

Бюро статистики труда США прогнозирует, что в следующие 10 лет спрос на специалистов Data Science и Machine Learning значительно вырастет. Условия вакансий становятся лучше, а потребность в Data Science увеличивается в IT, маркетинге, консалтинге и других сферах. К старту флагманского курса по науке о данных представляем сокращённый перевод анализа более 3000 вакансий Data Science в США.
Топ активно нанимающих компаний

Accenture на первом месте в США по количеству вакансий, за ней следуют Amazon, Apple и Facebook. Ведущие нанимающие компании — это компании социальных сетей и платформы электронной коммерции и обработки платежей, такие как PayPal и Google Pay.
Большое количество ежедневных взаимодействий с клиентами — это тысячи гигабайт данных. Accenture plc. — ирландская транснациональная компания, предоставляющая консалтинговые услуги, услуги аналитиков и другие услуги, что требует большого количества квалифицированных Data Scientist и инженеров.
Расположение нанимающих компаний

Благодаря Силиконовой долине на Сан-Франциско приходится примерно 15 % объявлений о вакансиях. Этой тенденции следуют Сиэтл, Сан-Хосе, Остин, Бостон, Нью-Йорк, Сан-Диего, Денвер, Даллас, Питтсбург и так далее города: на их долю приходится значительная часть всех рабочих мест в сфере Data Science в стране.
Удивительно, что Питтсбург попал в топ-10: 2,55 % вакансий для специалистов Data Science размещены в этом городе — производителе стали. Именно там соискатели могут увеличить свои шансы получить работу своей мечты.
Требуемый опыт

Видно, что организации ищут опытных специалистов по обработке данных в диапазоне опыта 5–10 лет, что составляет 17 % от общего числа требуемых людей, и 3–8 лет, а это 13 %. К сожалению, количество вакансий начального уровня небольшое и почти нет вакансий для новичков, что осложняет поиск работы.
Этот анализ также показывает, насколько незрел рынок в области науки о данных. Для новых талантов возможностей нет, а перспективным молодым специалистам трудно набраться опыта, а значит, новички должны быть лучшими в своём деле и стараться выделиться из толпы.
Должности, предлагаемые ведущими компаниями

Удивительно, что организации в поиске опытных специалистов называют должность просто Data Scientist. Значительная доля вакансий предназначена для профессионалов с опытом работы от 5 до 10 лет. На долю вакансий старшего специалиста приходится 22 % от общего числа требований.
Отрадно видеть, что ассоциаты [люди, окончившие первые два курса бакалавриата] входят в пятёрку. Тем не менее статистика заставляет нас задаться вопросом: каким уровнем опыта должны обладать ассоциаты? Как всегда, ответ кроется в самих данных.
Динамика вакансий по уровню опыта
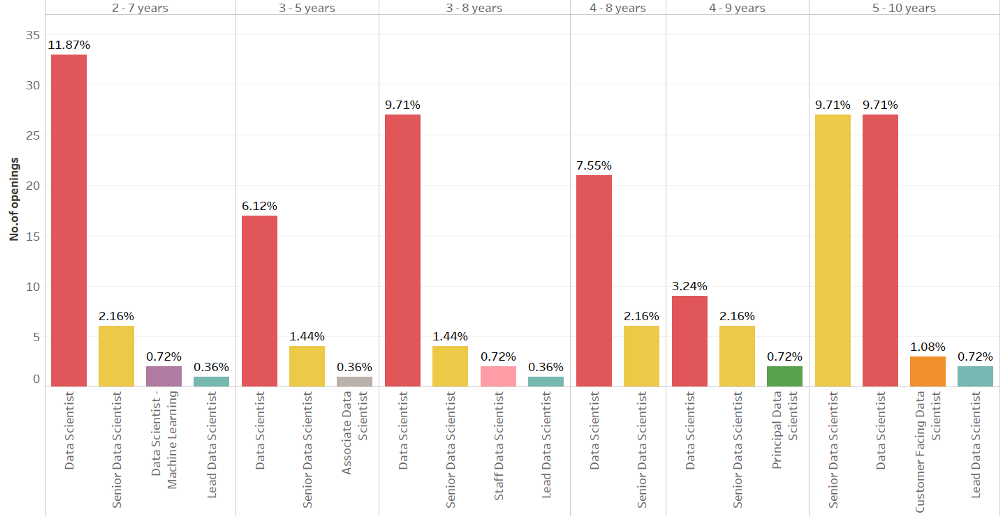
Участники группы с уровнем опыта 5–10 лет имеют равные возможности получить работу Data Scientist и Senior Data Scientist, каждая из которых содержит 9,17 % вакансий. В группе с опытом 2–7 лет приходится 2,16 % вакансий Senior Data Scientist и 0,36 % — для ведущего специалиста. Требования к ассоциату — это 3–5 лет опыта.
Топ-15 востребованных навыков

Посмотрим на 15 навыков, обязательных для любого Data Scientist. Программирование на Python, аналитика и машинное обучение — топ-3 самых востребованных навыков. У большинства людей сложилось представление, что SQL для Data Scientist требуется меньше всего, однако он входит в первую пятёрку.
Топ языков программирования
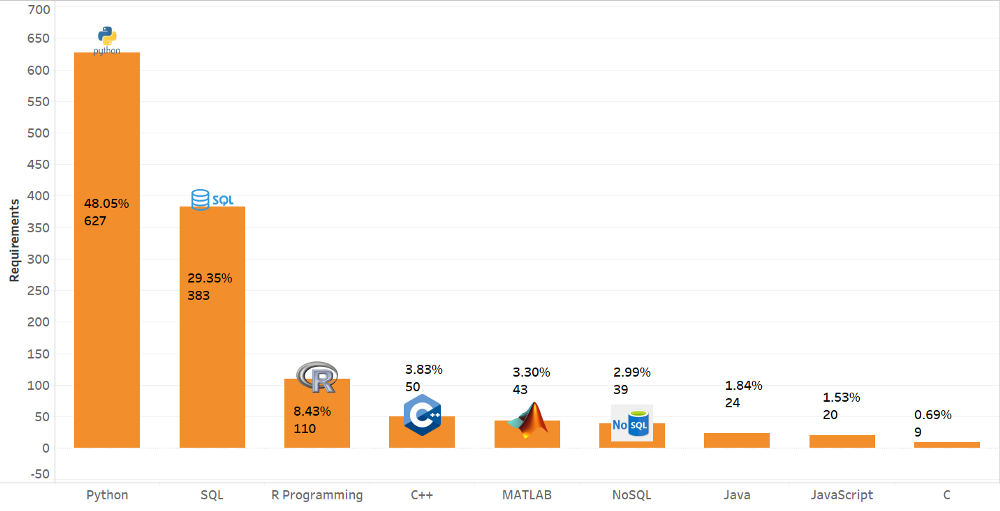
Исходя из нашего анализа, на долю Python приходится почти 50 % от общего спроса в объявлениях о вакансиях, на втором месте SQL, поэтому крайне важно обладать навыками работы на Python и SQL.
Удивительно, но C++ входит в топ-5 требований к языку программирования, а это составляет 3,8 % от общего числа. Доля MATLAB — 3,3 % от общего спроса. MATLAB — это платформа программирования и вычислений, миллионы инженеров и учёных с её помощью анализируют данные, разрабатывают алгоритмы и создают модели.
Топ инструментов визуализации данных

Tableau — это платформа визуальной аналитики, которая трансформирует работу с данными, позволяя извлечь из данных максимум.
Power BI — это набор программных сервисов, приложений и коннекторов, превращающих ваши несвязанные источники данных в согласованную, захватывающую и интерактивную презентацию.
Ваши данные могут быть электронной таблицей Excel, локальным или облачным хранилищем. Power BI позволяет легко подключаться к источникам данных, визуализировать и находить в них необходимое, а затем делиться результатами с кем угодно.
Tableau и Power BI более или менее одинаковы. Хотя Power BI — продукт Microsoft, которой доверяют, Tableau в отрасли наиболее предпочтительна. Давайте разберёмся в причинах популярности.
Power BI создана для всех заинтересованных лиц, необязательно профессионалов в аналитике. В работе с Tableau у аналитиков возникает меньше проблем с очисткой, преобразованием и визуализацией данных.
Tableau работает быстрее и предоставляет множество передовых методов, таких как параметры и пользовательские вычисления.
Поскольку собранные данные касаются Data Science, а Tableau лучше подходит профессиональным аналитикам, в этой ситуации отдаём предпочтение Tableau.
Топ фреймворков Deep Learning

Фреймворков глубокого обучения множество, но самые популярные — Tensorflow, Keras и PyTorch. Они предоставляют набор библиотек для работы с методами глубокого обучения и для эффективного использования аппаратного обеспечения GPU. TensorFlow от Google, на долю которой приходится 43 % общего спроса, по-видимому, самая востребованная, за ней следуют Keras и PyTorch.
Топ технологий больших данных

Apache Spark, Hadoop, Hive и Kafka — самые популярные технологии, с которыми сегодня работают компании. Похоже, что Apache Spark и Hadoop имеют преимущество перед другими технологиями больших данных.
Топ веб-фреймворков и технологий

Создание модели машинного обучения — одна из основных задач, а внедрение модели в производство, чтобы с ней могли работать нетехнические специалисты — ещё одна актуальная задача жизненного цикла в науке о данных.
Развёртывание, как правило, осуществляется в форме веб-приложения, и отрасль ожидает, что специалист обладает навыками и знаниями в области веба для развёртывания любой модели ML. MongoDB, Django, JavaScript и HTML на рынке наиболее популярны. Владение ими необходимо, чтобы в отрасли быть на шаг впереди.
Заключение
Выглядит ошеломляюще, но необязательно обладать всеми этими навыками сразу. Выберите один или два, самое большее три и специализируйтесь, глубоко погрузившись в них. До погружения в изучение навыков выше, пожалуйста, освойте на базовом уровне статистику и линейную алгебру. Важнее всего иметь практические знания в виде проектов, хакатонов, солидного профиля на Github и т.д. Кроме того, блог или канал — отличное дополнение к вашему резюме.
Если вам интересна сфера Data Science и Machine Learning, присмотритесь к нашей двухлетней программе обучения науке о данных, где есть всё необходимое, чтобы вы изменили карьеру и оставались востребованным специалистом в будущем. Также вы можете узнать, как начать карьеру или прокачаться в других направлениях IT:

Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:
capjdcoder
Все бы конечно хорошо, но после фразы с вашего сайта: "Узнайте, сколько вы теряете денег, так и не решившись стать дата-сайентистом" пропало желание смотреть дальше.
sergey_shambir
Это же skillfactory, они не шибко ценят глубину, качество или уровень конверсии в специалистов и работают на количество и конверсию денежную. Похоже на зарубежные кемпинги, где за 3 месяца человека учат кое-как программировать и хорошо скрывать это на собеседованиях.