

В этой статье много замечательных моментов, которые показывают, почему тестирование улучшает доставку, производительность и долгосрочную прибыльность любого программного продукта или услуги для бизнеса всех видов и отраслей промышленности. Специально к старту нового потока нашего курса по ML и его расширенной версии Machine Learning и Deep Learning мы покажем, как с помощью PyTest создать эффективные тестовые функции для простого модуля машинного обучения.
Сегодня, в 2021 году, мы видим, что инструменты, платформы и сервисы для интеллектуальной обработки данных и машинного обучения всё чаще внедряются почти во всех отраслях: здравоохранение, финансы, производство, розничная торговля, развлечения, транспорт…
Машинное обучение затрагивает или затронет в будущем почти все аспекты нашей жизни. Естественно, мы должны ожидать, что эти сервисы опираются на высококачественную надёжную программную основу, которая угадывает мой любимый ресторан или уверенно направляет меня, когда я теряюсь в новом городе. Доверие к этим сервисам, которые часто кажутся волшебными, может возникнуть, только если я знаю, что лежащее в его основе программное обеспечение протестировано с использованием проверенной и надёжной методологии.
Во многих случаях темпы развития таких новых видов сервисов даже выше, чем у традиционных программных продуктов. Ускорение разработки продукта часто происходит в ущерб его качеству. Хорошая стратегия тестирования программного обеспечения может помочь компенсировать этот компромисс.
Поэтому чрезвычайно важно убедиться, что эти новые инструменты протестированы на наличие грандиозных функций и возможностей, которые обещаны конечному клиенту: масштабируемость, точность, адаптивность и т. д.
PyTest — что это и зачем?
Что такое PyTest? Согласно официальному сайту «PyTest — это зрелый полнофункциональный инструмент тестирования кода Python, который помогает писать более качественные программы».
Вместе с установкой Python предлагается встроенный модуль тестирования под названием unittest, но у него имеется несколько недостатков. В этом репозитории GitHub точным интуитивно понятным способом обобщаются некоторые тестовые сценарии между этими двумя модулями.
В Интернете есть много удобных ресурсов для обучения и практических занятий с помощью PyTest. Здесь можно найти вводный туториал. А вот более всеобъемлющий и чуть более продвинутый курс (работа с шаблонами проектирования).
Однако я чувствовал нехватку специальных учебных пособий, в которых основное внимание уделялось использованию PyTest для модулей машинного обучения с понятными примерами. Это моя первая попытка решения этой проблемы.
Я советую читателю ознакомиться с базовым использованием PyTest с простыми программами и функциями Python, прежде чем углубляться в эту статью, поскольку она предполагает наличие базовых знаний. Тогда давайте приступим к делу.
Модуль PyTest для функции обучения модели из библиотеки Scikit-learn
Эта статья основана на примерах, а самый образцовый пример, который я смог придумать, — это тестирование функции машинного обучения на основе Scikit-learn с помощью PyTest. Это сценарий, с которым, скорее всего, рано или поздно сталкивается любой практик машинного обучения на Python. Репозиторий GitHub для этого примера находится здесь. А вот идея, которую мы собираемся исследовать:

Запуск PyTest на примере этого репозитория
Установите PyTest командой pip install pytest.
Скопируйте или клонируйте два скрипта Python из репозитория на Github.
В linear_model.py есть единственная функция, которая обучает простую модель линейной регрессии с помощью Scikit-learn. Обратите внимание, что этот скрипт содержит тесты базовых утверждений и конструкцию try-except для обработки потенциальных ошибок ввода.
Файл test_linear_model.py — это тестовый модуль, который выступает в качестве входных данных для программы PyTest.
В своём терминале выполните команду pytest test_linear_model.py -v, чтобы запустить тесты. Вы должны увидеть что-то вроде этого:
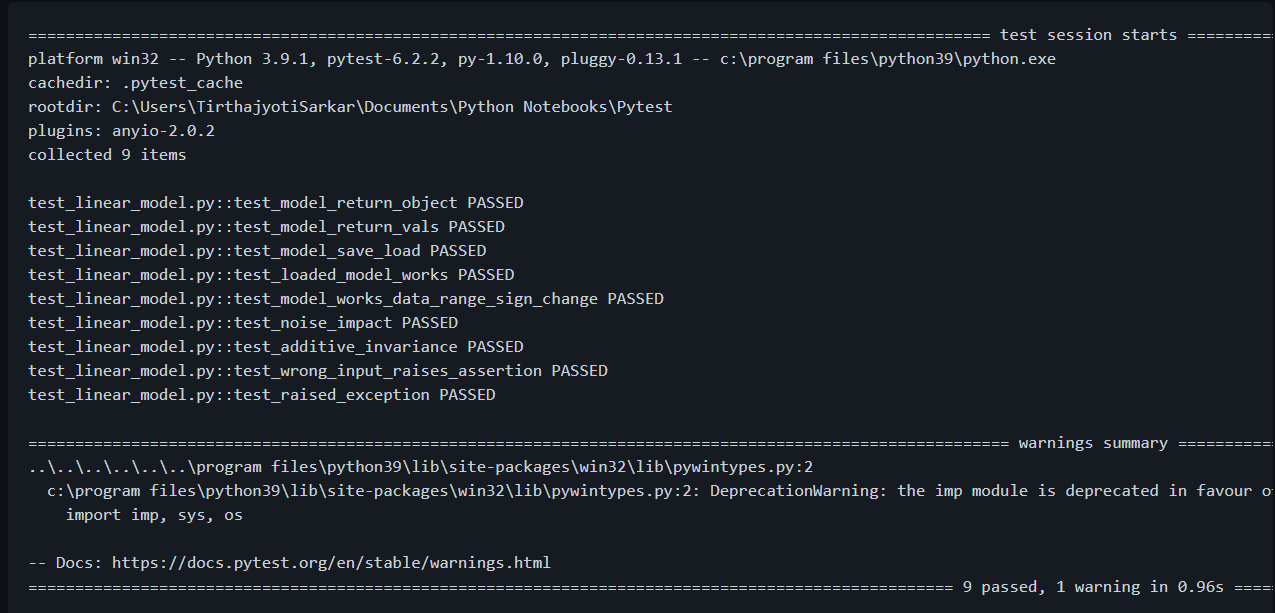
Что это значит?
Сообщение в терминале (выше) указывает, что выполнено 9 тестов (соответствующих 9 функциям в модуле test_linear_model.py) и все они пройдены. Оно также показывает порядок выполнения тестов (так как при выполнении команды pytest в командную строку был включен аргумент -v). PyTest позволяет рандомизировать последовательность тестирования, но обсуждение этого отложено на другой день.
Как выглядит моя основная функция машинного обучения?
Давайте посмотрим на тестируемую основную функцию машинного обучения. Это простая функция, которая обучает модель линейной регрессии с помощью библиотеки Scikit-learn и возвращает оценку R?. Она также сохраняет обученную модель в локальной файловой системе. Я собираюсь показать вам функцию в двух частях, потому что я хочу, чтобы вы обратили внимание на множество операторов assert в первой части.
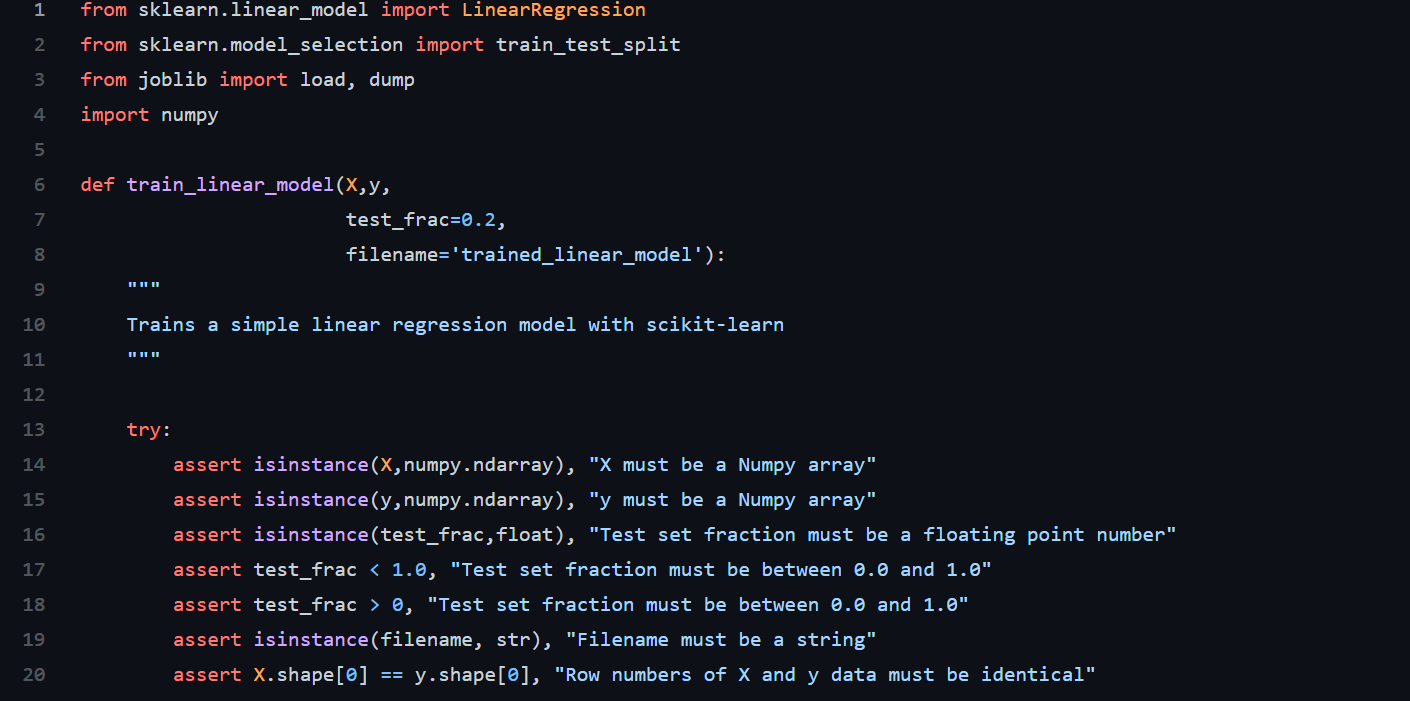
Если достаточно долго смотреть на код, легко понять, что в данную функцию уже встроено большое количество кода проверки типов и обнаружения ошибок. Если функция уже тестирует типы своих входящих данных и диапазоны, то что мы проверяем с помощью PyTest?
PyTest не проверяет ваши данные. Этот инструмент проверяет ваш код/программу.
Вам всё равно придётся прописать все виды данных и ввести код проверки в свою основную функцию, чтобы обеспечить целостность данных и справиться со странными ситуациями, когда ваша функция машинного обучения развёртывается в реальной производственной системе.
Кроме того, во время разработки можно записать модули PyTest, чтобы узнать, ведет ли написанная функция себя так, как ожидалось, или нет. И это включает в себя его поведение в отношении самой проверки ошибок.
В этом примере мы записываем группу операторов assert в исходной функции train_linear_model и оборачиваем их вокруг целого блока try...except. Данный тестовый код только проверяет, возвращаем ли мы ошибку AssertionType для таких неправильных случаев ввода и печатается ли правильное сообщение об ошибке для конечного пользователя. Чтобы подкрепить эту идею, позвольте мне частично повторить общую схему, приведённую выше:

Таким образом, такие элементы, как обработка ошибок или проверка векторной формы, являются лишь частью общего шаблона проектирования вашей функции. Они обрабатываются в PyTest так же, как и другие шаблоны, характерные для машинного обучения, такие как предварительная обработка данных или подгонка модели.
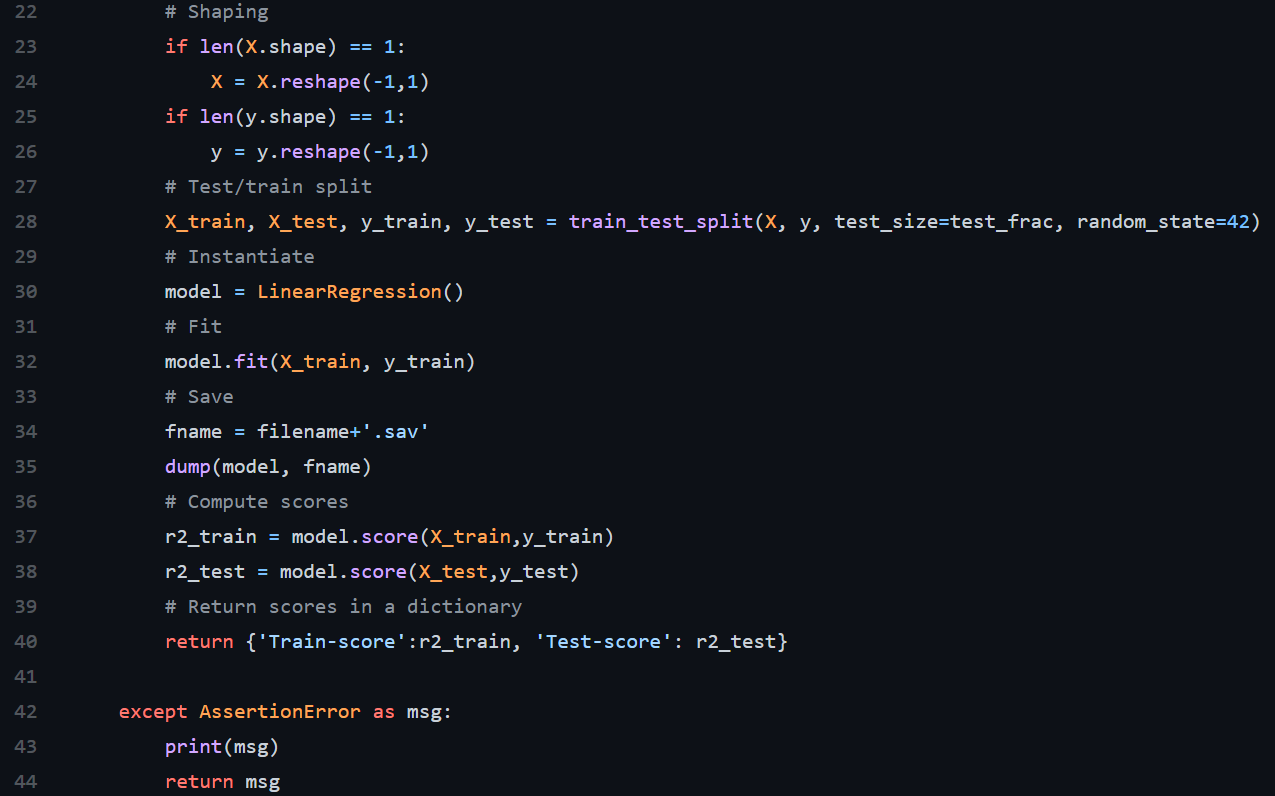
Эта метка соответствует остальной части функции. Здесь не так много операторов, просто обычные элементы машинного обучения. Можно вставить в эту функцию два массива Numpy, и она выполнит внутреннее разделение наборов на тестовый и обучающий, подгонит модель по обучающей выборке, оценит модель по тестовому набору и вернёт оценку.
Примеры функции машинного обучения для отлавливания ошибок
Хотя это напрямую не относится к PyTest, было бы полезно увидеть в действии, как некоторые из этих операторов контроля улавливают ошибки. Вот некоторые данные и нормальное выполнение:

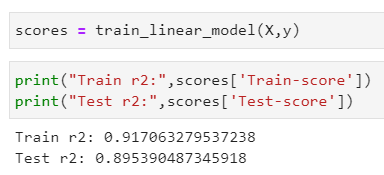
Вот несколько примеров, которые могут возникнуть в производственных системах и могут быть обработаны с помощью этой функции.

Теперь давайте рассмотрим модуль PyTest
Если посмотреть на модуль PyTest, первое, что бросается в глаза, — это размер самого кода! Чтобы протестировать 42-строчный модуль, нам пришлось написать около 300 строк кода!

Это нормально. Чем больше функций и возможностей требуется протестировать, тем длиннее набор тестов. То же самое касается тестирования большего количества ситуаций или пограничных случаев. Вы можете подробно ознакомиться с кодом. Я просто упомяну некоторые из существенных характеристик.
Обратите внимание, что в test_linear_model.py имеется 9 функций с именами, начинающимися с test. Они содержат фактический тестовый код.
В этом файле также есть несколько функций конструктора данных, имена которых не начинаются с test, и они игнорируются PyTest. Но они нужны нам для целей тестирования опосредованно. Конструктор random_data_constructor даже принимает аргумент noise_mag, который используется в целях управления величиной шума для тестирования ожидаемого поведения алгоритма линейной регрессии. Для этого смотрите функцию test_noise_impact.
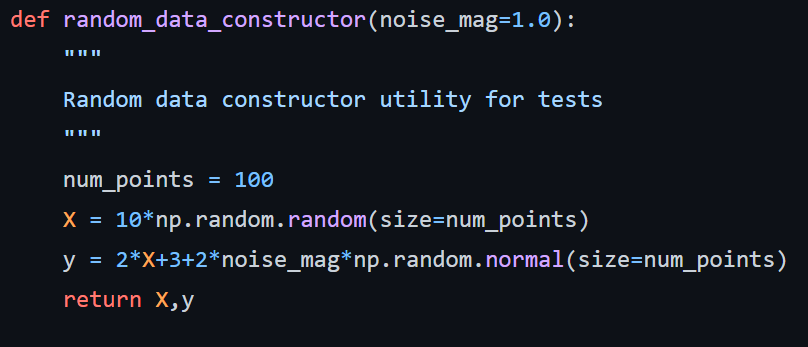
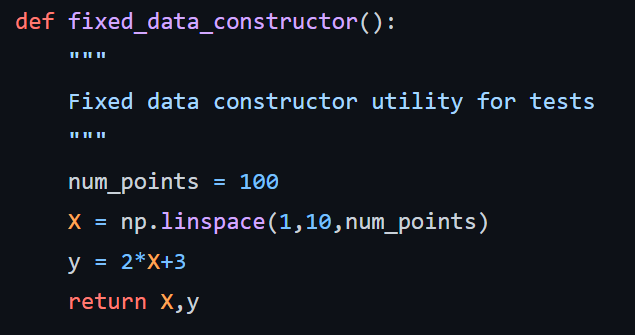
Обратите внимание, что нам нужно импортировать множество библиотек для тестирования всех возможных аспектов. Например, мы импортировали библиотеки, такие как joblib, os, sklearn, numpy и, конечно же, функцию train_linear_model из модуля linear_model.

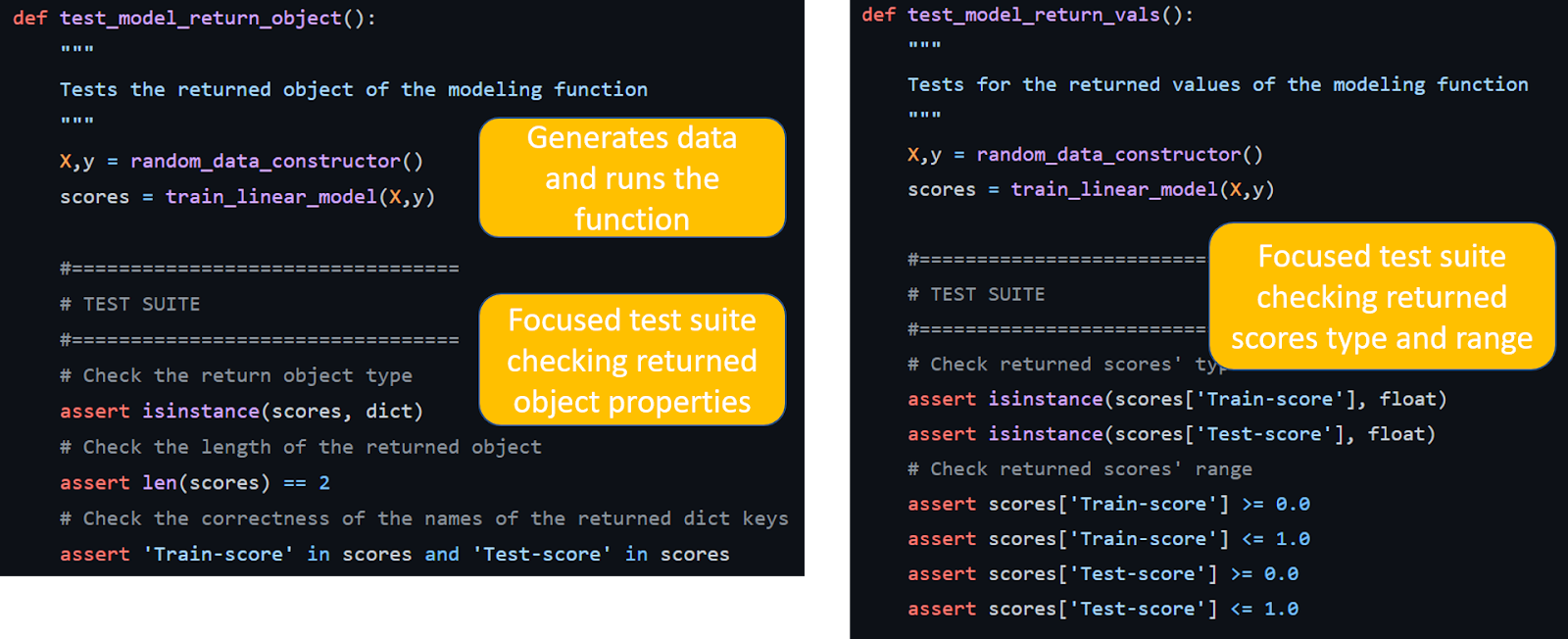
Обратите внимание на понятные, чёткие имена для функций тестирования, например test_model_return_object(), которая проверяет только возвращаемый из функции train_linear_model объект, или test_model_save_load(), которая проверяет возможность правильной загрузки сохранённой модели (но не пытается делать прогнозы или что-либо ещё). Всегда пишите короткие и точные тестовые функции, сфокусированные на чём-то одном.
Для проверки прогнозов, например, действительно ли работает обученная модель, у нас есть функция test_loaded_model_works(), которая использует генератор фиксированных данных без шума (по сравнению с другими случаями, когда мы можем использовать генератор случайных данных со случайным шумом). Она передаёт фиксированные данные X и y, загружает обученную модель, проверяет, в точности ли оценки R? (коэффициент регрессии) равны 1,0 (верно для фиксированного набора данных без шума), а затем сравнивает прогнозы модели с исходным вектором истинности y.
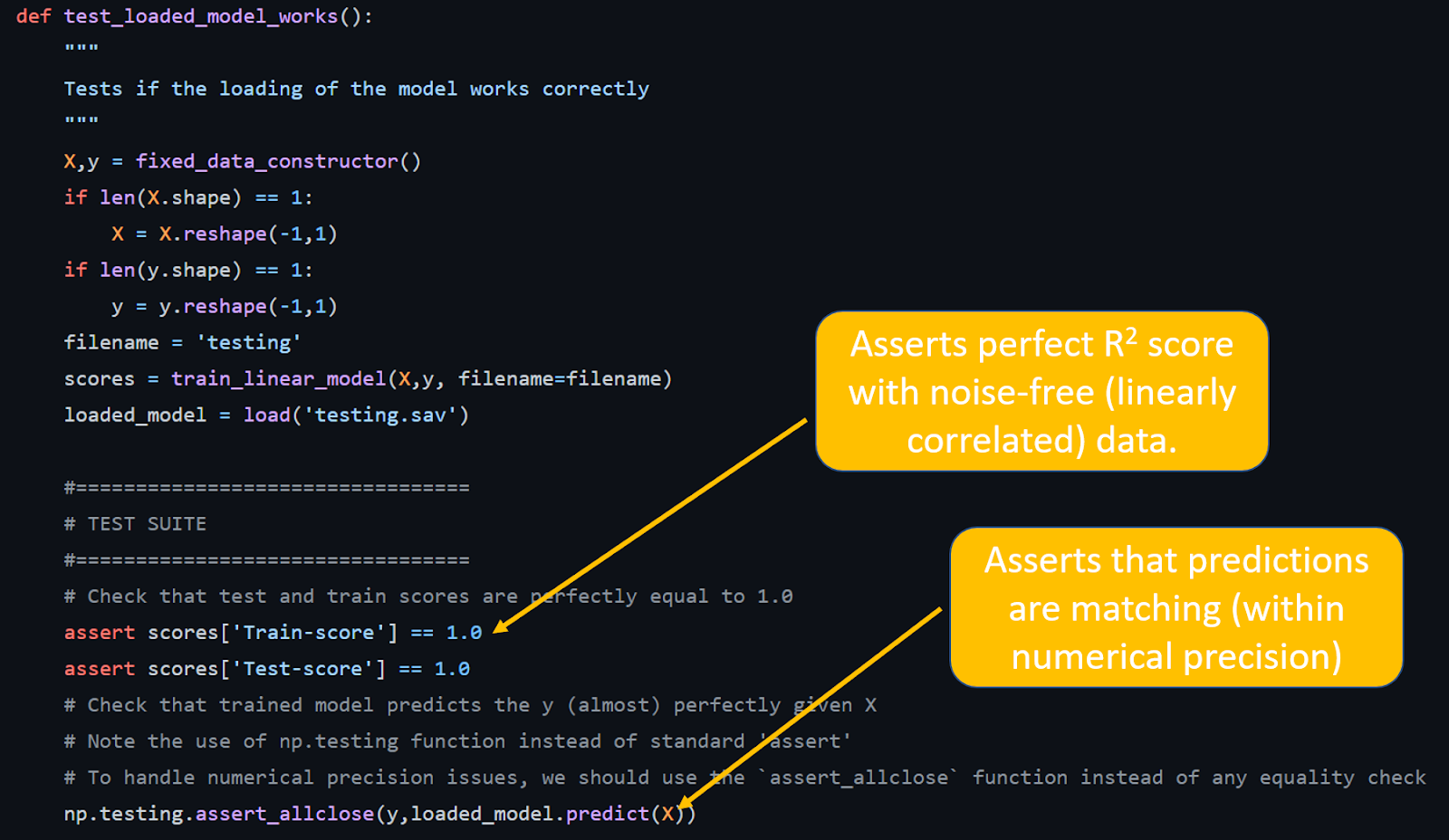
Обратите внимание, как вышеупомянутая функция тестирования использует специальную функцию тестирования Numpy np.testing.assert_allclose вместо обычного оператора assert. Это делается для того, чтобы избежать любых потенциальных проблем с числовой точностью, связанных с данными модели, т. е. массивами Numpy и алгоритмом прогнозирования, включающим операции линейной алгебры.
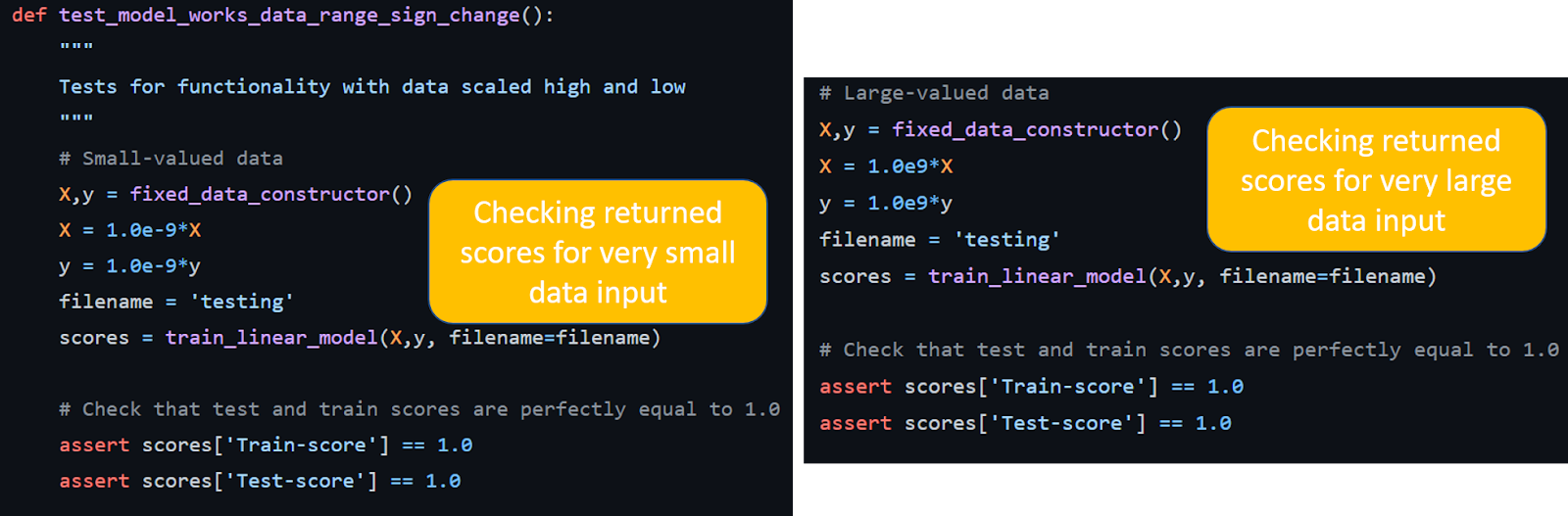
Функция test_model_works_data_range_sign_change тестирует ожидаемое поведение алгоритма оценки линейной регрессии — оценки регрессии по-прежнему должны быть равны 1,0 независимо от диапазона данных (масштабирование данных на 10e–9 или 10e+9). Ожидаемое поведение также изменяется, если у данных каким-то образом меняется знак.
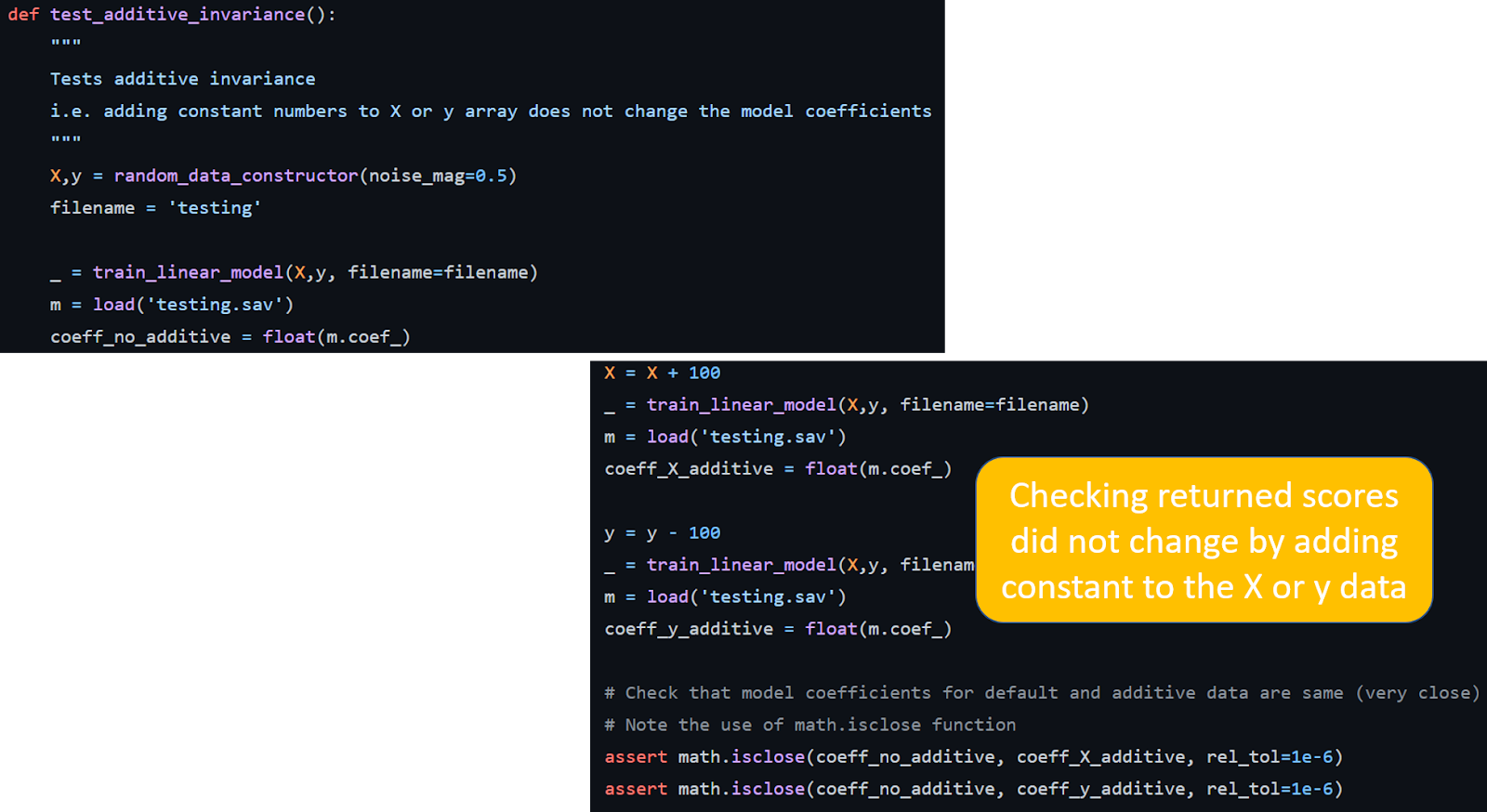
Функция test_additive_invinance тестирует свойство аддитивной инвариантности оценки линейной регрессии. Аналогично вы должны подумать об особых свойствах своего алгоритма оценки машинного обучения и написать для них индивидуальные тесты.
Взгляните на функцию test_wrong_input_raises_assertion, которая проверяет, вызывает ли исходная функция моделирования правильное исключение, и сообщения при подаче неправильных входных аргументов различных типов.
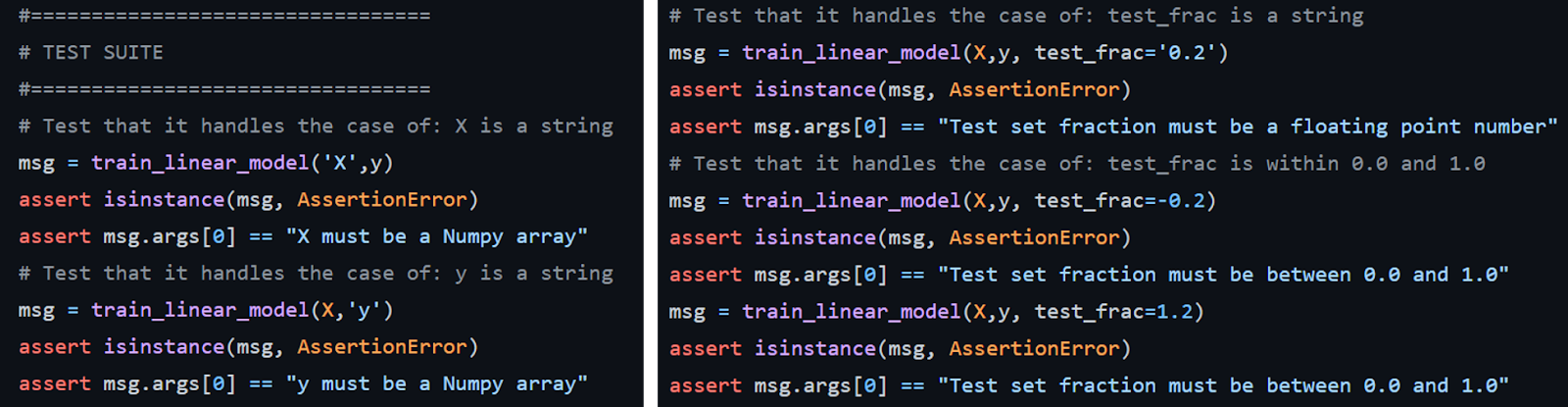
Наконец, функция test_raised_exception проверяет возникновение исключений других типов (т. е. отличных от AssertionError, которые могут быть вызваны операторами assert в функциональном модуле) во время выполнения с помощью специальной функции PyTest — менеджера контекста pytest.raises.

Чем больше функций и возможностей требуется протестировать, тем больше набор тестов. То же самое касается тестирования большего количества сценариев или пограничных случаев.
Сводная информация
В этой статье мы показали, как создать модуль PyTest или набор тестов для простого функционального модуля линейной регрессии. Мы затронули некоторые общие принципы написания тестов, например, проверку типов данных и формы входного вектора, а также аспекты, характерные для задачи машинного обучения, например, как должен вести себя алгоритм оценки линейной регрессии при изменении масштаба данных.
PyTest — это лёгкая и простая в использовании утилита, достаточно гибкая для создания мощных шаблонов проектирования в наборе тестов. Вы можете воспользоваться преимуществом этого инструмента и сделать пакет для интеллектуальной обработки данных и машинного обучения гораздо более надёжным и высокопроизводительным.
Вы можете просмотреть репозитории автора на GitHub, содержащие код, идеи и ресурсы по машинному обучению и интеллектуальной обработке данных.
А если вы хотите научиться работать с данными и обрабатывать их помощью машинного обучения — обратите внимание на наш курс по ML или на его расширенную версию Machine Learning и Deep Learning, партнёром которого является компания Nvidia.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ