
Продолжаем открывать для публичного доступа новый функционал нашего сервиса анализа планов выполнения запросов в PostgreSQL explain.tensor.ru. Сегодня мы научимся определять больные места навскидку в больших и сложных планах, лишь мельком взглянув на них вооруженным глазом…

В этом нам помогут различные варианты визуализации:
Оригинальный текст достаточно несложного плана уже вызывает проблемы при анализе:
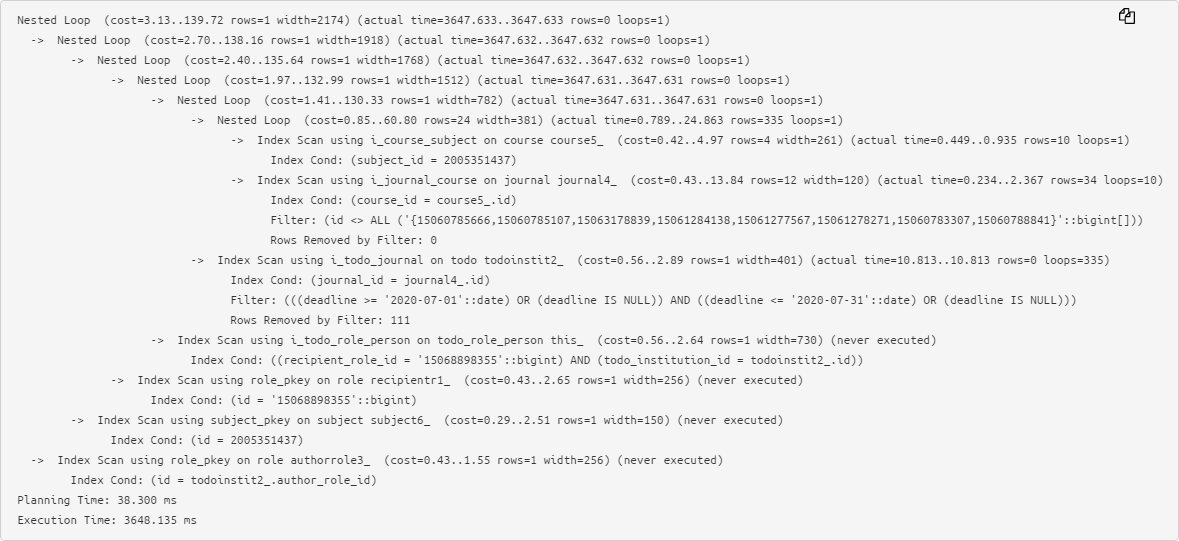
Поэтому мы предпочитаем сокращенный вид, когда влево-вправо вынесена ключевая информация о времени выполнения и использованных buffers каждого узла, и очень просто заметить максимумы:
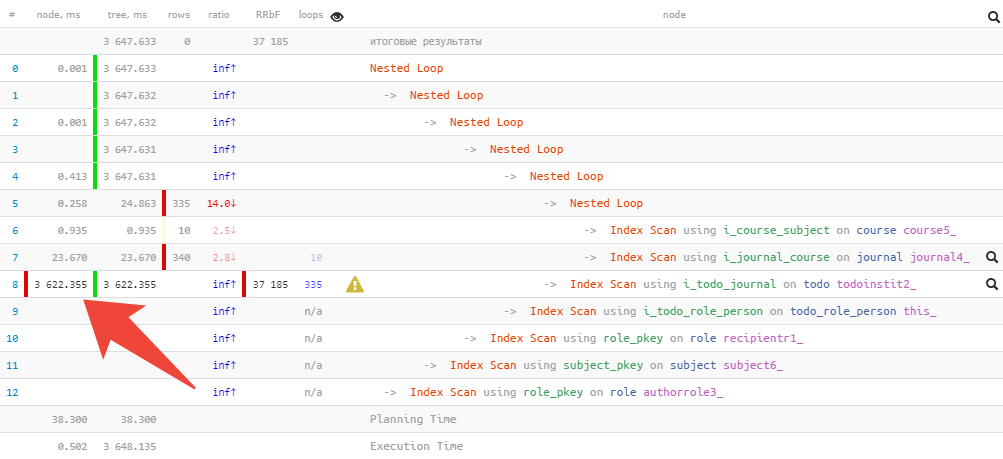
Но иногда даже просто понять «где болит сильнее всего» непросто, особенно, если он содержит несколько десятков узлов и даже сокращенная форма плана занимает 2-3 экрана.

В этом случае на помощь придет обычная круговая диаграмма:
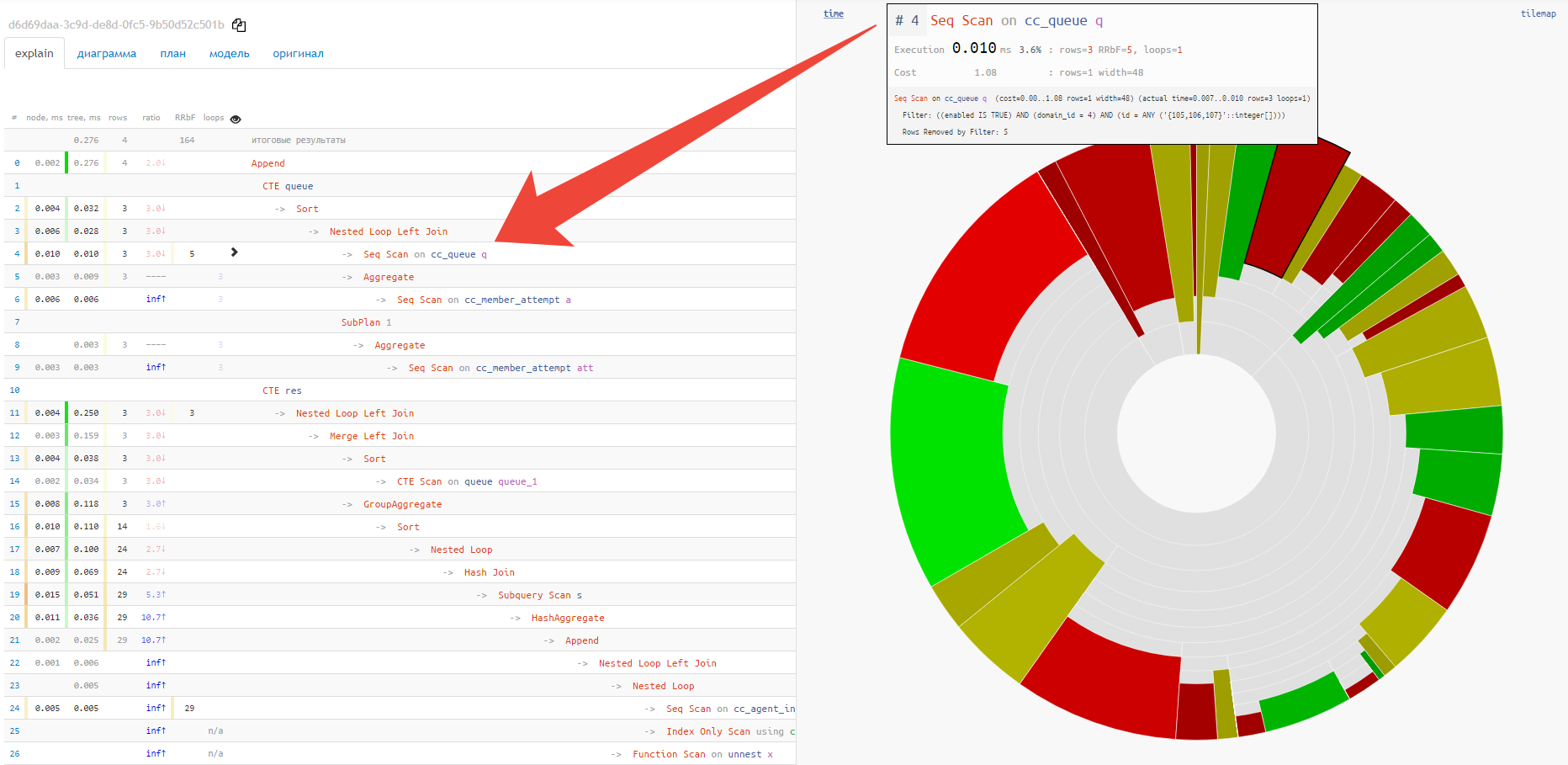
Сразу, навскидку, видна примерная доля потребления ресурсов каждым из узлов. При наведении на него, слева в текстовом представлении мы увидим иконку у выбранного узла.
Увы, piechart плохо показывает отношения между разными узлами и «самые горячие» точки. Для этого гораздо лучше подойдет вариант отображения «плиткой»:
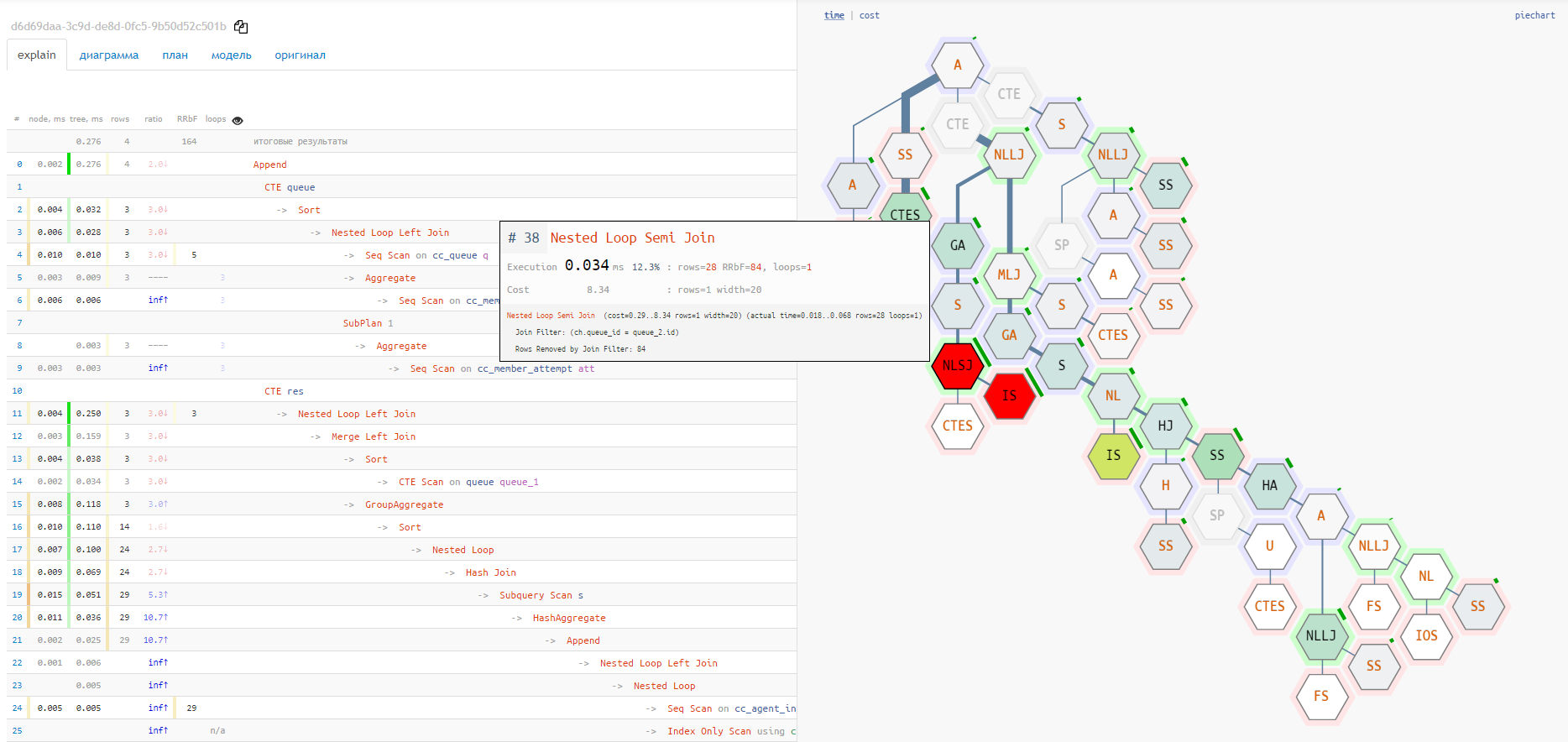
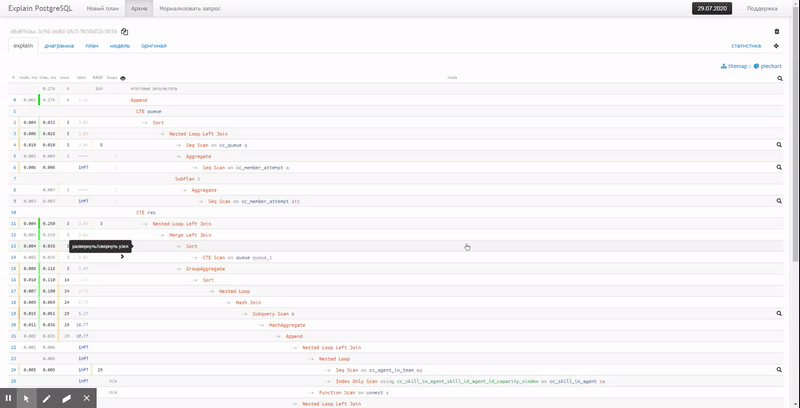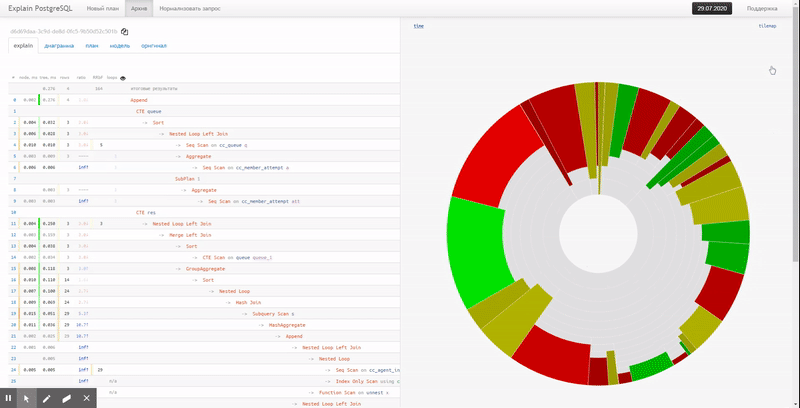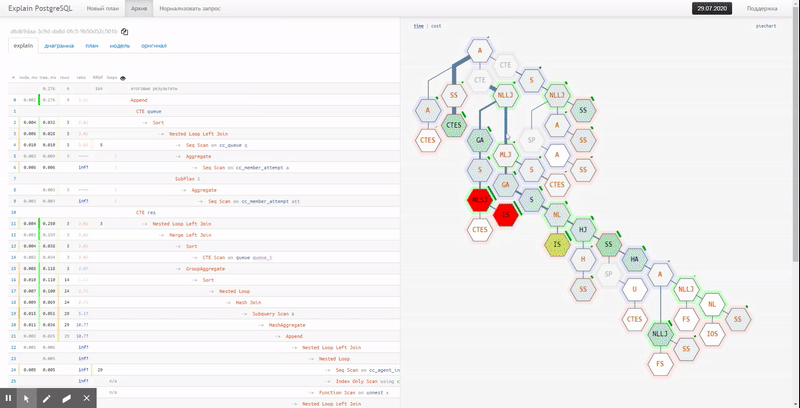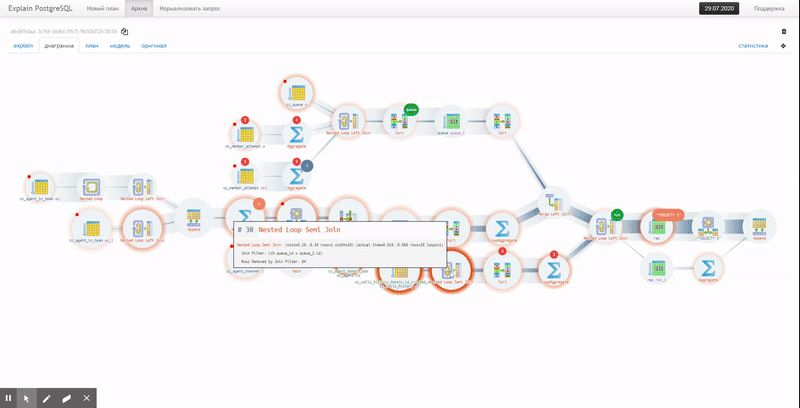
Но оба эти варианта не показывают полную цепочку вложений служебных узлов

Если вы снимаете план реального выполнения запроса как
Например, выполняя запрос на «непрогретом» кэше вы получите (но не увидите!) время получения данных с носителя, а вовсе не работы самого запроса.
Поэтому пара рекомендаций:
И вот если ваш план содержит не только время, но и

Предыдущие статьи по теме:
В этом нам помогут различные варианты визуализации:
Сокращенный текстовый вид
Оригинальный текст достаточно несложного плана уже вызывает проблемы при анализе:
Поэтому мы предпочитаем сокращенный вид, когда влево-вправо вынесена ключевая информация о времени выполнения и использованных buffers каждого узла, и очень просто заметить максимумы:
Круговая диаграмма
Но иногда даже просто понять «где болит сильнее всего» непросто, особенно, если он содержит несколько десятков узлов и даже сокращенная форма плана занимает 2-3 экрана.
В этом случае на помощь придет обычная круговая диаграмма:
Сразу, навскидку, видна примерная доля потребления ресурсов каждым из узлов. При наведении на него, слева в текстовом представлении мы увидим иконку у выбранного узла.
Плитка
Увы, piechart плохо показывает отношения между разными узлами и «самые горячие» точки. Для этого гораздо лучше подойдет вариант отображения «плиткой»:
Диаграмма выполнения
Но оба эти варианта не показывают полную цепочку вложений служебных узлов
CTE/InitPlain/SubPlan — его можно увидеть только на диаграмме реального выполнения:Нужно больше метрик!
Если вы снимаете план реального выполнения запроса как
EXPLAIN (ANALYZE), то увидите там только затраченное время. Но очень часто этого недостаточно для правильных выводов!Например, выполняя запрос на «непрогретом» кэше вы получите (но не увидите!) время получения данных с носителя, а вовсе не работы самого запроса.
Поэтому пара рекомендаций:
- Используйте
EXPLAIN (ANALYZE, BUFFERS), чтобы увидеть объем вычитываемых страниц данных. Эта величина практически не подвержена колебаниям от нагрузки самого сервера и может быть использована в качестве метрики при оптимизации. - Используйте
track_io_timing, чтобы понимать, сколько именно времени заняла работа с носителем.
И вот если ваш план содержит не только время, но и
buffers или i/o timings, то на каждой из вариантов диаграмм вы сможете переключиться в режим анализа этих метрик. Иногда можно сразу увидеть, например, что больше половины всех чтений пришлось на единственный проблемный узел:Предыдущие статьи по теме:
Fragster
Это прекрасно!