

От переводчика: сегодня публикуем для вас совместную статью трех разработчиков, Akaash Chikarmane, Erte Bablu и Nikhil Gaur, в которой рассказывается о методе прогнозирования рейтинга приложений в Google Play Store.
В этой статье мы покажем способы обработки информации, которые применяем для прогнозирования рейтинга. Также мы объясним, почему используем те или иные из них. Мы поговорим и о преобразованиях пакета данных, с которым работаем, и о том, чего можно добиться при помощи визуализации.
Skillbox рекомендует: Двухлетний практический курс «Я – веб-разработчик PRO».
Напоминаем: для всех читателей «Хабра» — скидка 10 000 рублей при записи на любой курс Skillbox по промокоду «Хабр».
Почему мы решили это сделать
Мобильные приложения давно стали неотъемлемой частью жизни, все больше разработчиков занимаются их созданием в одиночку. Причем многие напрямую зависят от доходов, которые приносят приложения. Поэтому огромное значение для них имеет прогнозирование успеха.
Наша цель — определить общий рейтинг приложения, сделать это комплексно, поскольку слишком много людей судит о программе, опираясь лишь на количество «звездочек», поставленных пользователями. Приложения, имеющие 4-5 баллов, вызывают больше доверия.
Подготовка
Большая часть этого проекта — работа с данными, включая предварительную обработку. Поскольку вся информация взята из Google Play Store, в полученных массивах содержалось немало ошибок. Мы использовали несколько моделей регрессии, включая Gradient-Boosting Regressor из пакета XGBoost, Linear Regression и RidgeRegression.
Сбор и анализ данных
Набор данных, с которым мы работали, можно получить здесь. Он состоит из двух частей. Первая — это объективная информация, вроде размера приложения, количества установок, категории, количества обзоров, типа приложения, его жанра, даты последнего обновления и т.п., и субъективная, то есть пользовательские обзоры.
Анализу подвергались и сами обзоры. После сравнения результатов мы решали, включать или нет данные обзора в финальную модель.
Объективный набор данных мы формировали по 12 функциям и одной целевой переменной (рейтинг). Пакет включал 10,8 тысяч единиц информации. Что касается пользовательских обзоров, то мы выбрали 100 наиболее релевантных и использовали пять функций для 64,3 тысяч элементов. Все данные собирались напрямую из Google Play Store, последний раз они обновлялись три месяца назад.
Предварительная обработка данных
Начальный набор информации выглядел примерно так:
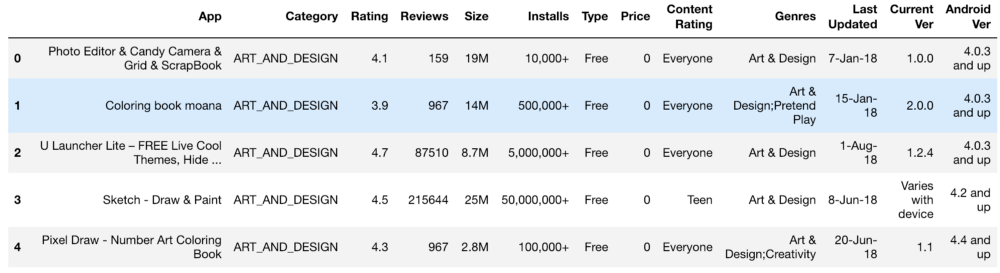
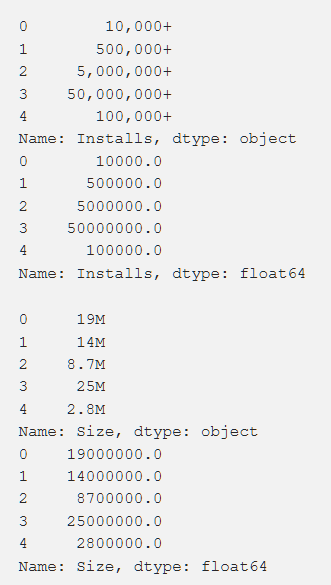
Установки, рейтинг, стоимость и размер — мы обрабатывали все это таким образом, чтобы получить числа, доступные пониманию машины. При обработке разных функций возникали проблемы вроде необходимости удаления «+». В стоимости мы убрали $. Объем приложения оказался самым проблемным в плане обработки, поскольку попадались как КБ, так и МБ, так что необходимо было проделать определенную работу по сведению всего к единому формату. Ниже показаны первичные данные и они же после обработки.
Кроме того, мы преобразовали некоторые данные, сделав их более релевантными нашей работе. Например, информация о последнем обновлении приложения была не слишком полезна. Для того чтобы сделать их более значимыми, мы преобразовали это в информацию о времени, прошедшем с последнего обновления. Код для выполнения такой задачи показан ниже.
from datetime import datetime
from dateutil.relativedelta import relativedelta
n = 3 # month bin size
last_updated_list = (new_google_play_store["Last Updated"]).values
last_n_months = list()
for (index, last_updated) in enumerate(last_updated_list):
window2 = datetime.today()
window1 = window2 - relativedelta(months=+n)
date_bin = 1
#print("{0}: {1}".format(index, last_updated))
last_update_date = datetime.strptime(last_updated, "%d-%b-%y")
while(not(window1 < last_update_date < window2)):
date_bin = date_bin + 1
window2 = window2 - relativedelta(months=+n)
window1 = window1 - relativedelta(months=+n)
last_n_months.append(date_bin)
new_google_play_store["Updated ({0} month increments)".format(n)] = last_n_months
new_google_play_store = new_google_play_store.drop(labels = ["Last Updated"], axis = 1)
new_google_play_store.head()Также необходимо было привести к единому стандарту переменные с несколькими разнящимися значениями (например, «Жанр»). Как это было сделано, показано ниже.
from copy import deepcopy
from sklearn.preprocessing import LabelEncoder
def one_hot_encode_by_label(df, labels):
df_new = deepcopy(df)
for label in labels:
dummies = df_new[label].str.get_dummies(sep = ";")
df_new = df_new.drop(labels = label, axis = 1)
df_new = df_new.join(dummies)
return df_new
def label_encode_by_label(df, labels):
df_new = deepcopy(df)
le = LabelEncoder()
for label in labels:
print(label + " is label encoded")
le.fit(df_new[label])
dummies = le.transform(df_new[label])
df_new.drop(label, axis = 1)
df_new[label] = pd.Series(dummies)
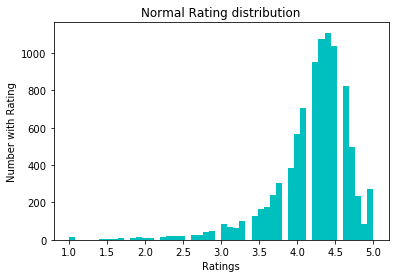
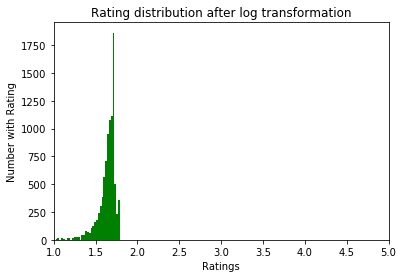
return df_newДля нормализации данных мы попробовали преобразование log1p. Перед ним:
После:
Изучение данных
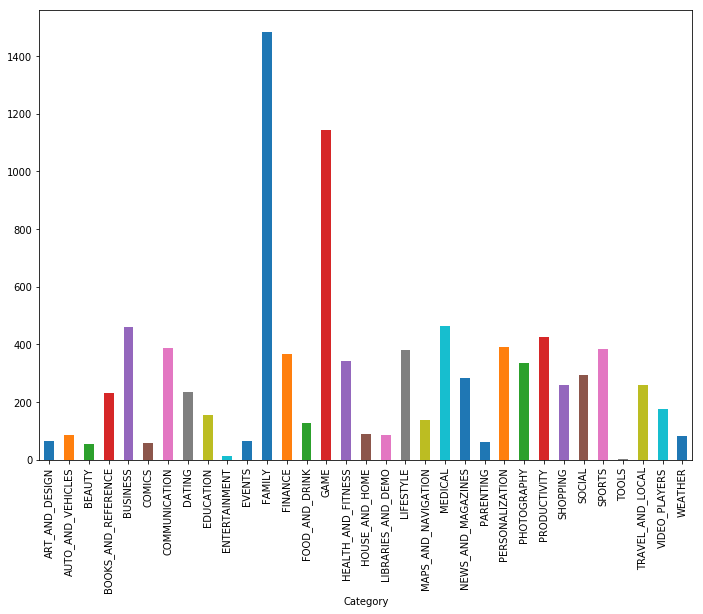
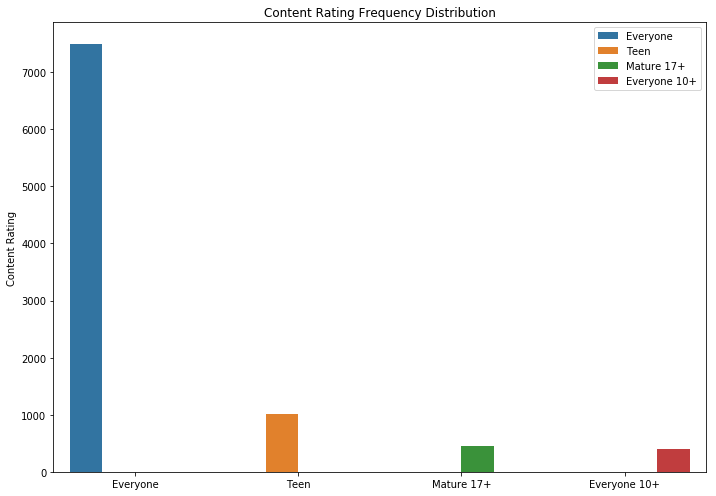
Как видим, игры и приложения для семьи — две самых популярных категории. Большинство приложений вдобавок входили в категорию «Для всех возрастов».

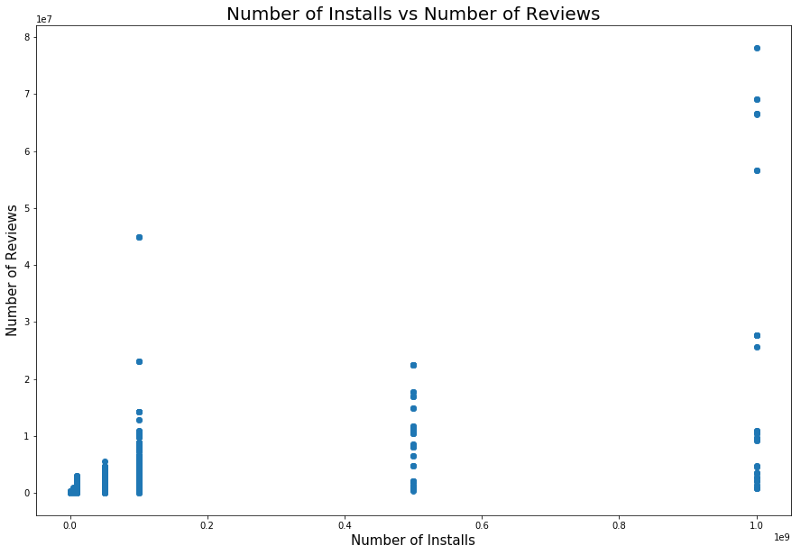
Логично, что приложения с максимальным рейтингом имеют больше обзоров, чем низкорейтинговые. У некоторых из них гораздо больше обзоров, чем у всех прочих. Возможно, причина этому — pop-up сообщение, призыв поставить оценку или другие приемы схожего характера.

Существует также зависимость между числом установок и количеством обзоров. Корреляция показана на скриншоте ниже.
Детальный анализ этой зависимости может дать понимание, почему у популярных категорий приложений больше установок и больше обзоров.
Модели и результаты
Мы использовали разделение тестов для разбивки данных на наборы для тестирования и обучения. Перекрестная проверка с помощью GridSearchCV применялась для улучшения результатов обучения модели, чтобы найти лучшую alpha с помощью Лассо, регрессии Риджа и XGBRegressor из пакета XGBoost. Последняя модель в общем случае чрезвычайно эффективна, но, используя ее, нужно остерегаться подгонки результатов — это одна из опасностей, подстерегающих исследователей. Начальное среднеквадратичное значение без какой-либо особо тщательной обработки объектов (лишь кодирование и очистка) составляло около 0,228.
После логарифмического преобразования рейтингов среднеквадратичная ошибка снизилась до 0,219, что стало хоть и небольшим, но улучшением — мы поняли, что все сделали правильно.
Мы использовали линейную регрессию после оценки связи между обзорами, установками и оценками. В частности, проанализировали статистическую информацию этих переменных, включая r-квадрат и p, приняв в итоге решение о линейной регрессии. Первая используемая модель линейной регрессии показала корреляцию между установками и рейтингом в 0,2233, модель линейной регрессии «Наши обзоры» и «Рейтинги» дала нам MSE 0,2107, а комбинированная модель линейной регрессии, «Обзоры», «Установки» и «Оценки», дала нам MSE 0,214.
Кроме того, мы использовали модель KNeighborsRegressor. Результаты ее применения показаны ниже.

Выводы
После того как первичные данные из Google Play Store были преобразованы в пригодный для использования формат, мы построили графики и вывели функции, чтобы понять корреляции между отдельными значениями. Затем использовали эти результаты для того, чтобы построить оптимальную модель.
Изначально мы считали, что найти ее будет не слишком сложно, так что у нас получится построить точную модель. Но задача оказалась сложнее, чем мы рассчитывали.
Кроме того, что было сделано, можно еще:
- создать отдельную модель для каждого жанра;
- создать новые функции из версий ОС Android, как мы это ранее сделали с датами;
- глубже обучить алгоритм — у нас было достаточное количество категорических и числовых точек данных;
- самостоятельно разобрать и очистить данные из Google App Store.
Все результаты работы доступны здесь.
Skillbox рекомендует:
- Онлайн-курс «Профессия frontend-разработчик»
- Практический курс «Мобильный разработчик PRO».
- Практический годовой курс «PHP-разработчик с 0 до PRO».