
В нашей компании (GFN.ru) мы очень сильно опираемся на данные. По каждой игровой сессии мы анализируем десятки параметров. Постройка и содержание системы метрик и алертов - очень затратная вещь и со временем ее поддержка становится трудоемкой и появляется риск забивания. С помощью ML мы решили эту проблему.
Размышлизмы
Хорошая современная система обвешана метриками. В нашем случае, после того, как пользователь поиграл, мы получаем статистику по его сессии - какой был битрейт, какой раундтрип, джиттер и еще много других метрик. Исходя из них, у нас загораются разные лампочки: либо с одним из наших аплинков в каком-то регионе что-то не то, а может быть и игровой стэк для какой-то игры работает не очень хорошо.
Построение системы метрик и алертов, как я писал выше, это большая работа. Во-первых, конечно, нужно придумать какие метрики анализировать. Потом, для каждой метрики необходимо определить пороги срабатывания алерта. Потом, необходимо продумать методику отсекания шума (моя предыдущая заметка). Когда таких метрик становится больше пары десятков, то за пол года это превращается в тяжелое бремя для выделенного человека, а то и трех. Если же метрики сложные и зависят от многих факторов, то приходится выводить метрики не только второго, но и третьего порядка.
Возьмем, например, битрейт видеопотока игры. Битрейт зависит от самой игры - в тетрисе битрейт низкий, в контре во время замеса - высокий. Еще, битрейт зависит от расстояния между пользователем и кластером, от соединения пользователя. Поэтому, невозможно поставить алерт - если битрейт меньше 5 мегабит, то горит лампочка.
Здесь мы приходим к понятию "нормальное значение метрики". Следить нужно не за самим показателем, а за динамикой его изменения. Если динамика находится в каких-то границах (это уже легко захардкодить), то всё хорошо, если у нас появляется резкое изменение динамики - скорее всего, тут проблема. Здесь, я обычно, вставляю для сына: да, матан и производные не нужны, а косинусы - это то, что солят в банках :). И того, задача сводится к поиску всплесков. Изначально, я хотел решить эту задачу с помощью индикаторов из теханализа - Ленты Боллинджера, EMA, MACD - отлично подходят под решение подобной задачи. Однако, у них есть существенный недостаток - они не учитывают людскую природу, которая в нашем случае важна. Она выражается в том, что в пятницу вечером, либо в новогодние праздники - пользователи играют гораздо активнее. Если пользователи сидят на вайфае, то в эти дни наблюдается загруженность эфира соседями - они ведь тоже хотят посидеть в выходные в тиктоке/етубчике. Так или иначе - нужно учитывать и дни недели и праздники. Для этих дней показатель "нормально" будет другим.
В принципе, для простого решения задачи достаточно выбрать тот индикатор ТА, который работает для метрики, и строить не 1 временной ряд, а 7 - по дням недели. Анализировать не каждый день, а только пятницы в одной группе, только субботы и так далее. На горизонте в 1 год и больше - это даст хорошую экономию человекоресурсов на поддержку, а ВНЕЗАПНЫЕ праздники можно воспринимать как неизбежное зло, которое выражается в большом количестве ложных срабатываний.
Более правильный вариант - это использовать Machine Learning. В данном случае - использовать модель ArimaPlus, которая всё это, включая локальные праздники, содержит под капотом. Так как Google BigQuery и GCE в целом, представляет полный и весьма удобный набор инструментов для работы с большими данными, в том числе, с использованием AI и ML (как supervised, так и unsupervised), мы разработали решение, которое позволяет на базе стэка Гугла сделать автоматический анализ различных метрик. Решение выложили в опенсорс и его можно форкнуть отсюда.
К делу!
Ниже я приведу пример, как на базе Adet (Anomaly Detector) можно найти различные всплески, с порогом входа в виде базового курса какой-нибудь онлайн-обучалки по SQL.
Важное замечание: GCE может быть очень дорогой штукой. Следите за количеством данных. BigQuery с вас берет деньги за просканированные данные. Чем больше данных вы просканируете в каждом запросе - тем больше заплатите. Забудьте про
select *.ML стоит еще дороже - поэтому, внимательно подходите к метрикам - чем больше обучающий датасет, тем дороже обойдется его обучение.
Подразумевается, что вы уже развернули Adet у себя в облаке, как написано в инструкции по развертыванию.
У нас есть временной ряд с группами и различными метриками. Ряд представлен следующей вьюшкой:
create or replace view analytics3.session_metrics as
(
select date(session_start) as session_date, geo, avg(streaming_bitrate) as bitrate,
avg(jitter) as jitter,
count(1) as session_count
from data.sessions_data
where session_start between '2020-05-01' and '2020-06-20'
group by 1, 2
order by 1 desc)Ряд состоит из полей: geo - город. bitrate, jitter - соответственно средний битрейт и средний джиттер, дата сессии, и количество сессий. Группировка осуществляется по паре дата и город. Можно добавить сколько угодно групп, но для примера достаточно и так.
Если мы посмотрим на график в датастудии, то увидим всплески. С помощью Adet мы и попробуем их найти автоматически.

Для этого, мы опишем конфигурацию метрики. Конфигурация описывается в Google Sheets (NoCode!) и автоматически применяется. Если изменения конфигурации затронули конфигурацию модели, то модель будет перетренирована (пересоздана с нуля, на самом деле) в ближайший период тренировки.
Столбец |
Значение |
Комментарий |
type |
arima |
Тип модели - пока что, только arima |
alert |
Average bitrate |
Название аномалии |
table |
analytics3.session_metrics |
источник данных |
ml_columns |
bitrate |
колонка метрики |
grouping_columns |
geo |
колонка группировки (можно сделать несколько колонок через запятую) |
entity_column |
geo |
колонка сущности - не участвует в расчетах, но может быть полезна для фильтров. |
date_column |
session_date |
колонка таймстампа временного ряда. В настоящий момент - разрешение только по дням. |
population_col |
session_count |
колонка в которой содержится количество измерений для метрик второго порядка. В данном случае - на основании какого кол-ва сессий посчитано среднее |
min_population |
500 |
минимальное количество измерений, чтоб отсечь шум (см. стат. Значимость) |
train_window_days |
90 |
окно тренировки - тренирует по кол-ву дней в прошлое от самой свежей записи датасета. |
retrain_interval_days |
90 |
период перетренировки - как часто вызывается тренировка модели |
anomaly_threshold |
99.00% |
порог уверенности в аномалии. |
backfill_days |
2 |
окно, в рамках которого обновляются аномалии каждый раз. Например, "сегодня" стоит пересчитывать пока оно не станет "позавчера". |
error_check |
lower_bound<0 |
условие (тут формируется обычный IF) который показывает, что электроболван глючит. Например, если для какой-то аномалии, он посчитал нормальными границы от минус 10 до плюс 10, при этом, метрика не может быть отрицательной - явно там проблема и это может быть шум. |
explanation_format |
"Bitrate in %t on %t is %.3g, range %.3g-%.3g", geo, date(session_date), bitrate, lower_bound, upper_bound |
Параметры SQL команды FORMAT которая делает человеко-понятное описание для аномалии. |
comment |
комментарий для пользователя (нигде не выводится) |
После того, как мы заполнили конфигурацию - необходимо вручную запустить тренировку модели. Можно подождать сутки, и ночью тренировка запустится автоматически.
Мы не ждем, и выполняем команду call analytics3.adet_retrain_models();Иногда, она может отваливаться в самом конце с BigQuery internal Error. Но тренировка всегда завершается (если нет ошибок). Если ошибки есть - их можно увидеть в логе выполнения в SQL Console.
Результат тренировки можно увидеть в логе - таблица analytics3.adet_log

Видно, что тренировка модели этого алерта прошла успешно.
После этого - вызываем обновление аномалий: call analytics3.adet_anomaly_update(); апдейт опять же вызывается автоматически, но зачем ждать.
В логах опять же видим, что всё прошло хорошо.

А вот здесь - я накосячил с аргументами для FORMAT при подготовке к статье.

Обратите внимание, что каждая строчка лога содержит фактический запрос, который соответствующая функция пыталась выполнить. Его можно скопировать в SQL Console и посмотреть ошибки, а так же попробовать их исправить. Иногда эти запросы могут быть многоэтажными :)
Итак, тренировка прошла, аномалии получены, посмотрим, что же электроболван посчитал ненормальным.
Результат находится в двух таблицах: adet_cached_anomalies - это результат прогона данных через модель. Он содержит как аномалии так и нормальное поведение, но с соответствующими признаками.

Значения полей самодокументирующиеся, а те, которые нет - поясню чуть ниже.
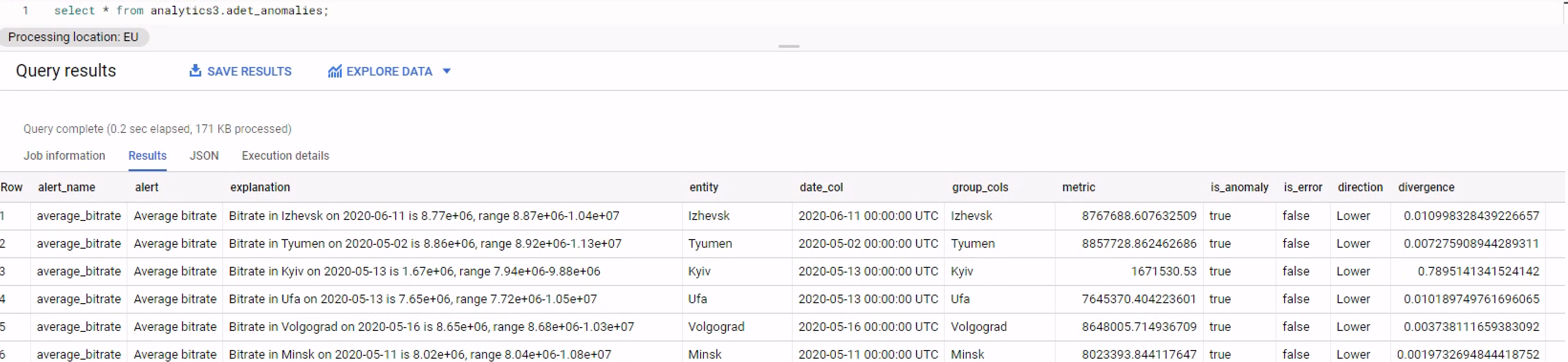
Вьюшка adet_anomalies. Она проста - берем из cached_anomalies то, что is_anomaly=true. Доп вьюшка нужна чтоб посмотреть на те даные, где система не посчитала аномалией.
Мы поймали провал по Киеву от 13 мая - это уже победа. Но есть еще много других аномалий, с которыми нужно разобраться отдельно. Это второй этап отсечения шума.
Возьмем, например, Тюмень. Пояснение выглядит следующим образом:
Bitrate in Tyumen on 2020-05-02 is 8.86e+06, range 8.92e+06-1.13e+07 |
Битрейт 8.86 мегабит. Границы того, что электроболван посчитал нормальным для этого дня и этой группы (город Тюмень) - 8.92 мегабита - 11.3 мегабита. Вероятно, FORMAT нужно здесь доработать - вместо %t использовать %f и округление.
В колонке Direction мы видим, что метрика ушла вниз от нормальных значений. Это позволяет определить хорошие и плохие аномалии. Если у вас количество продаж ушло вниз - это явно плохо, а если вверх, то вероятно, хорошо.
Модуль отклонения от ближайшей границы нормальных значений составляет 0.007275908944289311, то есть 0.7% (поле divergence). Соответственно, это шум. Отклонение 0.7% в моменте вряд ли на это отклонение нужно обращать внимание в первую очередь. Для сравнения, для Киева модуль отклонения составил 0.7895141341524142 : 78% вниз, и это уже серьезно.
Осталось сделать табличку в DataStudio которая выдаст данные из этой вьюхи - и можно отдыхать, не следя за сотней графиков.