
Нужен ли каждому разработчику свой dev-сервер? Многие компании, опасаясь лишних расходов и проблем, даже не пробуют внедрить такой подход.
CarPrice развернул свои dev-серверы еще в те далекие времена, когда все работало на монолите. А после монолита пилил собственный сервис для оркестрации dev-серверов на базе Docker, затем разворачивал их на Minikube и постепенно пришел к Kubernetes.
На связи ведущий инженер отдела DevOps CarPrice Михаил Чешуин. В этой статье я расскажу, как мы запускали dev-серверы в разные периоды — и как все работает сейчас
Сразу оговорюсь: нам сложно судить, насколько разработчикам и тестировщикам хуже живется без dev-серверов. Мы все-таки используем их почти 10 лет — все время, пока существует CarPrice. Но по этой же причине мы готовы долго говорить об их плюсах и преимуществах :)
Пара примеров:
Dev-серверы помогают организовать работу на удаленке и аутсорс: окружение не нужно поднимать локально на персональном ПК. Разработчику понадобятся только ресурсы для IDE, а тестировщику будет достаточно браузера и вспомогательного отладочного ПО.
Dev-серверы дают возможность запускать сервис в окружении других связанных с ним проектов в легко повторяемой конфигурации, максимально приближенной к продуктовой. Для архитектуры с несколькими сотнями сервисов это существенный плюс.
Правда, за удобство приходится платить: компании требуются дополнительные затраты ресурсов, чтобы развернуть полное окружение для каждого разработчика. Здесь важно учесть и аренду оборудования, и время сотрудников, которое уйдет на регулярные мониторинг и поддержку.
И все-таки мы считаем dev-серверы отличным решением для небольших компаний на 20–30 разработчиков. Особенно при использовании микросервисной архитектуры.
Мы разворачиваем dev-серверы столько, сколько существует CarPrice, и прошли уже несколько этапов «серверной» эволюции. Рассказываем, как это было и чему стоит поучиться на нашем опыте.
Эпоха монолита: 2014 – 2016
Когда CarPrice стартовал, у нас все работало на монолите, основанном на базе Bitrix. Там было легко развернуть dev-окружение, и мы подумали — почему бы не сделать это централизованно? Все-таки организовать каждому VPS со своим окружением явно удобнее, чем локально поднимать Bitrix.
Так мы и поступили — и это был настоящий win-win: разработчики и тестировщики получали нужные инструменты, а системные администраторы — простое обслуживание. В качестве примера: если новому сотруднику требовался стенд для разработки или тестирования, достаточно было поднять из образа дополнительный виртуальный сервер.
Кроме того, в то время у нас еще были сотрудники на аутстафе, и тут виртуальные dev-серверы тоже оказались очень кстати. Мы обеспечивали ими всю команду — более 40 человек.

При этом нельзя сказать, что все работало идеально. Если образ, из которого разворачивали dev-сервер, устаревал, окружение требовало доработки — каждый разработчик самостоятельно обновлял и допиливал сервер под свои нужды. Но в целом, мы были довольны. Даже с учетом доработки все это занимало куда меньше времени, чем установка и настройка окружения на каждой машине с нуля.

Свой оркестратор докера: 2016 – 2018
Постепенно CarPrice развивался и масштабировался. Вместе с сервисом разрастался монолит — в 2016-м мы начали распиливать его с прицелом на микросервисную архитектуру. Но так как распил монолита дело дорогое и долгое, через какое-то время у нас были и монолит, и микросервисы, запускаемые в docker-контейнерах. Весь новый функционал также разрабатывался в виде отдельных сервисов. Пришло время модернизировать dev-серверы.
Основной задачей было предоставить разработчику или тестировщику возможность запускать на своем стенде необходимый набор микросервисов — формировать условия, максимально приближенные к проду. В этом, собственно, и заключается логика использования docker-контейнеров. Оставалось решить, каким образом управлять их запуском и конфигурацией — с учетом большого количества сервисов и пользователей. Для монолита при этом также было решено собрать отдельный docker-контейнер и запускать его вместе с остальными сервисами.
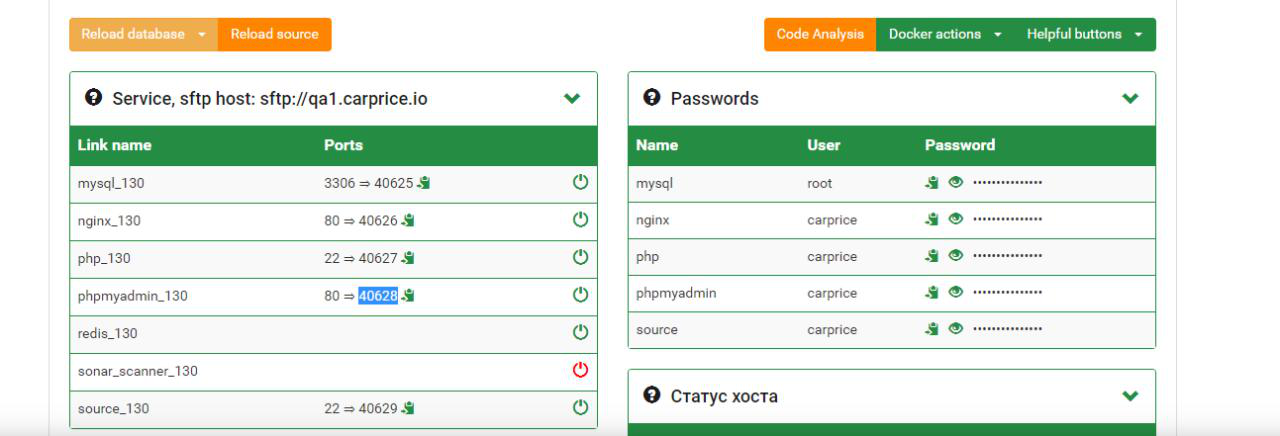
Мы оценили возможности существующих инструментов и решили написать собственный оркестратор для управления docker-сервисами на dev-серверах. У сервиса был уникальный UI, с помощью которого сотрудники могли управлять деплоем docker-сервисов на своих стендах. Для этого достаточно было выбрать в интерфейсе необходимые параметры. После этого приложение dev-сервера формировало и стартовало файлы конфигурации docker-compose. Но это в идеале — на практике контейнеры могли не стартовать, а упасть с ошибкой. В решении, к сожалению, было немало багов.

Чтобы поддерживать существующий функционал и добавлять что-то новое, требовались серьезные усилия. Иногда, например, ресурсов физического сервера становилось недостаточно, потому что количество микросервисов постоянно росло. Аккаунт нового пользователя в таком случае приходилось переносить на другой сервер — это был болезненный и трудозатратный процесс.
Еще мы сталкивались с проблемой свободных tcp/udp-портов.
Во-первых, так как на одном физическом сервере было запущено много docker-сервисов, требовались уникальные порты для каждого контейнера. Но иногда на один порт по ошибке запускали два docker-композа.
Во-вторых, иногда возникали ошибки, и docker-композы продолжали работать, когда разработчик останавливал сервис. Эти запущенные контейнеры занимали порты, которые система управления считала свободными, и никто ничего не мог туда задеплоить. У разработчиков и тестировщиков не было доступа к ssh-консоли хост-системы, поэтому DevOps-инженеру приходилось заходить на сервер и вручную тушить старые контейнеры.
В целом, разработчики были довольны — у них все это время сохранялась возможность работать на отдельных dev-серверах. Но вот у DevOps-инженеров значительно прибавилось работы. На протяжении двух лет, не без мучений, мы поддерживали решение с собственным оркестратором. Но затем признали, что эксперимент пора сворачивать и переходить к поиску более современного и стабильного решения.
Поиск новых решений с Kubernetes. Minikube: 2018 – 2022
В 2017 году стала все чаще звучать идея, что будущее микросервисной разработки за Kubernetes. Мы были согласны с этой точкой зрения и начали использовать Кубер еще до того, как это стало мейнстримом.
Чтобы упростить процесс развертывания dev-стендов, решили запускать Minikube — упрощенную реализацию полноценного Kubernetes-кластера. Мы запускали на виртуальных машинах один экземпляр для каждого разработчика. Была проведена большая работа: вместо набора docker-compose-файлов для каждого сервиса разработали helm-чарты, все это поместили в общий репозиторий и обернули несколькими bash-скриптами для упрощения деплоя.

Несколько лет решение неплохо работало, разработчики были довольны универсальным и относительно простым процессом запуска новых сервисов в Kubernetes. Бонусом можно было пользоваться Lens или Okteto. Однако при этом мы повысили порог входа для новых сотрудников. Помимо навыков разработки теперь требовалось базовое понимание, как работает Kubernetes, умение писать и разбираться в helm-чартах и работать в консоли.
Постепенно микросервисов становилось всё больше, а с ними росло количество подов и контейнеров, запущенных в рамках одного инстанса Minikube. Мы начали выходить за пределы рекомендованных лимитов в 110 подов на узел. Попытались увеличить значение параметра max-pods в настройках kubelet. Это помогло ненадолго — вскоре мы уперлись уже в движок контейнеризации. Начались проблемы в работе docker runtime. Kubelet тоже начал сильно тормозить, не успевая обрабатывать возросшее количество кронджоб.
Сталкивались и с ограничениями самого Minikube. Например, встроенный в Minikube nginx-ingress-контроллер не поддерживал grpc-протокол, тогда как версия ingress-контроллера для стандартного Kubernetes без проблем позволяла его использовать.
В конце концов мы осознали, что исчерпали возможности виртуальных машин с Minikube.
Kubernetes: 2022 – настоящее время
К 2022 году мы пришли к выводу, что нам пора переходить на полноценный Kubernetes. Сейчас у каждого разработчика есть свой Namespace, куда он деплоит микросервисы.

При переходе с Minikube на большой Kubernetes мы кое-что изменили в привычных процессах. Например, стали использовать BGP (Border Gateway Protocol) для маршрутизации между внутренней сетью Kubernetes и нашей основной сетью, а также организовали доступ из VPN-сети к DNS Кубера. В результате разработчик может напрямую, по имени сервиса, обратиться к любому своему контейнеру. Настраивать сервисы с типом NodePort, как это было в случае с dev-серверами на Minikube, больше не требуется.
Еще нам пришлось заняться тюнингом самого Kubernetes, так как мы вышли за рамки небольших развертываний, в которых все работает из коробки. Например, мы меняли модуль, отвечающий за обслуживание правил по пропуску трафика на нодах. Оказалось, что при нашем количестве сервисов (~3 000!) модуль iptables, который успешно работает в prod-кластере, просто не успевает обновлять правила в кластере dev. В результате мы перешли на рекомендованный при таких нагрузках модуль IPVS.
Другой момент, который стоит учитывать при развертывании — квоты и лимиты ресурсов для контейнеров. Без выставления реквестов и лимитов планировщик Kubernetes раскидывает поды по нодам буквально как попало, и это вызывает дисбаланс по нагрузкам.
Также в переходе на Кубер может скрываться еще одна проблема — кронджобы.
У нас в dev-окружении используется большое количество кронджоб — у каждого разработчика есть определенный пул, запущенный в неймспейсе. Если для планировщика не задать никаких правил, он будет массово запускать поды на ноде Kubernetes, у которой больше ресурсов. Поскольку многие кронджобы запускаются раз в минуту, то kubelet (демон Kubernetes, отвечающий за жизненный цикл пода) оказывается сильно перегружен. Разработчик что-то деплоит, его под попадает на ноду с толпой кронджоб, и из-за нагрузки на kubelet приходится по несколько минут ждать старта пода.
Проблему можно решить с помощью общей метки app-type: cronjob и инструкций topologySpreadConstraints.
Вот пример использования:
spec:
topologySpreadConstraints:
- maxSkew: {{ $.Values.main.cronjob_max_skew }}
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app-type: cronjobПосле такой доработки планировщик стремится равномерно распределять кронджобы по узлам Kubernetes. Допустимый перекос мы контролируем с помощью переменной cronjob_max_skew.
Без подстройки параметров sysctl на узлах Kubernetes также не обошлось. Как уже упоминалось, наши разработчики используют Okteto для разработки в Kubernetes. Okteto синхронизирует файлы между репозиторием на компьютере разработчика с подом. Количество файлов в некоторых проектах довольно велико, что влечет за собой исчерпание ресурса max_user_watches и max_user_instances на узлах Kubernetes.
Мы решили проблему увеличением максимумов на каждом узле Kubernetes:
fs.inotify.max_user_watches=100485760
fs.inotify.max_user_instances=1280Что дальше?
В будущем мы обязательно продолжим дорабатывать решение с dev-серверами. Планируем применить подход GitOps к развертыванию dev-микросервисов: использовать движок ArgoCD. Это позволит контролировать весь жизненный цикл манифестов, развернутых в Kubernetes. В целом, мы стремимся привести dev-окружение к уровню, максимально близкому к продуктовому.
Еще в планах сделать stage с автоматическим обновлением и автоматическим прогоном всевозможных UI end-to-end, integration, performance и penetration тестов. Но это, конечно, уже совсем другая история — расскажем ее чуть позже ;)
Если вы только готовитесь развернуть dev-сервисы, мы на связи и готовы ответить на любые вопросы. А с теми, кто уже делает dev-серверы своим разработчикам, всегда рады обменяться опытом.
chemtech
Спасибо за пост. Зачем потребовалось синхронизировать файлы между репозиторием на компьютере разработчика с подом?
miheych Автор
В этом заключается принцип и удобство применения Octeto - он синхронизирует файлы, чтобы можно было изменяя их локально (например, при разработке на php) сразу же видеть как это отражается на работе приложения запущенного в dev-кластере.
chemtech
Можно использовать skaffold. Он пересобирает контейнеры и обновляет их в kubernetes. Если локально - это очень быстро.