

/ фото Ozzy Delaney CC
Мы в 1cloud много рассказываем о собственном опыте работы над провайдером виртуальной инфраструктуры и тонкостях организации внутренних процессов. Сегодня мы решили немного поговорить об оптимизации БД.
Многие СУБД способны не только хранить и управлять данными, но и исполнять код на сервере. Примером этого служат хранимые процедуры и триггеры. Однако всего одна операция изменения данных может запустить несколько триггеров и хранимых процедур, которые, в свою очередь, «разбудят» еще парочку. В качестве примера можно привести каскадное удаление в базах данных SQL, когда исключение одной строки в таблице приводит к изменению многих других связанных записей.
Очевидно, что пользоваться расширенной функциональностью следует осторожно, чтобы не нагружать сервер, ибо все это может сказаться на производительности клиентских приложений, использующих данную БД.
Взгляните на график ниже. На нем изображены результаты выполнения нагрузочного тестирования приложения, когда число пользователей (синий график), работающих с БД, постепенно увеличивается до 50. Количество запросов (оранжевый), с которыми система может справиться, быстро достигает своего максимума и перестаёт расти, тогда как время ответа (желтый) постепенно увеличивается.
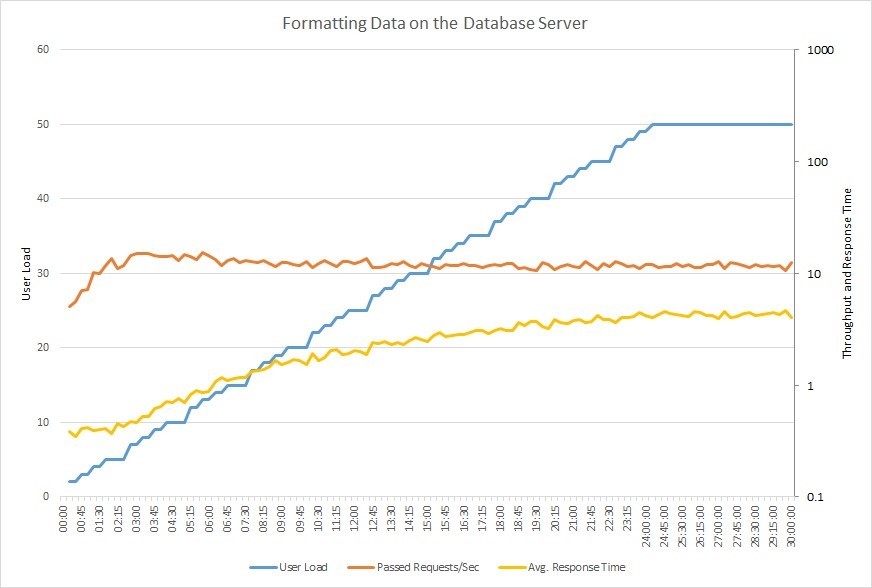
При работе с крупными базами данных даже малейшее изменение способно оказать серьезное влияние на производительность, причем как в положительную, так и отрицательную сторону. В организациях среднего и большого размера настройкой баз данных занимается администратор, но частенько эти задачи ложатся на плечи разработчиков. Поэтому далее мы дадим несколько практических советов, которые помогут повысить производительность баз данных SQL.
Используйте индексы
Индексация – это эффективный способ настройки базы данных, которым часто пренебрегают во время разработки. Индекс ускоряет запросы, предоставляя быстрый доступ к строкам данных в таблице, аналогично тому, как предметный указатель в книге помогает вам быстро найти желаемую информацию.
Например, если вы создадите индекс по первичному ключу, а затем будете искать строку с данными, используя значения первичного ключа, то SQL-сервер сначала найдет значение индекса, а затем использует его для быстрого нахождения строки с данными. Без индекса будет выполнено полное сканирование всех строк таблицы, а это трата ресурсов.
Однако стоит обратить внимание, что, если ваши таблицы «бомбардируются» методами INSERT, UPDATE и DELETE, к индексации нужно отнестись осторожно – она может привести к ухудшению производительности, так как после проведения указанных выше операций все индексы должны быть изменены.
Более того, когда нужно добавить в таблицу большое количество строк (например более миллиона) сразу, администраторы БД часто сбрасывают индексы для ускорения процесса вставки (после вставки индексы создаются заново). Индексация – это обширная и интересная тема, для ознакомления с которой недостаточно столь краткого описания. Больше информации по этой теме вы найдете здесь.
Не используйте циклы с большим количеством итераций
Представьте ситуацию, когда на вашу БД последовательно приходит 1000 запросов:
for (int i = 0; i < 1000; i++)
{
SqlCommand cmd = new SqlCommand("INSERT INTO TBL (A,B,C) VALUES...");
cmd.ExecuteNonQuery();
}
Такие циклы писать не рекомендуется. Пример выше можно переделать, используя один INSERT или UPDATE с несколькими параметрами:
INSERT INTO TableName (A,B,C) VALUES (1,2,3),(4,5,6),(7,8,9)
UPDATE TableName SET A = CASE B
WHEN 1 THEN 'NEW VALUE'
WHEN 2 THEN 'NEW VALUE 2'
WHEN 3 THEN 'NEW VALUE 3'
END
WHERE B in (1,2,3
)
Убедитесь, что операция WHERE не перезаписывает одинаковые значения. Такая простая оптимизация может ускорить выполнение SQL-запроса, уменьшив количество обновляемых строк с тысяч до сотен. Пример проверки:
UPDATE TableName
SET A = @VALUE
WHERE
B = 'YOUR CONDITION'
AND A <> @VALUE – VALIDATION
Избегайте коррелирующих подзапросов
Коррелирующим подзапросом называют такой подзапрос, который использует значения родительского запроса. Он выполняется построчно, один раз для каждой строки, возвращённой внешним (родительским) запросом, что снижает скорость работы БД. Вот простой пример коррелирующего подзапроса:
SELECT c.Name,
c.City,
(SELECT CompanyName FROM Company WHERE ID = c.CompanyID) AS CompanyName
FROM Customer c
Здесь проблема в том, что внутренний запрос (SELECT CompanyName…) выполняется для каждой строки, которую возвращает внешний запрос (SELECT c.Name…). Чтобы повысить производительность, можно переписать подзапрос через JOIN:
SELECT c.Name,
c.City,
co.CompanyName
FROM Customer c
LEFT JOIN Company co
ON c.CompanyID = co.CompanyID
Старайтесь не использовать SELECT *
Старайтесь не использовать SELECT *! Вместо этого стоит подключать каждый столбец по отдельности. Звучит просто, но на этом моменте спотыкаются многие разработчики. Представьте таблицу с сотнями столбцов и миллионами строк. Если вашему приложению нужно лишь несколько столбцов, нет смысла запрашивать всю таблицу – это большая трата ресурсов.
Например, что лучше: SELECT * FROM Employees или SELECT FirstName, City, Country FROM Employees?
Если вам действительно нужны все столбцы, укажите каждый в явном виде. Это поможет избежать ошибок и дополнительной настройки БД в будущем. Например, если вы используете INSERT… SELECT..., а в исходной таблице появился новый столбец, могут возникнуть ошибки, даже если этот столбец не нужен в конечной таблице:
INSERT INTO Employees SELECT * FROM OldEmployees
Msg 213, Level 16, State 1, Line 1
Insert Error: Column name or number of supplied values does not match table definition.
Во избежание таких ошибок, нужно прописывать каждый столбец:
INSERT INTO Employees (FirstName, City, Country)
SELECT Name, CityName, CountryName
FROM OldEmployees
Однако стоит заметить, что есть ситуации, в которых использование SELECT * допустимо. Примером могут служить временные таблицы.
Пользуйтесь временными таблицами с умом
Временные таблицы чаще всего усложняют структуру запроса. Поэтому их лучше не использовать, если есть возможность оформить простой запрос.
Но если вы пишете хранимую процедуру, выполняющую какие-то действия с данными, которые невозможно оформить в одном запросе, то используйте временные таблицы как «посредников», помогающих получить конечный результат.
Допустим, вам нужно сделать выборку с условиями из большой таблицы. Чтобы увеличить производительность БД, стоит перевести свои данные во временную таблицу и выполнить JOIN уже с ней. Временная таблица будет меньше исходной, поэтому объединение произойдёт быстрее.
Не всегда понятно, в чем разница между временными таблицами и подзапросами. Потому приведем пример: представьте таблицу покупателей с миллионами записей, из которой нужно сделать выборку по региону. Один из вариантов реализации – использовать SELECT INTO с последующим объединением во временную таблицу:
SELECT * INTO #Temp FROM Customer WHERE RegionID = 5
SELECT r.RegionName, t.Name FROM Region r JOIN #Temp t ON t.RegionID = r.RegionID
Но вместо временных таблиц можно использовать подзапрос:
SELECT r.RegionName, t.Name FROM Region r
JOIN (SELECT * FROM Customer WHERE RegionID = 5) AS t
ON t.RegionID = r.RegionID
В предыдущем пункте мы обсуждали, что стоит прописывать в подзапросе только нужные нам столбцы, поэтому:
SELECT r.RegionName, t.Name FROM Region r
JOIN (SELECT Name, RegionID FROM Customer WHERE RegionID = 5) AS t
ON t.RegionID = r.RegionID
Каждый из трех примеров вернет один и тот же результат, но в случае с временными таблицами вы получаете возможность использовать индексацию. Для более полного понимания принципов работы временных таблиц и подзапросов можете почитать тему на Stack Overflow.
Когда работа с временной таблицей закончена, лучше удалить её и освободить ресурсы tempdb, чем ждать, пока произойдет автоматическое удаление (когда ваше соединение с сервером БД закроется):
DROP TABLE #tempИспользуйте EXISTS()
Если необходимо проверить существование записи, лучше использовать оператор EXISTS() вместо COUNT(). Тогда как COUNT() проходит по всей таблице, EXISTS() прекращает работу после нахождения первого совпадения. Этот подход повышает производительность и улучшает читаемость кода:
IF (SELECT COUNT(1) FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') > 0
PRINT 'YES'
или
IF EXISTS(SELECT FIRSTNAME FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%')
PRINT 'YES'
Вместо заключения
Пользователи приложений любят, когда им не нужно подолгу смотреть на значок загрузки, когда все работает четко и быстро. Применение описанных в этом материале приемов позволит вам повысить производительность базы данных, что положительно скажется на пользовательском опыте.
Хотелось бы подвести небольшой итог и повторить ключевые моменты, описанные в статье:
- Используйте индексы, чтобы ускорить проведение поиска и сортировки.
- Не используйте циклы с большим количеством итераций для вставки данных – используйте INSERT или UPDATE.
- Обходите стороной коррелирующие подзапросы.
- Ограничивайте количество параметров оператора SELECT – указывайте только нужные таблицы.
- Используйте временные таблицы только как «посредников» для объединения крупных таблиц.
- Для проверки на наличие записи пользуйтесь оператором EXISTS(), который заканчивает работу после определения первого совпадения.
Если вам интересна тема производительности баз данных, то на Stack Exchange есть обсуждение, в котором собрано большое количество полезных ресурсов, – вам стоит обратить на него внимание. Еще можете почитать наш материал о том, как работают с данными крупные мировые компании.
Свежие материалы из нашего блога на Хабре:
Комментарии (34)

remzalp
04.07.2016 10:48А как же всё связанное EXPLAIN? Без этого получается однобоко — результат был бы более наглядно.
А что насчет хаков по принуждению тупого оптимизатора к использованию конкретных индексов?
Но спасибо, людей носом тыкать в одну ссылку гораздо удобнее, перечислены ключевые вещи.
maxru
04.07.2016 12:47+1А это где вы встретили тупой оптимизатор? :)
remzalp
04.07.2016 15:30в Mysql некоторых версий приходилось дополнительно уговаривать использовать специально созданные индексы просто потому, что это начинало работать быстрее.
http://dev.mysql.com/doc/refman/5.7/en/index-hints.html
http://dev.mysql.com/doc/refman/5.7/en/optimizer-hints.html
конструкции пока в движке еще есть, так что кому-то это нужно,
но я сейчас уже не работаю с тем проектом, где жить без этого было медленно, так что реальных примеров не смогу дать.
megaalli66
04.07.2016 16:25Иногда бывает удобно принудительно указывать на индекс в случае работы с большими таблицами и когда имеется несколько «частичных» индексов (partial index). Оптимизатор тут может долго гадать какой использовать или просто выбрать самый большой индекс, чтобы уж наверняка.
maxru
04.07.2016 17:41В email lists PostgreSQL была в своё время одна светлая мысль, которая звучала вкратце — «не считайте себя умнее планирощика запросов».
В 99,9% это работает. Возможно и с MySQL тоже.
Если немного расширить — «сначала разберитесь, почему планировщик выбрал именно этот индекс или не выбрал вообще никакой и, возможно, поймёте, почему вы были неправы».Wangsamp
05.07.2016 22:48+2Большая таблица(миллионы строк), в запросе множество условий(и под них попадает большая часть данных), приправленные LIKE и в конце ODER BY date DESC LIMIT 20.
Оптимизатор пытается подобрать индекс для отсеивания по части условий(меньшее из больших подмножеств), но потом при исполнении нужно проверять остальные и сортировать результат( в выбранном индексе date может присутствовать, но до него поле, где получился range)
Если же ему подсказать использовать индекс date — будет читать строки по нему и в 95% случаев получит желаемые 20 проверив меньше 100, хоть и нужно проверять все условия.
Да, причина в несоответствии структуры хранения «эволюционировавшим» условиям выборок, но работать должно сейчас, а отрефакторят быть может в следующей жизни.
VolCh
04.07.2016 11:06+1Со временными таблицами нужно быть осторожным. Во-первых, СУБД может сама решить создать временный индекс и(или) будет использовать знания о сортировке. Во-вторых, в какой-то момент СУБД может решить изменить in-memory таблицу на дисковую. В третьих, размер временной таблицы может неожиданно превысить размер раздела для временных файлов, а установление этого факта может оказаться не тривиальным.

gleb_l
04.07.2016 11:26+6Извините, конечно, но это рекомендации начального уровня.
Если в системе, напротив которой выполняется нагрузочное тестирование, они не были изначально выполнены — то это значит, что перед нами — однопользовательский проект студенческого уровня, а не бакенд системы массового обслуживания.

1cloud
04.07.2016 11:43+3Повсеместная проблема состоит в том, что все обычно забывают про базовые моменты :)
gleb_l
04.07.2016 12:04+1В таком случае, эти «все» — поголовно студенты. Хотя в этом вы правы — в процессе вертикальной разработки систем типичен холивар по поводу naming convention, coding style и иерархии классов, а на продумывание и проектирование хорошего бакенда времени почему-то не остается. Code first, и вперед!

acmnu
04.07.2016 12:35Чаще всего эти проблемы возникают именно у «опытных». При чем, что характерно, студенты просто ошибаются — ну не набил он ещё этих шишек, это простительно. А вот опытные разработчики часто не делают из принципа. Любимые мантры «эта таблица никогда не вырастет», «индекс увеличивает время апдейта» (играет в кепа, но расчитать статистику не способен) и «да зачем нужен индекс на родительской таблице под форейн кеем, я никогда этого не делаю» (детская ошибка с тяжкими последствиями в Оракл).
megaalli66
04.07.2016 16:37+4Еще часто слышно:
1) «Этим все должна заниматься ORM»
2) «Надо просто увеличить кэш»
3) «Надо просто нарастить мощности»
4) «Это недо-БД. Вот postgres|oracle|MSSQL|… с этим сама справится»
5) «Некогда этим заниматься»

miksoft
04.07.2016 12:31-11) Нужно пояснить, что речь идет про MySQL. Для других СУБД советы могут быть неверными.
2)
Убедитесь, что операция WHERE не перезаписывает одинаковые значения.
Это актуально только если это улучшает использование индексов (например, при использовании двух полей индекса вместо одного.) и тем самым уменьшает количество записей, читаемых из таблицы.
Но в случае с неравенством это редко бывает.
Если же улучшения использования индексов не происходит, то смысла в этой проверке нет, так как MySQL все равно ее производит самостоятельно и не перезаписывает неизменённые записи.ikovrigin
04.07.2016 16:00+1Тоже удивился когда прочел пост, звучит как общие рекомендации однако например совет 2 не верен для MS SQL, поскольку практически всегда кореллирующий подзапрос преобразуется к OUTER JOIN.
Насчет EXISTS разница с SELECT TOP 1 будет не большая, а сам пример выглядит как хороший вредный совет при использовании LIKE и индексов. Нужно стараться избегать LIKE начинающихся с %.
По факту из полезных советов только используйте индексы и объединяйте кучу мелких запросов в один, все остальное микрооптимизации которые врядли дадут буст производительности и являются скорее хорошим стилем.Ivan22
05.07.2016 17:10Не использовать коррелирующие подзапросы — самый полезный совет во всей статье. Они я вам скажу очень не всегда правильно раскладываются оптимизатором.
p.s. У меня есть три любимых пункта на тему «как максимально усложнить жизнь себе, оптимизатору и вселенной»
1. Используйте коррелированные подзапросы — много, да еще и желательно вложенные в друг друга.
2. Используйте инлайн функции, особенно хорошо когда они тоже сами вызывают функции.
3. Используйте триггера, тоже сами понимаете лучше вызывающие срабатывание других триггеров и т.д.ikovrigin
05.07.2016 18:22Коррелирующие подзапросы часть языка не использовать их только потому, что оптимизатор может ошибиться мне кажется глупым. Запрос как и любая программа должен хорошо читаться, если для выразительности подзапрос выглядит лучше объединения, я буду использовать подзапрос. Когда же мы говорим о производительности, запрос сам по себе не может быть хорошим или плохим, всегда плохая производительность результат неудачного плана, а тот в свою очередь результат множества факторов из которых такой простой рефакторинг как замена subquery на join очень редко являются первопричиной (буду говорить только об оптимизаторе MSSQL поскольку плотно работал только с ним). Возможно для других движков имеют место подобные проблемы, тогда и говорить о подобных советах следует в контексте конкретного движка В общем случае только план запроса может быть необходимым и достаточным условием для оптимизации запроса.
kretsu
04.07.2016 16:001. Осторожно с индексами. Они должны быть продуманы. Бывает ускоришь один селект, а десять упадут.
2. Bulk Insert'ы для загрузки таблицы. Если это еще и процесс например миграции, то желательно снести все индексы перед инсертами.
6. На счет count vs exists можно ограничить count по rownumber = 1. Так же exists может быть намного быстрее чем конструкция IN (), но может и не быть.
7. Писать такие запросы, которые кэшируются и не требуют парсинга каждый раз, когда выполняются. Как пример preparedstatement
В целом надо смотреть на планы.
megaalli66
04.07.2016 16:16Еще подготовленные запросы — очень полезная штука.
И про лимиты не стоит забывать.
А вообще, если требуется серьезно поднять производительность работы БД(без повышения производительности аппаратной части), лучшим будет изучить хотя бы поверхностно, как ведет себя конкретная БД в определенных случаях(в транзакции; при первичной записи; что и в каких случаях попадает в кэш БД; как работает журналирование;… прочее...). Чуточку в настройках покопаться. И разобраться, как все вышеперечисленное между собой связано.
Да и в общем особенности реализации конкретной БД.
Многие оптимизации сами придут в голову, при понимании работы конкретной БД.
//------------------------
Ну и на мой взгляд, под производительностью стоит подразумевать не только скорость обработки запросов, но и объем потребляемых ресурсов. Бывает и такое, что ваш не самый частый запрос стал обрабатываться чуток быстрее, но выбил из кэша много полезного и часто используемого.
ikovrigin
04.07.2016 16:49+1Оптимизатор может делать все это за вас, а вы пытаясь переписать код в пустуе потратите время. Оптимизатор зачастую отлично справится с COUNT и построит такой же план как и для EXISTS.
IF (SELECT count(*) FROM Users WHERE active = 1) > 0
|--Compute Scalar(DEFINE:([Expr1005]=CASE WHEN [Expr1006] THEN (1) ELSE (0) END))
|--Nested Loops(Left Semi Join, DEFINE:([Expr1006] = [PROBE VALUE]))
|--Constant Scan
|--Index Scan(OBJECT:([TestDB].[dbo].[Users].[IX_Users_Email]), WHERE:([TestDB].[dbo].[Users].[Active]=(1)))
IF EXISTS (SELECT 1 FROM Users WHERE active = 1)
|--Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [Expr1005] THEN (1) ELSE (0) END))
|--Nested Loops(Left Semi Join, DEFINE:([Expr1005] = [PROBE VALUE]))
|--Constant Scan
|--Index Scan(OBJECT:([TestDB].[dbo].[Users].[IX_Users_Email]), WHERE:([TestDB].[dbo].[Users].[Active]=(1)))
Свободно преобразует подзапрос к джойну:
select top 100 CourseRegistrationID, (SELECT Email FROM Users WHERE UserID = cr.UserID) FROM CourseRegistrations cr
|--Top(TOP EXPRESSION:((100)))
|--Compute Scalar(DEFINE:([Expr1007]=[TestDB].[dbo].[Users].[Email]))
|--Nested Loops(Left Outer Join, OUTER REFERENCES:([cr].[UserID], [Expr1008]) WITH UNORDERED PREFETCH)
|--Index Scan(OBJECT:([TestDB].[dbo].[CourseRegistrations].[IX_CourseRegistrations_UserID] AS [cr]), ORDERED FORWARD)
|--Clustered Index Seek(OBJECT:([TestDB].[dbo].[Users].[PK_Users]), SEEK:([TestDB].[dbo].[Users].[UserID]=[TestDB].[dbo].[CourseRegistrations].[UserID] as [cr].[UserID]) ORDERED FORWARD)
Оптимизировать не имея статистики и не глядя в планы исполнения изначально является глупой затеей. Соберите статистику, проанализируйте план запроса и только после этого начинайте оптимизацию.
Если условия слишком сильно зависят от параметров, а параметры могут влиять на логику, в таком случае иногда выгоднее иметь не preparedstatement, а динамически сформированный запрос.

BalinTomsk
04.07.2016 18:02--Пример выше можно переделать, используя один INSERT или UPDATE
И тут вы быстро упретесь в ограничение на размер запроса в 8 Кб.
Лучше всего пихать в xml и передавать как параметер, тогда и 2 Тб можно вставить одним запросом.
C#:
using (SqlCommand cmd = new SqlCommand()) { cmd.Connection = cnn; cmd.CommandType = CommandType.Text; cmd.CommandText = "INSERT INTO CoreAccount SELECT X.C.value('@name', 'nvarchar(255)') FROM (SELECT @data AS XML_DATA) DATA CROSS APPLY DATA.XML_DATA.nodes('//value') as X(C) "; cmd.Parameters.Add("@data", SqlDbType.Xml); cmd.Parameters[0].Value = userList; cmd.ExecuteNonQuery(); }miksoft
04.07.2016 18:10И тут вы быстро упретесь в ограничение на размер запроса в 8 Кб.
Это где такое ограничение?
По крайней мере, в самом MySQL такого ограничения нет.
Точнее, есть max_allowed_packet, но у него дефолтное значение 1 или 4 мегабайта (зависит от версии MySQL).BalinTomsk
04.07.2016 22:34Вы пишите о ограничениях сервера, а есть еше ограничения библиотек. ODBC, JDBC, ADO,…
Там бывает все печальнее.Ivan22
05.07.2016 17:132 тб так вставлять тоже не стоит. Bulk load наш выбор
BalinTomsk
05.07.2016 17:562 Тб это конечно гротеск, но из реального — пришлось недавно напистаь сервис, что в идеале должен раз в сутки вставлять список из миллиона аккаунтов. никаког bulk разумеется в той архитектуре не предвидится.
Пир средней длине имени 10 символов (тестирпвал twitter) это примерно 30М в конечном файле с UTF-8.
KReal
04.07.2016 21:09-1Пользуйтесь временными таблицами с умом
Не знаю как в MySQL, но в MS SQL вместо
create table #tempTable (id int) ... drop table #tempTable
лучше использовать table variable
declare @temp table(id int)
А если ещё использовать тип, то можно быть 100% уверенным в том, что таблица будет in memory.ikovrigin
05.07.2016 09:28+1На самом деле в MSSQL table variable и temp table хранятся в temp db и имеют очень мало отличий (речь не идет о использовании типов). Из главных отличий (в моей практике) это отсутствие статистики для table variable, в большенстве случае вы будете получать estimate в 1 запись, особенно это критично в сторед процедурах. Так же хочу заметить что записи в table variable не являются частью пользовательской транзакции. Наверное самый толковый пост по сравнению этих объектов (там же есть ссылка на Memory-Optimized Table Types) What's the difference between a temp table and table variable in SQL Server?

Uniqo
05.07.2016 10:33Очень много споров и обсуждений касательно COUNT(1) or COUNT(*)?
Я заметил, что вы используете COUNT(1).
Прокомментируйте пожалуйста, что же всё таки предпочтительнее/быстрее? * or 1 ?)ikovrigin
05.07.2016 13:18+1Это вкусовщина чистой воды, любое NOT NULL выражение равносильно COUNT(*).
andrewzhuk
Неплохо, в закладки. спасибо
1cloud
Спасибо, что читаете блог.
Кстати, в комментариях можно было бы обсудить предложения для следующих постов – какие туториалы могли бы быть интересны применительно к теме IaaS, например.
lol_wat
Я у вас раньше читал что-то про систему мониторинга нагрузки. Есть ли какие-то новые функции в ней? Можно было бы какие-то реальные кейсы привести, в которых она используется для обнаружения узких мест и быстрого масштабирования.
1cloud
Спасибо, подумаем на этот счет :)