получению списка «действительно годных» прокси и использованию их для организации (автоматизированного) посещения продвигаемого
сайта при помощи браузера Chrome.
Следуя инструкции, вы получите готовый инструмент, который позволит:
- «click»-ать (посещать) целевой сайт полностью автоматически, не опасаясь компроментации;
- полностью эмулировать поведение пользователя;
- организовать все посещения по расписанию (сценарию);
- делать все вышеописанное в необходимом для продвижения количестве раз.
И хотя вся моя работа (вместе с исследованиями) заняла неделю, вам не потребуется и двух дней, чтобы построить такой инструмент, обладая базовыми знаниями о командной строке, PHP и JavaScript.
Однако, до того как вы пролистаете ниже следующей схемы, скажу пару слов о том, для чего и для кого подготовлен этот материал.
Материал будет полезен в том случае, если вы хотите разобраться как устроены конструкции (? или конструкторы?) при помощи которых можно относительно быстро построить приложение, легко и без затрат адаптируемое к изменению нагрузки. Если вас интересует возможность построения приложения на основе сервисной шины (ESB).
Текст будет полезен, если вы хотели поближе познакомиться с применением Docker для мгновенного построения систем. Или же если вам просто интересен Selenium Server и нюансы получения контента/проявления HTTPx активности.
Для «использования сразу», вдумчиво читать все это не стоит. Код уж точно.
Одна для инфраструктуры (docker), другая для управления процессом (process).
Предполагается, что на docker уже установлены следующие пакеты:
git, docker, docker-compose
Предполагается, что на process уже установлены следующие пакеты:
git, php-common, php-cli, php-curl, php-zip, php-memcached, composerЕсли на этом месте у вас возникли вопросы, предлагаю затратить 15 минут на прочтение всего материала полностью.
docker
# Все действия предполагают root-привилегии.
# Предполагается, что не заняты следующие TCP-порты:
# 11300, 11211, 4444, 5930, 8080, 8081, 8082, 8083
# Клонировать репозиторий с инфраструктурой в домашний каталог
# "не root-пользователя" и запустить контейнеры
git clone https://oauth2:YRGzV8Ktx2ztoZg_oZZL@git.ituse.ru/deploy/esb-infrastructure.git
cd esb-infrastructure
docker-compose up --build -d
# Вам потребуется чашка кофе и 3 минуты терпения после окончания
# процесса старта контейнеров.
# Примерно столько времени необходимо на развертывания web-панелей.
process
# Все действия предполагают привелегии обыкновенного пользователя.
# Клонировать репозиторий с проектом на process-машину в любой каталог,
# доступный для записи и до-установить необходимые php-пакеты
git clone https://oauth2:YRGzV8Ktx2ztoZg_oZZL@git.ituse.ru/deploy/clicker-noserver.git
cd clicker-noserver
composer update
# Сконфигурировать приложение. Для это в файле заменить строки "XXXXXXXX"
mv app/settings.php.dist app/settings.php
# Запустить обработчики очередей.
gnome-terminal --tab -e 'bash -c "php app/src/Process/noserver/singleProcess.php curl"' --tab -e 'bash -c "php app/src/Process/noserver/singleProcess.php timezone"' --tab -e 'bash -c "php app/src/Process/noserver/singleProcess.php whoer"'
# Дать задание. Предполагается, что файл со списком прокси,
# формата адрес:порт - log/list.proxy
php app/src/Utils/givethejob.php ./log/list.proxy
Ждать, наблюдая за происходящим через web-панель (http://ip-адрес-докер-машины:8080).
Результат будет доступен в очереди located.
Дробление и планирование
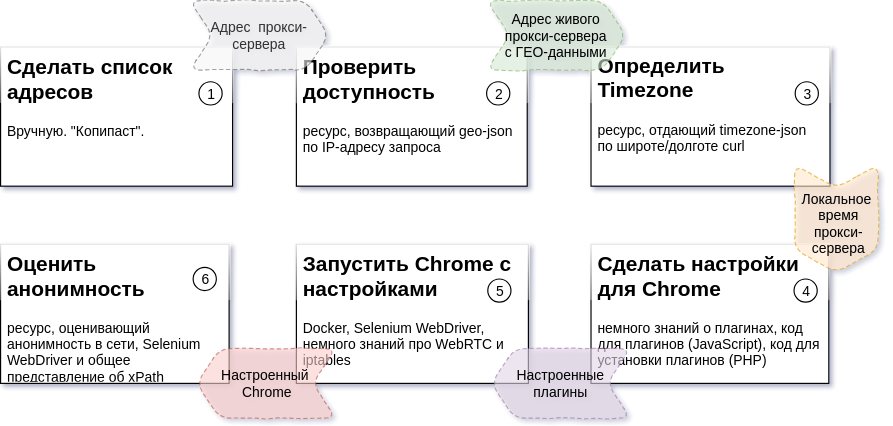
На схеме, приведенной выше, описана последовательность шагов процесса, ожидаемый результат для каждого шага и ресурсы, которые потребуются для создания каждой из частей (подробности: Задача 2, Задача 3, Задача 4,5,6).
В моем случае все происходит на двух машинах Ubuntu 18.04. Одна из них управляет процессом. На другой запущены несколько Docker-контейнеров инфраструктуры.
Отговорки и отказы
Весь код пакета состоит из трех частей.
Одна из них — не моя (отмечу, что это аккуратный и красивый код). Источник этого кода packagist.org.
Другую писал уже я сам, старался сделать ее понятной и посвятил этой части кода примерно неделю.
Остальное — «нелегкое историческое наследие». Эта часть кода создавалась на протяжении довольно длительного времени. В том числе в тот период, когда я еще не имел большой сноровки в программировании.
Именно в этом кроется причина расположения репозиториев на моем GitLab и пакетов на моем Satis. Для публикации на GitHub.com и packagist.org этот код потребует обработки и более тщательного документирования.
Все части кода открыты для неограниченного использования. Репозитории и пакеты будут доступны «вечно».
Однако, при ре-публикации кода, я буду признателен вам за размещение ссылки на меня либо на эту статью.
Немного об архитектуре
Подход, который был применен для создания нашего инструмента – написание (либо использование готовой) утилиты для решения каждой конкретной задачи. При этом каждая утилита, вне зависимости от решаемой задачи обладает двумя общими для всех свойствами:
- утилита может быть запущена независимо от остальных из командной строки с параметрами, содержащими задание;
- утилита может вернуть результат выполнения в stdout (будучи сконфигурирована определенным способом).
Решение, выполненное по такому принципу, позволяет менять количество запущенных обработчиков задач (воркеров) для каждого из шагов процесса. Разное количество воркеров для каждого шага приведет к «0» времени простоя шагов последующих из-за длительности обработки задач шагов предыдущих.
Время, затраченное на получение единицы результата процесса (в нашем случае это проверенный прокси) зависит от внешних факторов (количества негодных прокси, времени ответа внешнего ресурса и пр.).
Изменяя количество воркеров для каждого из шагов процесса, мы трансформируем эту зависимость в зависимость от количества запущенных воркеров (т.е. в зависимость от привлекаемых вычислительных и канальных мощностей).
Для синхронизации работы отдельных независимых частей удобно использовать сервер очередей обмена сообщениями в качестве единой шины данных. Он позволит накапливать результаты завершившихся шагов в очереди и отдавать их утилите «следующего шага» в нужный момент в качестве входных данных.
Очередь обмена сообщениями. MQ и ESB
В качестве нижнего уровня (MQ) мы будем использовать beanstalkd. Маленький, легкий, не требующий конфигурации, доступный в deb-пакете и в Docker-контейнере, незаметный труженик. Логический же уровень (ESB), будет осуществлять код на PHP.
Для реализации будут использованы два класса. esbTask и nextStepWorker.
esbTask
class esbTask // Вагонетка с данными, несущаяся по рельсам процесса
{
// immutable-класс;
// "Конверт" (обертка на основе ESB-подходов), содержащий payload
// Сериализуется и десериализуется
// Реализует различные функции конфигурации "конверта"
....
}
Экземпляр этого класса служит для «адресации» paylod'а сквозь шаги процесса. В концепции ESB применены несколько принципов/паттернов. На два из них стоит обратить внимание отдельно:
- О пути (последовательности шагов) процесса, в каждый момент времени реализации процесса,
не знает никто кроме передаваемого конверта;
- Каждый конверт имеет три возможных направления исхода:
- следующий шаг процесса (нормальное продолжение);
- шаг остановки (мишень остановки — выбирается следующим шагом, в случае отсутствия смысла в продолжении процесса/stop-ситуации);
- шаг ошибки (мишень аварийного завершения — выбирается следующим шагом, в случае ошибки воркера).
// json-представление esbTask
{
// Идентификатор десериализуемого класса (один из потомков esbTask)
"_type":"App\\\\rebean\\\\payloads\\\\ESBtaskQueue",
// Адрес
"task":"task:queue@XXX.XXX.XXX.XXX:11300",
// Следующие шаги процесса (опционально)
"replyto":[
"othertask1:nextqueue1@yyy.XXX.XXX.XXX:11300",
"othertask2:nextqueue2",
"othertask3:nextqueue3",
],
// Мишени для ошибок (опционально)
"onerror":[
"error:errorsstep@zzz.XXX.XXX.XXX:11300",
"error:errorsstep1",
"error:errorsstep2",
"error:errorsstep3"
],
// Мишени для стоп случаев (опционально)
"onstop":[
"stop:stopstep@kkk.XXX.XXX.XXX:11300",
"stop:stopstep1",
"stop:stopstep2",
"stop:stopstep3"
],
// Передаваемые данные
"payload":{
....
},
// Годен до ... (опционально)
"till":[
....
],
// Доступен для обработки с ... (опционально)
// Пакет будет доступен для обработки начиная с
// такой-то секунды (LINUX-TimeStamp)
"since":[
1540073089.8833,
],
// Кол-во сделанных шагов по процессу
"points":1,
// Идентификатор группы. Используется для различных целей
"groupid":""
}
nextStepWorker
Каждое сообщение, оказывающаяся в очереди, обрабатывается воркером, который за нее отвечает. Для этого реализован следующий набор функций:
class nextStepWorker extends workerConstructor
{
// Класс является базовым для создания воркеров
// Десериализует строку в объект esbTask
// Конфигурирует логику воркера (рутинную)
// Инициализирует работу с MQ-уровнем (beanstalkd)
// Инициализирует работу с кешем (Memcached)
// Инициализирует работу с БД (MySQL)
// Реализует:
- логику (в базе - пустую);
- обработку ошибок и stop-ситуаций;
- информирование на каждом этапе выполнения (log, event, mq)
....
}
На базе этого класса реализуются воркеры для каждого из этапов процесса. Всю рутину обработки, адресации и отправки в следующую очередь в маршруте, класс берет на себя.
Решение каждой из задач сводится к тому, чтобы:
- Получить esbTask и запустить воркер;
- Реализовать логику, сохранив результаты в payload;
- Завершить выполнение воркера (аварийно или нормально — не важно).
Если шаги выполнены, результат попадет в очередь с соответствующим названием и следующий воркер начнет обработку.
Делай раз. Проверить доступность
Фактически, создание воркера для решения любой из задач, есть реализация одного метода. Пример (упрощенный) реализации воркера, решающего Задачу 2 выглядит следующим образом:
// app/src/Process/worker/curlChecker.php
....
class curlChecker extends nextStepWorker
{
const PROXY_INFO = 'https://api.ipfy.me?format=json&geo=true';
const PROXY_TIMEOUT = '40';
const COMMAND = "curl -m %s -Lx http://%s:%s '%s'";
public function logic()
{
// Извлекаем разные нужные переменные. В т.ч. и из payload
extract($this->context());
// Устанавливаем defaults для отсутствующих в payload переменных
$curltimeout = $curltimeout ?? self::PROXY_TIMEOUT;
$curlchecker = $curlchecker ?? self::PROXY_INFO;
// Формируем и выполняем команду
$line = sprintf(
static::COMMAND, $curltimeout, $host, $port, $curlchecker
);
exec($line, $info);
// Преобразуем и проверяем работоспособность прокси
// (если пусто, то stop-исключение)
$info = arrays::valid_json(implode('', info));
if (empty($info))
throw new \Exception("Bad proxy: $host:$port!", static::STATUS_STOP);
// Добавляем результат в payload
$this->enrich(['info'])
->sets(compact('info'));
}
}
Несколько строк кода и все сделано и «откомандировано» в следующий этап.
Определить TimeZone. TimeZoneDB и для чего это нужно...
Глубокое тестирование входящих запросов включает в себя сопоставление времени окна браузера со временем, в котором существует IP-адрес-источник-запроса.
Чтобы избежать подозрений со стороны счетчиков, нам нужно знать локальное время прокси.
Для выяснения времени, возьмем широту и долготу из результатов предыдущего шага процесса и получим данные о часовом поясе, в котором будет работать наш будущий экземпляр окна браузера. Эти данные нам предоставят профессионалы в области времени.
Упрощенный воркер для решения этой задачи (Задача 3) будет полностью аналогичен предыдущему. Различие лишь в URL запроса. Полную версию вы сможете найти в файле:
// app/src/Process/worker/timeZone.php
Немного об инфраструктуре
Кроме описанного beanstalkd, нашему инструменту понадобятся:
- Memcached — для задач кэширования;
- Selenium Server — удобно запускать Selenium Web Driver в отдельном контейнере и можно наблюдать за процессом по VNC;
- Панели для наблюдения за beanstald, Memcached и VNC.
Для быстрого развертывания всего этого очень удобен Docker (Как установить на Ubuntu).
sudo apt-get -y update
sudo apt-get -y install docker-compose
Эти инструменты позволяют запускать уже скомпонованные и настроенные (кем-то ранее) сервера/процессы в отдельных «контейнерах» материнской ОС. За подробностями рекомендую обратиться к этой либо к этой статьям.
Итак…
Для запуска инфраструктуры вам нужно несколько команд в консоле:
# В консоле машины, предназначенной для запуска docker-контейнеров
# находясь в домашнем каталоге (для оркестратора это важно)
# действуя под чарами sudo -s
git clone https://oauth2:YRGzV8Ktx2ztoZg_oZZL@git.ituse.ru/deploy/esb-infrastructure.git panels
cd panels
docker-compose up --build -d
# потребуется чашечка кофе.
В результате успешного выполнения команды на машине с адресом XXX.XXX.XXX.XXX,
вы получите следующий набор сервисов:
— XXX.XXX.XXX.XXX:11300 — beanstalkd
— XXX.XXX.XXX.XXX:11211 — Memcached
— XXX.XXX.XXX.XXX:4444 — Selenium Server
— XXX.XXX.XXX.XXX:5930 — VNC-сервер для контроля того что происходит в Chrome
— XXX.XXX.XXX.XXX:8081 — Веб-панель для общения с Memcached (admin:pass)
— XXX.XXX.XXX.XXX:8082 — Веб-панель для общения с beanstalkd
— XXX.XXX.XXX.XXX:8083 — Веб-панель для общения с VNC (пароль:secret)
— XXX.XXX.XXX.XXX:8080 — Общая веб-панель
# В консоле машины, предназначенной для запуска docker-контейнеров,
# находясь в каталоге ..../panels/
# Посмотреть запущенные контейнеры
docker-compose ps
# Name Command State Ports
# ------------------------------------------------------------------------------------------------------------------------
# beanstalkd /usr/bin/beanstalkd Up 0.0.0.0:11300->11300/tcp
# chrome start-cron Up 0.0.0.0:4444->4444/tcp, 0.0.0.0:5930->5900/tcp
# memcached docker-entrypoint.sh memcached Up 0.0.0.0:11211->11211/tcp
# nginx docker-php-entrypoint /sta ... Up 0.0.0.0:8443->443/tcp, 0.0.0.0:8080->80/tcp,
# 0.0.0.0:8082->8082/tcp, 0.0.0.0:8083->8083/tcp, 9000/tcp
# vnc /usr/bin/supervisord -c /e ... Up 0.0.0.0:8081->8081/tcp
# Попасть в консоль машины с именем chrome
docker exec -ti chrome /bin/bash
# Остановить все контейнеры и почистить мусор
docker-compose stop && docker rm $(docker ps -a -q)
Задачи 4,5,6 — объединяем в одну утилиту
Подробно посмотрев дробление на задачи (схема выше), легко убедиться, что из оставшихся задач только одна (задача 6) зависит от внешнего ресурса. Выполняя задачи с «условно гарантированным» временем выполнения (не зависящие от не контролируемых факторов), мы не получим дополнительных плюсов к скорости всего процесса. В этой связи эти задачи (4,5,6) и были объединены в один воркер. Файл воркера называется:
// app/src/Process/worker/whoerChecker.php
Сделать настройки для Chrome. Плагины
Chrome гибко конфигурируется при помощи плагинов.
Плагин для Chrome это архив, который содержит файл manifest.json. Он и описывает плагин. Архив, также, содержит набор JavaScript, html, css и др.-файлов, необходимых плагину (подробности).
В нашем случае, один из JavaScript-файлов будет выполнен в контексте рабочего окна Chrome и все необходимые настройки вступят в силу.
Нам осталось только взять шаблон плагина и подставить в нужные места нужные данные (протокол взаимодействия, адрес и порт либо Timezone) для тестируемого прокси-сервера.
Фрагмент кода, который делает архив:
// app/src/Chrome/proxyHelper.php
....
class proxyHelper extends sshDocker{
....
// $name - имя архива-плагина
// $files - [ ... 'имя файла внутри архива-плагина' => 'содержимое', ...]
protected function buildPlugin(string $name, array $files)
{
$this->last = "$this->cache/$name";
if (!file_exists("$this->last")) {
$zip = new \ZipArchive();
$zip->open("$this->last", \ZipArchive::CREATE | \ZipArchive::OVERWRITE);
foreach ($files as $n => $data) {
$zip->addFromString(basename($n), $data);
}
$zip->close();
}
$this->all[] = $this->last;
$this->all = array_unique($this->all);
return $this;
}
....
}
Шаблон для плагина, настраивающего прокси был найден в копилке результатов труда людей любящих свою профессию, изменен в части протокола, и, добавлен в репозиторий.
Смена времени окна
Для смены глобального времени запущенного экземпляра Chrome нам нужно заменить window.Date на класс с аналогичным функционалом, но действующий в нужном часовом поясе.
Я очень признателен за труд Sampo Juustila. Скрипт был сделан для автоматизированного тестирования UI, но после небольшой доработки был применен.
Здесь есть нюанс, на который я хочу обратить ваше внимание. Связан он с контекстом выполнения скриптов, описанных в manifest.json.
Весь секрет в том, что глобальный контекст (тот в котором запускается главный скрипт плагина и прописываются установки, например, связанные с сетью) — изолирован от контекста вкладки в которую загружается страница.
Эмпирическим путем было установлено, что воздействие на прототип класса в глобальным контексте не привело к его изменению во вкладке. Однако, прописав скрипт в уже загруженную страницу и выполнив его прежде остальных, задачу удалось решить.
Решение представлено следующим фрагментом кода:
// app/chromePlugins/timeShift/content.js
// Создали элемент на странице
var s = document.createElement('script');
// Загрузили файл с основным скриптом из плагина
s.src = chrome.extension.getURL('timeshift.js');
// Вставили текст в созданный элемент
(document.head || document.documentElement).appendChild(s);
Настройка прокси
// app/chromePlugins/proxy/background.js
var config = {
mode: "fixed_servers",
rules: {
singleProxy: {
scheme: "%scheme",
host: "%proxy_host",
port: parseInt(%proxy_port)
},
bypassList: ["foobar.com"]
}
};
chrome.proxy.settings.set({value: config, scope: "regular"}, function () {
});
function callbackFn(details) {
return {
authCredentials: {
username: "%username",
password: "%password"
}
};
}
chrome.webRequest.onAuthRequired.addListener(
callbackFn,
{urls: [">all_urls<"]},
['blocking']
);
Путь плагинов к Chrome
// схема именования для proxy-плагина:
proxy-[адрес]-[порт]-[протокол]>.zip
timeshift-["-"|""]-[сдвиг_в_минутах_от_GMT].zip
Далее нам необходимо установить эти плагины в docker-контейнер, который запущен на машине, отвечающей за инфраструктуру.
Мы будем делать это при помощи ssh. Для этого я познакомился с phpseclib (хоть позднее и пожалел об этом). Увлеченный необычным поведением библиотеки, я истратил день на ее изучение.
Консольный клиент ssh здесь подойдет лучше и будет работать быстрее, но дело уже было сделано.
За низкий уровень (работа с SFTP и SSH) отвечает базовый класс (ниже). Замена этого класса позволит заменить phpseclib на консольный клиент.
// app/src/Chrome/sshDocker.php
// Класс привязан константами (DOCKER_HOST, DOCKER_USER, DOCKER_PASS)
// к глобальной конфигурации: app/settings.php
// Ниже два наиболее значимых метода
....
class sshDocker
{
....
// Глобальная константа. Содержит путь к исполняемому docker
// Путь может быть разным. Зависит и от дистрибутива и от способа установки
// Конфигурируется: app/techs.php
const EXEC_DOCKER = DOCKER_BIN_PATH . "/docker exec -i %s %s";
....
// Позволяет выполнить команду под sudo на хост машине (не в контейнере), если DOCKER_USER - судоер
protected function sudo(string $command, string $expect = '.*'){...}
// Позволяет выполнить команду в Docker-контейнере, для которого создан экземпляр объекта
// Команда выполняется за счет запуска на хост-машине команды по шаблону self::EXEC_DOCKER
protected function execDocker(string $command, string $expect){...}
....
}
Порожденный от базового sshDocker и уже нам известный класс proxyHelper не только производит плагины, но и кладет их во временную папку контейнера инфраструктуры.
// app/src/Chrome/proxyHelper.php
....
class proxyHelper extends sshDocker
{
....
public static function new(string $docker, $plugins)
{
return (new self($docker, $plugins))
->setupPlugins();
}
....
}
Запустить Chome с настройками
Запустить настроенный Chrome нам поможет Selenium Server.
Selenium Server — фрейм-ворк, созданный командой FaceBook специально для тестирования WEB-интерфейсов.
Фрейм-ворк позволяет разработчику программно эмулировать любое действие пользователя в окне браузера (используется Chrome либо Firefox).
Selenium Server адаптирован к использованию со многими языками и де-факто является стандартным инструментом для написания тестовых сценариев.
Наилучший способ получить свежий релиз для использования в проекте:
composer require facebook/webdriver
// URL-ЦЕЛь
$url = "https://example.com/books/196/empire-v-povest-o-nastoyashem-sverhcheloveke";
// URL, по которому доступна инфраструктура (Selenium Server)
$server = 'http://' . DOCKER_HOST . '/wd/hub';
// экземпляр объекта опция, которым мы запрещаем показывать нотификации
$options = new ChromeOptions();
$options->addArguments(array( '--disable-notifications' ));
// Установка опций в конф-структуру
$capabilities = DesiredCapabilities::chrome();
$capabilities->setCapability(ChromeOptions::CAPABILITY, $options);
// Получение экземпляра окна с отстрелом по таймауту 5000 мс и загрузка целевой URL
$driver = RemoteWebDriver::create($server, $capabilities, 5000);
$page = $driver->get($url);
И потому, я немного сократил все это, оптимизировав конфигурирование под свои нужды:
// app/src/Process/worker/whoerChecker.php
....
class whoerChecker extends nextStepWorker
{
// Настройки из глобальной конфигурации: app/settings.php
// URL Selenium Server
const SELENIUM_SERVER = CHVM;
// Имя докер-контейнера
const DOCKER_NAME = DOCKER_NAME;
....
public function config()
....
// Полный аналог со стандартным получением экземпляра окна браузера:
// $driver = RemoteWebDriver::create($server, $capabilities, 5000);
$chrome = Chrome::driver(
static::SELENIUM_SERVER, Chrome::capabilities(static::DOCKER_NAME, $plugins), 5000
);
....
}
....
Глаз сразу цепляется за $plugins. $plugins — это структура данных, отвечающая за конфигурирование плагинов. За директорию каждого и за замещение плейсхолдеров в JavaScript файлах плагина.
// app/plugs.php
const PLUGS = [
'timeshift' => [
'path' => PROJECTPATH . '/app/chromePlugins/timeShift',
'files' => ['manifest.json', 'timeshift.js', 'content.js'],
'fields' => ['%addsminutes' => 'timeshift']
],
'proxy' => [
'path' => PROJECTPATH . '/app/chromePlugins/proxy',
'files' => ['manifest.json', 'background.js'],
'fields' => [
'%proxy_host' => 'host', '%proxy_port' => 'port', '%scheme' => 'scheme',
'%username' => 'user', '%password' => 'pass'
]
]
];
Парсинг страницы с Selenium WebDriver — очень прост.
....
$url = 'https://адрес_страницы_источника/и_какой-нибудь_путь';
$page = $chrome->get($url);
....
// строка с xPath-адресацией нужного элемента
$xpath = '/html[1]/body[1]/div[1]/div[1]/div[1]/div[2]/div[1]/div[1]/div[1]/div[1]/strong[1]';
$element = page->findElement(WebDriverBy::xpath($xpath));
....
// Текстовое воплощение
$text = $element->getText();
// HTML-воплощение
$html = $element->>getAttribute('innerHTML');
....
Как я уже писал, все эти действия реализуются утилитой третьего шага (Задача 4,5,6):
// app/src/Process/worker/whoerChecker.phpЗавершая описание работы с Selenium Server, хочу обратить ваше внимание на то, что при использовании этой технологии в промышленных масштабах (1000 — 3000 открываний страниц), нередки ситуации, когда сессия с Selenium Server завершается некорректно. Окно оказывается бесхозным. И таких окон может накопиться очень много.
Способов борьбы с «брошками» рассматривалось несколько. Работа «съела» 2 дня. Самым эффективным оказался cron. Корректная его установка и настройка в Docker-контейнере превратилась в отдельную задачу, заботливо и очень подробно описанной renskiy, в статье, посвященной ТОЛЬКО ЭТОЙ ТЕМЕ (чему я был удивлен).
Автоматическая пересборка исходного Docker-имиджа и встройка нескольких скриптов по закрытию брошек и очистке от неиспользуемых плагинов описана в docker-compose.yml, репозитория инфраструктуры. Периодичность очистки задается в файле killcron, того же репозитория.
WebRTC
Несмотря на то, что мы уже установили правильное время, а трафик нашего браузера идет через прокси, мы все еще можем быть обнаружены.
Помимо разницы во времени (браузер и IP адрес), существуют еще два источника деанонимзации «сидящего за прокси». Это flash и WebRTC технологии, встроенные в браузер. В нашем браузере Flash отключен, WebRTC — нет.
Причина обеих возможностей провала одна — вездесущие и юркие UDP-пакеты. Для WebRTC это два порта: 3478 и 19302.
Для прекращения исхода «лазутчиков» из контейнера «chrome», на хост-машине с контейнерами инфраструктуры применяется правило iptables:
iptables -t raw -I PREROUTING -p udp -m multiport --dports 3478,19302 -j DROP
Реализует эту задачу все тот же proxyHelper.
Остальные воркеры
Для успешного достижения цели — осуществления «клика» по целевому сайту через анонимный прокси, нам понадобится еще один воркер.
Он будет усеченной версией whoerChecker. Думаю сделать это самостоятельно, используя все написанное, не составит труда.
Результат работы всего процесса, попадающий в очередь located, содержит данные о «степени» анонимности каждого прошедшего проверку адреса прокси сервера.
При «игре» против счетчиков главное помнить об анонимности и не увлечься роботизированными посещениями. Соблюдение принципа «не увлекайся кликами» обеспечено возможностью организации действий по расписанию, которая заложена в esbTask (поле since нашего ESB конверта).
Если постараться и сделать все аккуратно, то yandex-метрика целевого сайта будет похожа на рисунок ниже.

Как собрать все вместе
Итак, дано:
- утилиты, которые способны принять «на вход» (в качестве аргумента командной строки) esbTask json-строковом виде и выполнить некоторую логику, а результаты отправить в beanstalkd;
- очередь сообщений (MQ), на базе beanstalkd;
- Linux-машина (Process-машина);
При таком «Дано», обычно, я применяю libevent и React PHP. Все это, дополненное несколькими инструментами, позволяет управлять количеством (в заданных пределах) экземпляров обработчиков для каждого этапа процесса автоматически.
Однако, учитывая размер статьи и специфику темы, я буду рад описать все это в отдельном материале. Эта статья — технология "noserver". Будущий материал — "server".
Дата его публикации связана с Вашим интересом, Уважаемый Читатель.Для меня этот интерес очень важен. Его можно выразить количественно и устроить, например,… голосование. И, конечно же, есть такие численные показатели, по достижении которых, я задействую все имеющиеся ресурсы, чтобы новая статья предстала перед вами как можно быстрее.
Однако правила habr регламентируют применение механизмов, подобных голосованию за продолжение статей. И, возможно, благодаря именно этому нам так интересно читать публикуемый здесь материал.
Эта статья не станет исключением из этих правил. При этом любой из вас, кто захочет ускорить выход статьи о технологии "server", найдет способ выразить свое желание изучив README.md любого из репозиториев либо кликнув по ссылке в описании репозиториев.
В "noserver", один экземпляр будет обрабатывать одну очередь (один этап процесса). Такой подход
В зависимости от необходимой скорости обработки вы можете запустить сколь угодно много экземпляров «вручную».
Выглядеть это может так:
// app/src/Process/noserver/singleProcess.php
// Однопоточный обработчик заданий, приходящих в очередь
// Подключение конфигураций
include __DIR__ . '/../../../settings.php';
use App\ESB\pipeNcacheService;
use App\arrayNstring\queueDSN;
use App\arrayNstring\timeSpent;
use App\arrayNstring\progressString;
// Путь к воркерам
$path = __DIR__ . '/../worker';
// Настройка умолчаний
$queues = array_keys(WORKERS);
$queue = $argv[1] ?? end($queues);
$queue = strtolower($queue);
if (!in_array($queue, $queues))
die("php $argv[0] <queue_name>" . PHP_EOL);
// Текстовой прогресс-бар
$progress = new progressString("Listenning... Idle: ", 40, 20);
// Секундомер, удобный для вывода на экран
$stopwatch = timeSpent::start();
// Конфигурирование и подключение beanstalkd-клиента
list($worker, $task) = WORKERS[$queue];
$procid = ['procid' => posix_getpid()];
// Работа с beanstalkd и Memcached,
// комбинированная в один класс (для удобства)
$dsn = new queueDSN($task, $queue, ...QUEUE_SERVER);
// Работа с адресами внутри ESB-шины
$pnc = new pipeNcacheService($dsn);
$pipe = $pnc->getPipe();
echo "Start listener for queue: $queue." . PHP_EOL;
echo "Press Ctrl-C to stop listener." . PHP_EOL;
// Прослушивание трубы в бесконечном цикле
// и запуск обработчика при получении задачи
while (true) {
try {
$job = $pipe->watch($queue)
->reserve(1);
$now = new DateTime();
$opts = json_encode($pipe->getPayload($job) + $procid);
$pipe->delete($job);
echo PHP_EOL . "Task recived at: " . $now->format('H:i:s') .
" Starting worker: $worker. ";
$stopwatch = timeSpent::start();
exec("php $path/$worker $opts", $out);
echo "Finished. Time spent: $stopwatch" . PHP_EOL;
$stopwatch = timeSpent::start();
} catch (Throwable $exception) {
echo $progress($stopwatch('%I:%S', null, $now));
}
}
Бросается в глаза странный запуск воркера… Несмотря на то, что каждый из воркеров является PHP-объектом, я использовал exec(...).
Это сделано в целях экономии времени, чтобы не создавать отдельные воркеры для "noserver" либо не изменять воркер под цели запуска в режиме "server".
Пару слов о конфигурации и развертывании
Константы конфигурирования
За конфигурацию вашего экземпляра отвечает файл app/settings.php. Он должен быть создан Вами сразу после клонирования репозитория. Для этого нужно переименовать файл app/settings.php.dist. Все константы описаны внутри.
app/settings.php, кроме прочего, подключает файлы с другими константами.
— app/queues.php содержит названия очередей и заданий
— app/plugs.php содержит описание Chrome-плагинов
— app/techs.php содержит вычисляемые константы
Утилиты
Для удобства обработки результатов работы процесса и размещения заданий есть несколько утилит. Утилиты запускаются из командной строки. Снабжены описаниями аргументов. Расположены: app/src/Utils.
backup.php - сохраняет очереди в файл
clear.php - чистит очереди
exporter.php - экспортирует из файла с сохраненной очередью
пары адрес:порт
givethejob.php - размещает задания процессу
(источник - файл со списком адрес:порт).
может исключить часть адресов из списка
restore.php - восстанавливает сохраненную очередьТонкая настройка воркеров
При использовании написанных воркеров, может быть удобным использовать следующие возможности конфигураций:
// app/src/Process/worker/curlChecker.php
....
$worker = new curlChecker(
[
// Формальное имя воркера
curlChecker::WORKER => 'curlchecker',
// Сервер beanstalkd
curlChecker::PIPE_HOSTPORT => implode(':', QUEUE_SERVER),
// Сервер Memcached
curlChecker::CACHE_HOSTPORT => implode(':', MEMCACHED),
// Функция, инициализирующая доступ к БД.
// В данном случае - не применяется
curlChecker::DB_SCRIPT => __DIR__ . '/../../../confdb.php',
// Очередь, куда попадает сообщение при старте воркера
// (может быть удобна при трассировке либо при создании веб-панели)
curlChecker::INFO_START => CURL_START,
// Очередь, куда попадает сообщение при успешном завершении воркера
// (может быть удобна при трассировке либо при создании веб-панели)
curlChecker::INFO_END => CURL_END,
// Дополнительные поля, которые добавляются в сообщения
// для трассировочных очередей
// Есть аналогичная константа и для стартовой очереди
curlChecker::INFO_ADDS_END => ['host', 'port']
],
['setupworker', 'config', 'logic']
);
....
Развертывание
Инструкция предполагает, что у вас в распоряжении 2 машины с установленной Ubuntu 18.04.
Одна для инфраструктуры (docker), другая для управления процессом (process).
docker
# Все действия предполагают root-привелегии.
# Предполагается, что не заняты следующие TCP-порты:
# 11300, 11211, 4444, 5930, 8080, 8081, 8082, 8083
# Установка необходимых пакетов.
sudo -s
apt -y update
apt -y install git snap
snap install docker
apt -y install docker-compose
# Cклонировать репозиторий с инфраструктурой в домашний каталог
# "не root-пользователя" и запустить контейнеры
cd ~
git clone https://oauth2:YRGzV8Ktx2ztoZg_oZZL@git.ituse.ru/deploy/esb-infrastructure.git
cd esb-infrastructure
docker-compose up --build -d
# Вам потребуется чашка кофе и 3 минуты терпения после окончания
# процесса старта контейнеров.
# Примерно столько времени необходимо на развертывания web-панелей.
process
# Все действия предполагают привелегии обыкновенного пользователя.
# Установка необходимых пакетов.
sudo apt -y update
sudo apt -y install git php-common php-cli php-curl php-zip php-memcached composer
# Cклонировать репозиторий с проектом на process-машину в любой каталог,
# доступный для записи и до-установить необходимые php-пакеты
cd /var/www
git clone https://oauth2:YRGzV8Ktx2ztoZg_oZZL@git.ituse.ru/deploy/clicker-noserver.git
cd clicker-noserver
composer update
# Сконфигурировать приложение. Для это в файле заменить строки "XXXXXXXX"
mv app/settings.php.dist app/settings.php
# Запустить обработчики очередей.
gnome-terminal --tab -e 'bash -c "php app/src/Process/noserver/singleProcess.php curl"' --tab -e 'bash -c "php app/src/Process/noserver/singleProcess.php timezone"' --tab -e 'bash -c "php app/src/Process/noserver/singleProcess.php whoer"'
# Дать задание. Предполагается, что файл со списком прокси,
# формата адрес:порт - log/list.proxy
php app/src/Utils/givethejob.php ./log/list.proxy
Ждать, наблюдая за происходящим через web-панель (http://ip-адрес-докер-машины:8080).
Результат будет доступен в очереди located.
И в заключении
Удивительно, но написание и редактирование этой статьи потребовало больше времени, чем написание самого кода.
На мой взгляд все могло быть наоборот (и отличие во времени могло быть в несколько раз большим), если бы не две идеологии: Message Queue и Enterprise Service Bus.
Я буду очень рад, если вам будет полезен представленный подход к написанию приложений, нагрузка на разные части которых не ясна на этапе проектирования.
Спасибо.
Комментарии (41)

1nd1go
04.12.2018 16:08Возможно сделать headless-режим? ЧТобы запускать где-нибудь на vps?

mopkob Автор
04.12.2018 16:40Да.
1nd1go
04.12.2018 18:17вопрос предполагал совет конкретных шагов
mopkob Автор
04.12.2018 18:45Для реализации запуска где-нибудь на VPS Вам потребуется:
- Арендовать два VPS;
- Связать их по VPN;
- На одном выполнить инструкции «process»;
- На другом выполнить инструкции «docker»;
- Ограничить доступы к TCP портам, перечисленным в инструкции для всех кроме VPN-адресов.
Дать задание в консоле «process» машины.1nd1go
04.12.2018 20:17Мы, наверное друг друга не поняли. Вы когда селениум поднимаете — он у вас окно открывает? Если да, как можно в headless mode запускать, потому что запускать окошко селениум вроде не давал когда монитора нет?
mopkob Автор
04.12.2018 23:14Мы, наверное друг друга не поняли.
Наверное...) Давайте разбираться вместе.
В подробном описании установки clicker и docker-инфраструктуры из репозитория либо в инструкции в тексте статьи (она чуть короче), все действия производятся в командной строке машин, на борту которых установлена Ubuntu 18.04 в компановке SERVER.
Нигде в процессе установки не используются какие-либо графические рабочие столы.
Selenim Server поднимается внутри одного из Docker-контенеров. В этом контейнере присутствует VNC-сервер.
Если Вас интересует конфигурация docker-контейнера без возможности посмотреть на работу Chrome, то рядом лежит ровно такой же, но без VNC. Он менее «прожорлив».
При выполнении инструкций, все происходит автоматически. После старта вам доступны веб-панели. В одну из них встроен VNC-клиент (это больше в отладочных целях и для наглядности).
Самый простой способ поверить — попробовать.
Для этого Вам потребуется: пара евро, мобильный телефон, 3 часа времени.
Получите свои сервера в аренду, затратив на это 2 часа и деньги (например, здесь).
Еще час Вы потратите на перечитывание и выполнение инструкции. Выдача заданий по проверке прокси не займет и 10 минут.
Если я правильно понял Ваши вопросы, то ответы должны подойти и дать недостающие части в «картинку».
В любом случае, я признателен Вам за интерес и внимание к деталям. Если в моих ответах что-то осталось за «кадром» — спрашивайте.
balexa
04.12.2018 16:12Это ничем не отличается от спама, смс рассылки и обзвона. Спам загаживает почтовый ящик, а это загаживает интернет. Это подло и противозаконно.
Я серьезно. Максим Валерьевич, выкладывать подобную информацию от своего имени на своем сайте — весьма глупо и опрометчиво.konoplinovich
04.12.2018 16:22Ну, можно подвергнуть Максима Валерьевича какой-нибудь оптимизации посредством размещения адреса его сайта и контактных данных на сомнительных ресурсах удручающего содержания.
altrus
04.12.2018 16:23А это не подлость?
konoplinovich
04.12.2018 16:26С одной стороны — да, а с другой — праведный народный гнев. Тонкая грань.
mopkob Автор
04.12.2018 17:37Ваша оценка статьи, Ваша оценка поступков Максима Валерьевича либо Ваша оценка чьих-либо поступков — это всегда определенный знак качества.
Позвольте я буду считать, что это знак высокого качества. Прежде всего Вашего.
В этом случае и мне и Максиму Валерьевичу, да и любому другому человеку будут приятны и познавательны Ваши оценки.
altrus
04.12.2018 16:20Вопрос по реализации — зачем нужны все эти Докеры, Селениумы и иже с ними? Почему нельзя все реализовать как расширение хрома?
Или скрипты поисковиков отделяют программный клик скрипта от селениумного программного?mopkob Автор
04.12.2018 17:29Docker — добавляет переносимости и универсальности. Он, так же, позволяет наращивать мощность обработки, легко размножая сконфигурированные контейнеры.
Selenium Server — позволяет управлять Google Chrome. Selenium-Chrome-программный клик ничем не отличается от Chrome-человеческого.
Google Chrome позволяет корректно выполнять все JS сайта (включая и счетчики), сохранять сессионные куки (при надобности).
Но статья не совсем о парсинге с исполнение JS в браузере. Это всего лишь сюжет.
Такой сюжет понятен определенной аудитории. Достаточно широкой.
Если говорить о вопросе масштабируемости системы без подобного сюжета, круг читателей будет более узким.
Статья, в большей степени о том как построить масштабирумую систему.
Подход к построению систем на основе MOM-идеологии — показался мне интересным. Применение его на практике сильно ускорило процесс построения чего-то завершенного.
Как дополнительный плюс — можно легко увеличь мощности обработки просто добавляя инстансы.
Эта же архитектура позволяет легко сопрягать системы разных производителей между собой, минимизируя затраты на разработку (ESB идеология).
Что касается расширения chrome… Можно, но для большинства задач проще это сделать на «родном языке». В противном случае Selenium не получил бы такого распространения (он адаптирован ко множеству языков), а все функциональные тесты интерфейса писались бы тем способом, что Вы предположили.
Относительно кода счетчика…
Что делает код счетчика Вашей страницы можно изучать. Но известно одно. Он должен отработать корректно. Поэтому использовать обычный CURL — может быть неэффективным решением.
altrus
04.12.2018 17:47Всю вашу МОМ архитектуру можно засунуть в воркеры расширения. Проста непонятно для чего городить докеры, селениумы, вводить php — только для клика?
Selenium-Chrome-программный клик ничем не отличается от Chrome-человеческого.
Вы так в этом уверены? Как-то я играл с автоматизаторами мыши и клавиатуры для кликов в браузере, там было близко к человеческому, а тут Селениум драйвер так-то не скрывает даже ни от кого, что он автомат.mopkob Автор
04.12.2018 18:19В этой статье показан пример подхода, позволяющего построить масштабируемую систему.
Некий этюд на архитектурные темы…
Как пример процесса который реализует система, выбрана след. последовательность действий (все это более подробно описано на схеме, приведенной в статье):
- проверка работоспособности прокси;
- определение часового пояса прокси;
- конфигурирование браузера;
- проверка анонимности настроек, путем получения тестовой страницы сконфигурированным браузером, находящимся по управлением системы
Это ответ на Ваш первый вопрос.
Что касается моей уверенности…
Я не знаю инструментов, доступных Java Script (запущенному во вкладке браузера), которые позволили бы оценить параметры двигающего мышкой.
Исключение составляют замеры времени и оценка промежуточных положений курсора. Однако, для осуществления полной эмуляции поведения пользователя у Selenium достаточно инструментов.
В этом причина моей уверенности.
Я буду признателен любому, кто меня разубедит.altrus
04.12.2018 18:22Проверьте Selenium на reCapcha2 (3) для начала
mopkob Автор
04.12.2018 23:24Я поторопился и ответил насчет антикапчи в другой ветке.
Когда меня интересовало решение задачи по преодолению такой защиты, я использовал этот ресурс.
Довольно сносно.
igorgusarov
04.12.2018 20:16Описанный метод не дает никаких преимуществ с точки зрения SEO и имеет множество недостатков:
1. Все эти «клики» видны невооружённым взглядом в любой системе аналитики
2. Ломает статистику, особенно по действиям пользователей на сайте
3. Любая адекватная антифрод-система блокирует такие запросы
Я много работаю с рекламными системами и почти каждый день вижу подобные попытки прикинуться человеком. Постоянно блокируем по subid.mopkob Автор
04.12.2018 21:59Огромное подспорье, что Вы заглянули сюда «с другой стороны баррикад».
Уверен, что altrus и все те кому интересна «сюжетная составляющая» моей статьи с удовольствием увидят подробности Вашего комментария. Все мы будем признательны Вам за подробное обоснование Вашей позиции.
Что касается моего опыта, то два года назад… Один мой интернет знакомый — dennis777, шутки ради, попросил меня сделать автомат по регистрации аккаунтов на одном очень известном иностранном публичном блоге.
Его позиция заключалась примерно в том, что современные системы защиты сильно превосходят возможности передовых SEO-специалистов. И с ZenoPoster (один из очень распространенных инструментов для таких задач) — не получается. Моя же в том, что я не настоящий SEO, что хочу попытать счастье и понять как это все устроено.
Обыкновенный PHP-curl и через неделю защита пала (причудливая комбинация из эмуляции аякс-запросов и куки сделала свое дело). Еще неделя и все окружение (включая ресурс Антикапчи, подбора фейковых имен и создание временной почты заработало как «револьвер системы НАГАН»).
Еще несколько дней и все это заработало с управляемыми прокси на выходе. Можно было TOR использовать можно купленные прокси. Что угодно…
Какие-то регистрации не преуспели, но… процент потерь составил меньше четверти. Я зарегистрировал 2017 полноправных аккаунтов. И многое понял.
Поскольку у этой дискуссии не было практического предмета, мы все и оставили подтвердив гипотезу возможности.
altrus
04.12.2018 22:10Ну у меня задача прозаичней была когда-то.
Я брал открытые данные с одного сайта, и мне надо было брать их часто, а владельцу сайта не нравилось, когда часто, и он блокировал по IP, и тогда я задумался о бесплатных проксях с их проверкой и использованием. Поэтому статья привлекла внимание. Так что отдельные вещи из нее можно применять безо всякого криминала или «подлостей»
Точно также полагаю, что нужно менять много параметров, чтобы хорошо спрятаться.mopkob Автор
04.12.2018 23:29Очень хочется подтвердить Ваше предположение. Думаю, многие ждут, что igorgusarov разовьет созданную интригу.
GokenTanmay
05.12.2018 07:57«Я беру, то что владелец не хочет давать» — без криминала.
«Я обманываю владельца и все равно беру, то что он не хочет давать выдавая себя за другого» — и без подлостей…
А Вы молодец, хорошая картинка мира.
По существу решаемой Вами задачи: что мешало, 1 раз спарсить сайт себе в базу и потом спокойно с ней работать? Тем более, что данные открытые, почему сами их не собирали, а обращались за ними к какому-то сайту, на котором они могли бы быть заведомо искаженны? Один из методов защиты, от подобного: не блокировать IP, а запоминать IP и некоторое время слать на него псевдо-валидные данные.altrus
05.12.2018 07:59А в кавычках у вас — это прямая речь? Чья?
GokenTanmay
05.12.2018 08:10Очевидно моя, Вы же такого не говорили. Намекаете что после кавычек я должен был писать: — сказал я.?
По существу решаемой задачи прокомментируете? Все таки задача достаточно тривиальна и многие так делают, интересен опыт.altrus
05.12.2018 08:12А по правилам русского языка — моя. Так подумали остальные. Потому что вы захотели, чтобы они так подумали. Вот это называется подлость.
GokenTanmay
05.12.2018 08:17Покажите правило русского языка на основании которого, мой текст в кавычках можно однозначно идентифицировать как вашу прямую речь, пожалуйста.
И не совсем понятно, что вас так задело? ну собирали данные, ну обходили «препоны» владельца сайта — это не криминал, я Вас ни в чем не обвиняю. Может даже немного завидую Вашему восприятию данной ситуации.
«Так подумали остальные» — сказал altrus. Вы телепат?
tumikosha
05.12.2018 17:56Selenium где-то там ставит переменную доступную из javascript'a.
Ну т.е. сайт без проблем понимает, что его из селениума смотрят и блокировать должен.
А PhantomJS специфически формирует headers, что тоже его палит.
+ еще есть fingerprint железа на котором запущен браузер
+ еще при скачивании chrome google прописывает в него уникальный ID
Я надеюсь вы его не со своего домашнего IP скачивали прежде чем докер собрать? :)
Так что человек желающий получить реальную анонимность вынужден писать свой аналог Selenium
Увы, но плагинам нет альтерантивы…mopkob Автор
05.12.2018 18:14Ну вот интрига и разрешена. Спасибо! )
Я надеюсь вы его не со своего домашнего IP скачивали прежде чем докер собрать? :)
Конечно со своего. Однако задача демонстрируемой системы — просеять прокси.
Для чего все это использовать и использовать ли — личный выбор каждого.
tumikosha
05.12.2018 18:33> личный выбор каждого.
К сожалению, не совсем так. Подозреваю, что PhantomJS забросили из-за трудностей с законом (но это не точно)

tuxi
05.12.2018 18:23Спасибо за грамотную статью. Было реально интересно.
Есть вопрос не по главной части статьи:
Есть различные библиотеки для построения fingerprint посетителя. Selenium сможет выдавать разные типы/названия оборудования (и тп) у фейкового посетителя? Насколько я понимаю, при построении отпечатка посетителя, используется различная информация, в том числе и эта.
konoplinovich
И все это для того, чтобы обмануть и поисковые системы, и, что самое главное, людей, которые будут этими системами пользоваться? Это же подлость, разве нет?
c_kotik
А потом будут статьи с заголовками из оперы «Как мы убиваем интернет»
GokenTanmay
К сожалению, такой статьи в УК нет. А эволюционно механизм «обмануть себе подобного» не вытравился.
altrus
Учитывая, что все остальные участники рынка применяют те же методы, да еще и проплачивают поисковикам за высокие места, это не подлость, а здоровая конкуренция
программеровkonoplinovich
Учитывая, что все остальные участники рынка применяют те же методы, да еще и проплачивают поисковикам за высокие места, то они совершают точно такую же подлость, как и автор этой статейки.
mopkob Автор
Вы затронули две очень интересные темы. Каждый из прочитавших статью ответит для себя на эти вопросы. Составит свое мнение. И я очень буду признателен за выражение любого мнения в комментариях.
Однако умение разбирать и собирать автомат Колашникова не всегда свидетельствует о подлости умеющего либо о его намерении грабить банк.
Для этой (да и для любой, наверное) статьи справедливо тоже самое правило, что и для басни. Ведь не бывает басни без сюжета как не может быть ее и без морали.
Вероятно, если читатель видит только мораль либо только сюжет, басня плоха.
У этой ситуации могут быть и другие причины, конечно.
Я предлагаю подождать.
И еще раз спасибо за Ваш взгляд.