
Судя по всему, эра GPU-вычислений наступила! У Intel всё плохо. Если вы не читали мой блог последние несколько лет достаточно регулярно, то поясню, что я [Алекс Св. Джон] стоял у истоков изначальной команды DirectX в Microsoft в далёком 1994 году, и создал Direct3D API вместе с другими первыми создателями DirectX (Крэйг Эйслер и Эрик Энгстром) и способствовал его распространению в индустрии видеоигр и у производителей графических чипов. По этой теме в моём блоге можно найти множество историй, но ту, что имеет непосредственное отношение к данному посту, я написал в 2013-м году.
История Nvidia
Думаю, что версия игр будущего от Nvidia правильная, и мне очень нравится жить в эпоху, когда я могу работать с такими потрясающими компьютерными мощностями. Мне кажется, будто я дожил до эпохи, в которой я могу прогуляться по мостику Энтерпрайза и поиграть с варп-двигателем. Причём буквально – варпами Nvidia называет минимальную единицу параллельных процессов, которую можно запустить на GPU.
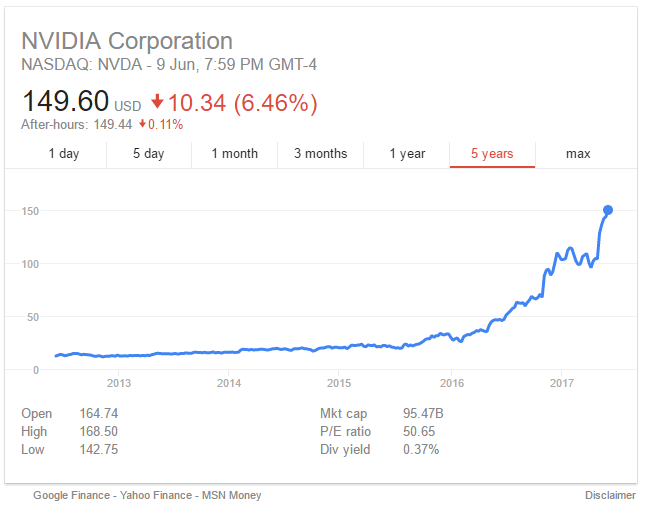
Те, кто следит за биржевыми котировками, могли заметить, что акции Nvidia недавно резко пошли вверх после многих лет медленного карабкания. Мне кажется, что этот внезапный рывок объявляет революционный сдвиг в компьютерных вычислениях, представляющий кульминацию многолетнего прогресса в разработке GPGPU. До сего дня Intel удерживала монополию над вычислениями на промышленном рынке, успешно отражая атаки конкурентов на их превосходство в промышленном вычислительном пространстве. Это доминирование закончилось в этом году, и рынок видит его приближение. Чтобы понять, что происходит и почему это происходит, я вернусь назад к моим ранним годам в Microsoft.
В 90-х Билл Гейтс придумал термин «кооперенция» [Cooperatition = конкуренция + кооперация] для описания вымученных конкурентных партнёрств с другими лидерами техноиндустрии того времени. В разговорах об Intel термин всплывал особенно часто. И пока судьбы и успех Microsoft и Intel переплетались всё туже, две компании постоянно воевали друг с другом за доминирование. В обеих компаниях были команды людей, «специализировавшихся» на попытках получения преимуществ над соперником. Пол Мариц, бывший в то время исполнительным директором Microsoft, очень переживал по поводу того, что Intel может попытаться виртуализировать Windows, позволив многим другим конкурирующим ОС выйти на рынок и существовать на настольном ПК параллельно с Windows. Интересно, что Пол Мариц позже стал генеральным директором VMWARE. И действительно, Intel активно вкладывалась в такие попытки. Одной из их стратегий была попытка эмуляции на уровне ПО всей общепринятой функциональности железа, с которой OEM-производители обычно поставляли ПК – видеокарты, модемы, звуковые карты, сетевое оборудование, и т.п. Перенеся все внешние вычисления в процессор Intel, компания могла бы уничтожить продажи и рост всех возможных альтернативных вычислительных платформ, которые иначе могут вырасти, неся угрозу CPU от Intel. Конкретно анонс компанией Intel технологии 3DR в 1994 году побудил Microsoft на создание DirectX.
Я работал на команду в Microsoft, отвечавшую за стратегическое позиционирование компании в свете конкурентных угроз на рынке, «группу по связям с разработчиками» [Developer Relations Group, DRG]. Intel потребовала, чтобы Microsoft отправила своего представителя выступить на презентации 3DR. Как эксперта по графике и 3D в Microsoft, меня отправили с особой миссией оценки угрозы, которую потенциально представляла новая инициатива от Intel, и формированию эффективной стратегии борьбы с ней. Я решил, что Intel действительно пытается виртуализировать Windows, эмулируя на уровне ПО все возможные устройства обработки данных. Я написал предложение под названием «серьёзно отнестись к развлечениям», где предложил для блокирования попыток Intel сделать ОС Windows незначительной создать конкурентный потребительский рынок для новых возможностей аппаратного обеспечения. Я хотел создать новый набор драйверов Windows, позволявших проводить массивную конкуренцию на рынке железа, чтобы работа новых медиа, включая аудио, ввод данных, видео, сетевые технологии, и т.п. на создаваемом нами рынке игр для ПК зависела от собственных драйверов Windows. Intel не справилась бы с конкуренцией на свободном рынке, созданной нами для компаний, производящих потребительское железо, и поэтому не смогла бы создать CPU, способный эффективно виртуализировать всю функциональность, которую могли потребовать пользователи. Так и родился DirectX.
В этом блоге можно найти множество историй о событиях, окружавших создание DirectX, но если вкратце, то наша «злобная стратегия» удалась. Microsoft поняла, что для доминирования на потребительском рынке и сдерживания Intel необходимо было сфокусироваться на видеоиграх, после чего появились десятки производителей 3D-чипов. Прошло двадцать с чем-то лет, и среди небольшого числа выживших Nvidia совместно с ATI, с тех пор приобретённой AMD, доминировали сначала на рынке потребительской графики, а в последнее время – и на рынке промышленных вычислений.
Это возвращает нас к текущему 2017-му году, когда GPU наконец начинает полностью вытеснять процессоры x86, к которым раньше все относились с благоговением. Почему сейчас и почему GPU? Секрет гегемонии x86 состоял в успехе Windows и обратной совместимости с инструкциями x86 вплоть до 1970-х. Intel могла поддерживать и увеличивать свою монополию на промышленном рынке из-за того, что стоимость переноса приложений на CPU с любым другим набором инструкций, не занимающий никакой рыночной ниши, был слишком велик. Феноменальный набор возможностей ОС Windows, привязанной к платформе x86, укреплял рыночную позицию Intel. Начало конца наступило, когда Microsoft и Intel совместно не смогли совершить скачок к доминированию на нарождавшемся рынке мобильных вычислений. В первый раз за несколько десятилетий на рынке x86 CPU появилась трещина, которую заполнили процессоры от ARM, после чего новые, альтернативные Windows ОС от Apple и Google смогли захватить новый рынок. Почему же Microsoft и Intel не смогли совершить этот скачок? Можно найти вагон интересных причин, но в рамках данной статьи я хотел бы подчеркнуть одну – багаж обратной совместимости x86. Впервые энергоэффективность стала более важной для успеха CPU, чем скорость. Все транзисторы и все миллионы строк кода для x86, вложенные Intel и Microsoft в ПК, превратились в препятствия на пути к энергетической эффективности. Самый важный аспект рыночной гегемонии Intel и Microsoft в один момент стал помехой.
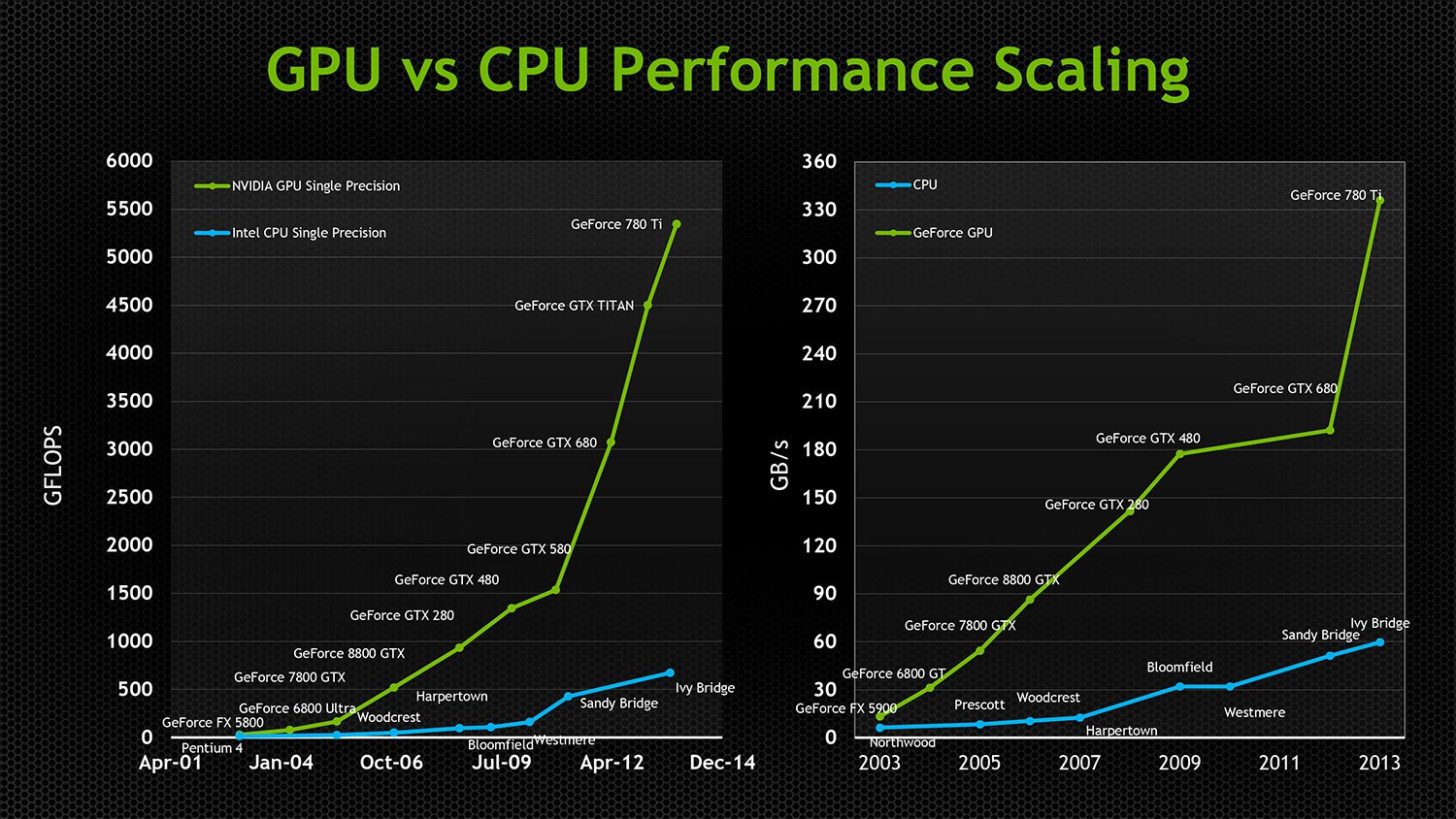
Потребность Intel в постоянном увеличении скорости работы и поддержке обратной совместимости заставляла компанию тратить всё больше и больше охочих до энергии транзисторов для получения постоянно уменьшающихся приростов в скорости в каждом новом поколении процессоров x86. Обратная совместимость также серьёзно затруднила возможность Intel делать распараллеливать свои чипы. Первый параллельный GPU появился в 90-х, а первый CPU с двойным ядром Intel выпустили лишь в 2005-м. Даже сегодня самый мощный CPU от Intel справляется только с 24 ядрами, хотя в большинстве современных видеокарт стоят процессоры с тысячами ядер. GPU, изначально бывшие параллельными, не тащили с собой багаж обратной совместимости, и благодаря независимым от архитектуры технологиям API вроде Direct3D и OpenGL были свободны в инновациях и увеличении параллельности без необходимости идти на компромиссы с совместимостью или транзисторной эффективностью. К 2005 году GPU даже стали вычислительными платформами общего назначения, поддерживающими разнородные параллельные вычисления общего назначения. Под разнородностью я имею в виду то, что чипы от AMD и NVIDIA могут исполнять одни и те же скомпилированные программы, несмотря на совершенно различные низкоуровневую архитектуру и набор инструкций. И в то время, когда чипы от Intel добивались всё уменьшающихся скачков производительности, GPU удваивали скорость работы каждые 12 месяцев, уменьшая при этом энергопотребление в два раза! Экстремальная параллелизация позволяла очень эффективно использовать транзисторы, обеспечивая каждому очередному добавленному к GPU транзистору возможность эффективного влияния на скорость работы, в то время как всё большее количество растущих в количестве транзисторов x86 не занималось делом.
И хотя GPU всё чаще вторгались на территорию промышленных суперкомпьютеров, производства медиа и VDI, основной поворот на рынке произошёл, когда Google стала эффективно использовать GPU для тренировки нейросетей, способных на весьма полезные вещи. Рынок понял, что ИИ станет будущим обработки больших данных и откроет огромные новые рынки автоматизации. GPU идеально подходили для обеспечения работы нейросетей. До этого момента Intel успешно полагалась на два подхода, подавлявших растущее влияние GPU на промышленные вычисления.
1. Intel оставляла скорость шины PCI на низком уровне и ограничивала количество путей ввода-вывода, поддерживаемое их процессором, тем самым гарантируя, что GPU всегда будут зависеть от процессоров Intel в обработке их нагрузки и останутся отделены от различных ценных приложений реального времени высокоскоростных вычислений из-за задержек и ограничений пропускной способности PCI. Пока их CPU был способен ограничивать доступ приложений к быстродействию GPU, Nvidia томилась на том конце PCI-шины без доступа к многим практически полезным промышленным нагрузкам.
2. Обеспечивала дешёвый GPU с минимальной функциональностью на потребительском процессоре, чтобы изолировать Nvidia и AMD от премиального игрового рынка и от всеобщего принятия рынком.
Растущая угроза со стороны Nvidia и неудавшиеся попытки самой Intel создать суперкомпьютерные ускорители, совместимые с x86, заставила Intel избрать иную тактику. Они приобрели Altera и хотят включать программируемые FPGA в следующее поколение процессоров от Intel. Это хитроумный способ сделать так, чтобы процессор от Intel поддерживал большие возможности I/O по сравнению с ограниченным шиной PCI железом от конкурентов, и чтобы GPU не получал никаких преимуществ. Поддержка FPGA давала Intel возможность идти в направлении поддержки параллельных вычислений на их чипах, не играя в ворота растущего рынка приложений, использующих GPU. Она также позволяла производителям промышленных компьютеров создавать железо высокой специализации, всё ещё зависящее от x86. Это был гениальный ход со стороны Intel, поскольку он исключал возможность проникновения GPU на промышленный рынок сразу по нескольким направлениям. Гениальный, но, скорее всего, обречённый на провал.
Пять последовательных новостей описывают причину, по которой я уверен, что вечеринка x86 закончится в 2017 году.
1. Фонд VisionFund от SoftBank получил инвестиций в размере $93 млрд от компаний, желающих встать на место Intel
2. SoftBank купил ARM Holdings за $32 млрд
3. SoftBank купил акций Nvidia на $4 млрд
4. Nvidia запускает Project Denver [кодовое название для микроархитектуры от Nvidia, реализующей набор инструкций ARMv8-A 64/32-bit, используя комбинацию простого аппаратного декодера и программного двоичного транслятора c динамической рекомпиляцией / прим. перев.]
5. NVIDIA анонсировала Xavier Tegra SOC с Volta GPU с 7 млрд транзисторов, 512 CUDA Cores и 8 ARM64 Custom Cores – мобильный чип ARM/Hybrid с ядрами ARM, ускоряемыми при помощи GPU.
Почему эта последовательность событий важна? Именно в этом году первое поколение самостоятельных GPU вышло на рынок в широкий доступ, и способно запускать свои собственные ОС без препятствий в виде PCI. Nvidia больше не нужен процессор x86. ARM обладает внушительным количеством потребительских и промышленных ОС и перенесённых на них приложений. Все промышленные и облачные рынки переходят на чипы от ARM в качестве контроллеров для большого спектра своих рыночных решений. В чипы ARM уже интегрированы FPGA. Чипы ARM потребляют мало энергии, уступая в производительности, но GPU чрезвычайно быстры и эффективны, так что GPU могут обеспечить процессорную мощность, а ядра ARM – обрабатывать нудные операции IO и UI, не требующие вычислительной мощности. Всё большему количеству приложений, работающих с большими данными, высокопроизводительными вычислениями, машинным обучением уже не нужна Windows, и они не работают на x86. 2017 – это год, когда Nvidia сорвётся с поводка и станет по-настоящему жизнеспособной конкурентной альтернативой промышленным вычислениям, основанным на x86, на ценных новых рынках, не приспособленных для решений на базе x86.
Если процессор ARM недостаточно мощный для ваших нужд, то IBM в сотрудничестве с Nvidia собирается производить новое поколение CPU Power9 для обработки больших данных, работающих со 160-ю линиями PCIe.
AMD также запускает новый Ryzen CPU, и, в отличие от Intel, у AMD нет стратегического интереса задушить быстродействие PCI. Их потребительские чипы поддерживают 64 линии PCIe 3.0, а профессиональные – 128. AMD также запускает новый HIP кросс-компилятор, благодаря которому приложения для CUDA становятся совместимыми с GPU от AMD. Несмотря на то, что эти две компании конкурируют между собой, обе они выиграют от смещения Intel на промышленном рынке с альтернативными подходами к GPU-вычислениям.
Всё это означает, что в ближайшие годы решения на базе GPU будет захватывать промышленные вычисления с возрастающей скоростью, а мир настольных интерфейсов всё больше будет полагаться на облачную визуализацию или работу на мобильных процессорах ARM, поскольку даже Microsoft анонсировала поддержку ARM.
Сложив всё вместе, я предсказываю, что через несколько лет мы будем слышать лишь про битву между GPU и FPGA за преимущество в промышленных вычислениях, в то время как эра CPU будет постепенно заканчиваться.
Комментарии (118)

RubyFOX
19.07.2017 11:20+3Рост цены акций обусловлен ростом цены на криптовалюты добываемые майнерами на видеокартах. На видеокартах именно потому, что так было задумано создателями тех или иных монет, в частности эфира.
denkle
19.07.2017 11:45+5Но рост акций зеленых начался раньше роста эфира. c 2016 года. Вот последний майский рывок это да, эфир. У амд схожая ситуация.

Timur_n
19.07.2017 14:17рост начался, когда начался усиленный спрос на видеокарты, т.е. начался «активный» майнинг, это произошло до резкого роста эфира, так что это исключение подтверждает правило)

ktod
19.07.2017 19:10Весной 2016 точно так же были сложности с покупкой видеокарт. Только тогда это не приняло такой размах и прошло незамеченно для широких масс.
JekaMas
19.07.2017 16:05+1Какие-то факты есть или это личные измышления?
Хотя бы есть цифры, что рынки сопоставимы и могут влиять друг на друга?
NIKOSV
20.07.2017 01:33-2У nvidia основной доход от датацентров, а не из консьюмерского сектора. Так что доля майнинга в росте не такая уж и большая.

FenixArt
20.07.2017 08:25+6Я понимаю что брякнуть можно что угодно, но мы же в интернете, таблица по доходности разных секторов гуглится в два счета, датацентры только 13%, а потребительский рынок 62%:

mypallmall
20.07.2017 11:13+1Более свежие результаты. Доля доходов от дата центров растет, от потребителей падает:


qw1
20.07.2017 12:40+1Это не «более свежие результаты». Это те же самые фактические данные + прогнозы на будущее время.

jetexe
20.07.2017 15:29+2«свежими» вы называете за первый квартал 18 года?

buriy
20.07.2017 23:31+1Ну, обычно, Q1 FY18 это 4 квартал 2017 года (October 1 2017 — December 31 2017)
( см. https://en.wikipedia.org/wiki/Fiscal_year и страну USA )
Но в случае NVidia — это февраль-апрель 2017 года.
http://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-first-quarter-fiscal-2018
http://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-fourth-quarter-and-fiscal-2017
Noa69
19.07.2017 11:22+8Сравнивает «ядра» видеокарты и x86 из количеству. Это или очень жирный троллинг или просто невероятная глупость.
clawham
19.07.2017 11:52-1Это вообще несравнимые вещи… гпу работают с примерными вычислениями где точность сильно уменьшена в угоду скорости. там даже есть спец генераторы белого цифрового шума чтоб одинаковые не точные вычисления в итоге давали случайные размытые границы на картинке… да это дает нереальный профит для криптовалют и нейросетей но и только. все остальное что требует гарантированной предсказуемости и точности — работать на видеокартах НЕ БУДЕТ! Покажите мне нормальный работающий перегонщик MP3 на видеокарте? качество перегона всех что я встречал перегонщиков на куде — полный отстой. и самое интересное что каждый прогон по сути уникальный… даже размер файла меняется на VBR! а у CPU Lame перегонщике размер файла не меняется от прогона к прогону.
Не все так просто как кажется. Да появилась ниша где CPU слабее ну и ладно. главное что остальные потребности так и остались востребоваными. Хотя вот что правда то правда — изза обратной совместимости приходится тащить на себе багаж межденных инструкций путающих кэш и потому считалка хоть точная и универсальная но медленная. Ну и роста производительности увы нет. Я люблю амд и их райзен мне кажется намного интереснее коре но тут кагбэ два разных подхода. ктото ударился в мощ одного потока а ктото — оптимизирован для многопотоковой производительности. универсального решения не будет. или так или этак. только если процы научатся свою структуру на лету перестраивать и это поняли в интел… вот только на транзисторах да на 6 нм вся логика выйдет намного более дешевле и менее энергоемкой чем на FPGA. хотя скорее всего они и не дойдут до полной эмуляции всего ядра — только отдельных программируемых функций в этой смой pgaNoa69
19.07.2017 12:01+1Спасибо что пасписали все подробно, а то самому лень было. И да, последний скачек акция на картинке, скорее с ростом криптовалют и ванакраем связан, чем со всем, во что автору статьи хотелось бы верить

avvor
19.07.2017 12:11+1Хотите сказать, что автор статьи Alex St. John стоял у истоков команды DirectX в Microsoft и создал Direct3D API и совершенно не разбирается в том о чем говорит?
denkle
19.07.2017 12:32Он стоял у истоков в 1994-1997 году. Потом работал в игровом бизнесе, где занимался средненькими игрушенциями. Так что он вполне может и не разбираться в теме.
Noa69
19.07.2017 13:17+5Даже самые заслуженные и умные люди иногда несут чушь. И наоборот.
Оценивать верность высказывания по титулам и регалиям автора этого высказывания не очень хорошая идея.
clawham
19.07.2017 15:47+1хочу сказать что человек увидел брешь в архитектору х86, которая не позволяет ему быстро отрабатывать милиарды флоат умножений без ветвления в огромном массиве 3-хмерных матриц. это идеальные условия для видеокарт и ещё более идеальные условия для FPGA где можно собрать ASIC ядро с просто космическими скоростями в пересчете на тактомую или ватт. но ничего сложного там делаться не сможет. — только одинаковые монотонные и простые операции. практически лишенные ветвления. только тогда видики и азики показывают ураганную скорость.
InChaos
19.07.2017 14:58+3гпу работают с примерными вычислениями где точность сильно уменьшена в угоду скорости… Покажите мне нормальный работающий перегонщик MP3 на видеокарте?
Не надо путать игровые видеокарты и профессиональные. Все вами сказанное справедливо для игровых карт, где нет двойной точности (даже чаще используется 16 бит вместо 32), для игр она и не нужна, у профессиональных решений все это присутствует (64 битная точность вычислений).clawham
19.07.2017 15:19-4можете прислать 2-3-4 мп3 файла сжатых проф гпу? или пару видиков пережатых этим самым гпу при одних и тех же настройках одной и той же программой. у меня на квадре получается один и тот же результат — файлы немного НО РАЗНЫЕ! а на CPU — одинаковые один-в-один.
Это ключевая особенность видеокарт 2х2 у них может быть и 3 и 5. главное что очень быстро и в статистическом распределении если на 10000 выборок посчитать среднее арифметическое то будет гауссово распределение шаром вокруг 4-ки :) да иногда и 4 получится :) Пытался писать под гпу… немного знаю что к чему… с целыми числами там все более менее хорошо. но по скорости конечно же это 24 и 32 битные флоаты и умножения/деления. и ещё они пипец как не людят срывов конвеера — любые ветвления условия и т.д. проще отрабатывать на CPU и в ГПУ выгружать уже поток, который обрабатывается без ветвлений — можно создать по два потока на каждое ответвление и даже если использовать их попеременно — скорость будет выше чем загрузить их впаралель но с ветвленным кодом. звучит жутко и странно но это так.InChaos
19.07.2017 15:36А уверены, что программа использует честные вычиления? На инженерных калькуляторах испокон веков 2*2 давало 3,999999999999. Давно не работал с точными числами, но буквально несколько лет назад писал программку, и получалось что перемножение целочисленных, но приведенных к double чисел, давало формат ХХ,9999999999999999. Это все от софта зависит. А по вашему значит и CPU не умеет считать точно. Весь вопрос в точности и правильного приведения погрешности вычисления к нужной разрядности.
InChaos
19.07.2017 15:49В довесок. Посмотрите исходники CUETools с поддержкой GPU. Там рип и конвертация и mp3 и FLAC и море еще чего (https://sourceforge.net/p/cuetoolsnet/code/ci/default/tree/), не нашел ни одной переменной с двойной и даже с одинарной точностью, или int или int64, что согласитесь совсем не то. Вот такой вот софт конвертации.

HomoLuden
19.07.2017 17:04+1Есть разница между систематической и случайной ошибкой. Перевод целого числа в число с плавающей точкой всегда сопряжено с систематической девиацией, т.к. битовое представление этих типов данных отличается. Однако одни и те же входные параметры операций всегда будут давать детерминированный результат.
Если я правильно понял комментаторов выше, то на GPU вычисления порождают случайные девиации, которые недетерминированы.cepera_ang
19.07.2017 19:19+2Нет конечно. Полный бред написан, может там баги в тех перекодировщиках просто. Тем более, майнинг — это вообще целочисленные вычисления, а нейросети хоть и не требуют самой высокой точности, но всё же считаются в float32, как и на процессорах и вычисления совершенно детерминированные, это же не вероятностные чипы какие-то.

MrShoor
19.07.2017 22:16+32*2 будет 4. На любой видеокарте. Даже не 3.9999999, и даже не 4.000000001. Все потому, что 2 можно представить в float без погрешностей, и 4 тоже можно представить в float без погрешностей.
Все вычисления видеокарт детерминированы. На этом принципе даже техника рендеригна есть, depth prepass называется.

beeruser
20.07.2017 08:56+1>> Это ключевая особенность видеокарт 2х2 у них может быть и 3 и 5.
FPU на современных видеокартах соответсвует стандарту IEEE-754-2008, так же как и х86.
У Nv есть статья с обсуждением этого вопроса
http://docs.nvidia.com/cuda/floating-point/index.html
dimaleks
25.07.2017 21:02+1Я довольно давно профессионально работаю на CUDA, и вы не совсем правы.
2х2 на видеокарте всегда будет одним и тем же числом. Все операции (кроме специальной быстрой математики, которую еще нужно включить) IEEE-compliant. Недетерменированность может возникать разве что от использования атомарных операций с плавающей запятой, их порядок неопределен. Это может повлиять на результат, но обычно разница в последних нескольких значащих разрядах. А если использовать хороший устойчивый алгоритм, то разница между запусками и вовсе будет минимальная.
Я никогда не смотрел ни на код, ни на работу кодеков, по этому поводу ничего не могу сказать. Возможно, вы нашли какой-то баг. Возможно, алгоритму нужна высокая точноть, и single precision и 32 бита — это просто недостаточно. Тогда, как заметил InChaos, нужно переходить на карты Tesla и double precision

PsyHaSTe
27.07.2017 01:06Не надо путать игровые видеокарты и профессиональные. Все вами сказанное справедливо для игровых карт, где нет двойной точности (даже чаще используется 16 бит вместо 32), для игр она и не нужна
Скажите это EA
qw1
19.07.2017 17:54+1Это вообще несравнимые вещи… гпу работают с примерными вычислениями где точность сильно уменьшена в угоду скорости
У GPU есть векторные инструкции, работающие с целочисленными данными разной длины, работающие абсолютно точно. Без этого нельзя было бы считать хеши, например.clawham
19.07.2017 18:02есть конечно — попробуйте ними посчитать чтото и вы увидите что скорость — не их конек. да и целочисленные вычисления неплохо даются и cpu
qw1
19.07.2017 18:10+2попробуйте ними посчитать чтото и вы увидите что скорость — не их конек
Я не вижу причин, почему целочисленные вычисления будут медленнее.
У меня есть опыт с векторными вычислениями на SSE. Cравнивая векторные целочисленные операции и с плавающей точкой, замечу, что скорость одинаковая (а почему бы и нет — сложить вектор из 4 double, или из 4 int64 — второе даже проще в реализации).
Практически же, майнинг etherium — это целочисленное сложение, XOR, ADD, выборки из памяти по рандомным адресам.
AMD R9 390X даёт 32 мегахеша, 4-ядерный Intel Xeon 88 килохеша. Вот такой «не их конёк».
да и целочисленные вычисления неплохо даются и cpu
В одном потоке — да. Но ядер мало.clawham
19.07.2017 18:30Ну собственно с памятью у меня и была проблема… не изучал код эфира но по биткоину насколько слышал — там достаточно тяжелый расчет. В любом случае конечно же тысяча ядер гпу каждый пусть в 10 раз слабее одного ядра cpu в итоге всеравно быстрее.
qw1
19.07.2017 20:01+2Ну собственно с памятью у меня и была проблема
На CPU проблема? По эфиру на любом CPU — менее 1 мегахеша, на GPU — десятки мегахешей.
В любом случае конечно же тысяча ядер гпу каждый пусть в 10 раз слабее одного ядра cpu в итоге всеравно быстрее
Зачем строить предположения, если есть таблицы мощностей.
Справочник по железу bitcoin: https://en.bitcoin.it/wiki/Non-specialized_hardware_comparison
В списке всё довольно старое, т.к. bitcoin сейчас майнят только на спец-девайсах, но всё же:
NVidia GTX570: 160 Мегахешей/сек
Intel Core i7 2600K (специально подобрал ровесника по дате выпуска): 18,6 Мегахешей/сек
У современных GPU отрыв больше, т.к. архитектура развивается быстрее, перенимая решения из мира CPU
ktod
19.07.2017 19:23+4Странные вещи Вы пишете. Последний проект, который я делал на куде, было размытие по гауссу изображений в реальном времени с помощью фильтра с БИХ. Было последовательно реализовано 4 версии кода: многопоточный ЦПУ, многопоточный AVX, на шейдерах OGL и на куде. Для проверки корректности работы проводилось сравнение между результатами этих реализаций. И совершенно точно, что результаты работы 1, 2 и 4 совпадали до бита.
clawham
19.07.2017 19:30на куде делали целочисленно или во флоатах?
а как по скорости AVX?ktod
19.07.2017 20:38+1Насколько я помню:
На ГПУ. Исходная картинка u8 RGB, нормализация [0,1) FP32, вычисления, обратная нормализация в u8 RGB.
На AVX нормализация во float (одинарная точность) и обратно.
По скорости AVX работал отлично! Практически 8 раз быстрее кода на «голом» ЦПУ. Код основного цикла на асм.
MrShoor
19.07.2017 22:09+5Все как-то мимо.
гпу работают с примерными вычислениями где точность сильно уменьшена в угоду скорости.
GPU сейчас работают в основном с float который 32 битный. Точность в них никак не уменьшена, это вполне себе IEEE 754 single-precision floating point. Раньше не было сильной потребности в другой точности, поэтому GPU и развивался в этом направлении. Будет потребность в большей точности — будет развитие в этом направлении.
там даже есть спец генераторы белого цифрового шума чтоб одинаковые не точные вычисления в итоге давали случайные размытые границы на картинке
Тут вообще непонятно что вы имели ввиду. Где там то, какие границы? Если вы возьмете тут спец генератор, и просто исполните его на CPU — то картинка внезапно не станет четкой. Нет в GPU неточностей, там все детерменировано, и на одном и том же GPU a+b всегда дадут один и тот же результат, а не какой-то примерный.
все остальное что требует гарантированной предсказуемости и точности — работать на видеокартах НЕ БУДЕТ!
Вообще глупость. Видеокарта — такой же детерменированный процессор, просто с другими возможностями и с другими ограничениями. Считает видеокарта точно так же точно, как и обычный процессор считает float 32.
Покажите мне нормальный работающий перегонщик MP3 на видеокарте? качество перегона всех что я встречал перегонщиков на куде — полный отстой
А это уже извините проблема алгоритма, а не GPU. Традиционно у GPU частота значительно ниже чем у CPU (1ГГц против почти 4ГГц). Поэтому поток на CPU может позволить себе потратить значительно больше времени на более качественное сжатие.
и самое интересное что каждый прогон по сути уникальный… даже размер файла меняется на VBR!
Перенесите GPU алгоритм на CPU, запустите в несколько потоков — и получите ровно такой же плавающий результат. Ровно такого же говнистого качества.
а у CPU Lame перегонщике размер файла не меняется от прогона к прогону.
Но это только благодаря алгоритму, который использует Lame. Вы можете 1 в 1 переложить этот алгоритм на GPU, и получите точно такой же качественный и не плавающий результат, но GPU будет просто в разы медленнее на этом алгоритме. Алгоритмы сжатия вообще очень плохо распараллеливаются.
Короче проблема GPU сейчас — только алгоритмы, которые тяжело распарллелить. Увы, таких алгоритмов сегодня очень много, что затрудняет использовать на полную катушку GPU, но ситуация постепенно меняется.
0serg
20.07.2017 00:45+4Предсказуемость и точность у GPU те же что у обычных процессоров. И они точно так же подвержены проблемам из-за дефектных модулей или перегрева, хотя встречаются эти проблемы там несколько чаще так как мощности там выше, места для охлаждения меньше, а у производителей меньше стимулов к обеспечению надежности. Ну и fp64 на GPU далеко не всегда реализуют (тогда как для x86 это обязательный компонент) из-за чего нередко алгоритмы для GPU пытаются переносить на fp32 что ухудшает их точность (но не повторяемость).
С повторяемостью результатов есть интересная проблема в многопоточном программировании. Довольно часто встречается ситуация когда быстрый параллельный алгоритм не детерминирован (точнее зависит от производительности отдельных потоков, которая по меняется от фаз луны и чихания пользователя). Например часто встречается «поиск достаточно хорошего решения» когда мы ищем что-то допускающее несколько ответов из которых нам подходит любой: если мы ищем «в параллель» и «до первого подходящего результата», то какой из результатов найдется первым заранее предсказать нельзя. Еще интереснее проблема в потоковой обработке данных где один «быстрый» блок осуществляет преобразование данных по набору правил а другой, значительно более «медленный» блок анализирует его работу и динамически подстраивает набор правил под входные данные. Период обратной связи здесь не детерминирован, выходной поток в результате тоже. Причем для CPU подобные вещи даже актуальнее, на GPU обычно алгоритмы «потупее» устроены.
Так что все очень часто зависит от алгоритма и того что именно пытались оптимизировали его создатели — воспроизводимость и качество или скорость. А GPU или CPU здесь глубоко вторично, GPU хорошего качества ничем не уступает CPU по точности и воспроизводимости результатов.

romovs
25.07.2017 21:03+1Это вообще несравнимые вещи… гпу работают с примерными вычислениями где точность сильно уменьшена в угоду скорости. там даже есть спец генераторы белого цифрового шума чтоб одинаковые не точные вычисления в итоге давали случайные размытые границы на картинке… да это дает нереальный профит для криптовалют и нейросетей но и только. все остальное что требует гарантированной предсказуемости и точности — работать на видеокартах НЕ БУДЕТ!
Прям таки совсем не будет? GPU кластеры используемые для научных исследований могут не согласится. :)
Это правда только в отношении трансцендентных функций и 16/32-бит (и то последнее даже не во всех случаях) и очень сильно зависит от драйверов и конфигурации компилятора.
А МП3 энкодеры вообще трудно распараллеливать. Там разве что только мультипоточное кодирование разных файлов имеет смысл.
elcondor
25.07.2017 21:05Подозреваю что все вычисления чисел с плавающей точкой примерные. Не зря есть понятие требуемой точности вычислений, и соответствующих длин переменных для этого — половинная точность, одинарная точность, или расширенная точность. Если вычисления не происходят над дробями — они примерные. Это как вычислить точно 2/3, верно будет и 0.66667, и 0.666666667, и 0.6666666666667.
tarasale
19.07.2017 16:05-1Ну почему же? Скорость одиночного ядра скоро упрётся в квантовые эффекты, а распараллелить однопоточное приложение на два и более ядер зачастую сложнее распараллеливания двухпоточного приложения на 20, 200 или 2000 ядер. И тут роигрывающие в скорости одного ядра, но при том на порядки превосходящие в их количестве окажутся в выигрыше.
0serg
20.07.2017 00:17+1Это не так. На GPU хорошо ложится только определенный класс задач, т.н. embarrassingly parallel computing, да и тот требует определенных трюков и хаков для того чтобы все нигде не затыкалось из-за ограничений железа что приводит к тому что сильно затруднена разработка кода который будет одинаково хорошо работать на разных GPU, а код для GPU писать сложнее и дольше чем для CPU. GPGPU — классная штука, но довольно нишевая

beavis88
19.07.2017 12:30+4Nvidia с геймеров переключается на оборудование для AI, отсюда и рост акций, а вовсе не от того что автор пишет.

minusnaminus
19.07.2017 16:06Увидели рядом с названием «NVidia» слово «автопилот», и понеслась. Рост котировок не есть зеркало действительности, и уж тем более не хрустальный шар, показывающий будущее…
willyd
25.07.2017 21:02Там рядом еще Toyota было написано. Так что смысл шумихи понятен. Теперь каждый эксперт, который стоял у каких-либо истоков, будет предлагать свою версию прошлого и будущего.
Я вот только не могу понять одного. Автор так хорошо разбирается в теме и уверен в крахе CPU перед GPU. Он сам деньги вложил в NVDA? Можно было 900% за 2 года поднять.
Sixshaman
19.07.2017 12:34+4Очередное сравнение слона с китом.
От сравнения акций NVIDIA и Intel автор перешёл к доминированию GPU над x86 в узком спектре задач. При этом совершенно не учёл, что x86 годами наращивал оптимизацию последовательных вычислений. Кэш, branch prediction — всего этого на GPU либо нет, либо реализовано со значительно меньшей эффективностью.
О чём статья, кстати? О росте акций NVIDIA? О том, что x86 в очередной раз похоронен? О том, что нейронные сети эффективнее тренируются на GPU?
edd_k
19.07.2017 14:02-1Статья об "Intel капут!". На сколько понимаю, у них там модно для раскрутки бложика включать идиота и массу адекватных выводов/фактов объединять под идиотским "желтым" заявлением.
Типа, все равно завтра уже никто не вспомнит. Но сегодня блог пропиарится. Вот, даже до нас дошел… А зачем такое на GT — не понятно =)
JerleShannara
19.07.2017 18:46Мне эта статья из памяти две строчки выудила — «Убийца айфона» и «вендекапец». Результат будет такой-же.
CreFroD
19.07.2017 13:39-1А не эффективней ли майники на FPGA? Ведь видеокарта — это всего лишь много маломощных процессоров, а на FPGA достаточного размера можно обработать что угодно за 1 такт.

Mogwaika
19.07.2017 13:45Что угодно за 1 такт, за ваши деньги, а видяхи дешевле и примерно с похожим софтом для разных платформ.
nerudo
19.07.2017 14:29+1Можно. И будет этот такт продолжаться 10 минут…
CreFroD
19.07.2017 15:11-1Современные FPGA работают на частотах порядка сотен МГц.
nerudo
19.07.2017 15:12+1Это был как бы намек, что не каждый алгоритм можно распараллелить даже за счет экстенсивного увеличения аппаратных затрат.
Mogwaika
19.07.2017 15:23+1А современные процессоры на гигагерцах…
Только вот чтобы получить сотни мегагерц на плис нужно реализовывать конвейеризируемый алгоритм. Майнинг в конвейер хорошо ложится?CreFroD
19.07.2017 15:28Но ведь видеокарты не работают на таких же частотах как процессоры! Про то как ложиться майнинг в конвейер не знаю, я просто хочу сказать, что на видеокарте за такт можно выполнить только одну простую операцию, на множестве процессоров, а на ПЛИС за такт можно выполнить множество сложных операций (конвейеров).
Mogwaika
19.07.2017 15:40На плис разные операции выполняются разное время и цепочка итераций уложенная в один такт требует меньшую тактовую частоту, чем конвейер из элементарных операций на такт.
Процессор cpu или gpu имеет уже оптимизированные блоки конвейеров или сложных операций, уложенных компактно рядом и выполняющихся за меньшее время, например за тот же такт высокой частоты в несколько гигагерц за счёт известной структуры вычислений, а не универсальной как у плис.
Т.е. быстрее всего оптимизированный под операцию asic. Но везде нужно оценивать стоимость, а не только возможности.CreFroD
19.07.2017 16:37Я знаю, что существуют специальные
CreFroD
19.07.2017 16:39Извините, случайно нажал. Я знаю, что существуют специальные ASIC для нейросетей, они эффективней чем видеокарты (например, по энергопотреблению)?
Mogwaika
19.07.2017 21:45+1Специализированная микросхема всегда эффективнее, чем универсальная, это очевидно же.
Вопрос в окупаемости партии.CreFroD
19.07.2017 23:40Вопрос в окупаемости партии.
Ведь сейчас ML везде, на смартфонах, на серверах, на ПК, на роботах, на дронах. Неужели специализированная IC, которая, к тому же будет иметь меньшее энергопотребление не окупится?Mogwaika
20.07.2017 00:08+1Я возможно отстал от жизни, но не видел ML на смартфонах (и возможно этот термин не есть нейросети). Я считал, что это делается на мощных серверах, которые потом обрабатывают короткие данные и не обязательно на них учатся, т.к. не знают верного ответа.
Вполне реально сделать, микросхему под определённый алгоритм обучения, но эти алгоритмы слишком быстро развиваются, посмотрите на те же конкурсы по распознаванию лиц. Плюс обучение как я понимаю задача не риалтаймовая и служит для вычисления неких коэффициентов, которые потом быстро используются.
Выпускают специализированные чипы для новых вайфаев, для новых видеокодеков и т.д… Какие нейросети или функции вы предлагаете я не очень понял.cepera_ang
24.07.2017 17:22-1Куча ML на смартфонах, в основном инференс (т.е. применение обученных моделей), это и Окей, гугл / Сири, и распознавание лиц на фотках и призма та же самая, и гугл-переводчик
CreFroD
19.07.2017 15:33Таким образом можно получить “последовательные” (в конвейере) и параллельные вычисления за один такт. Правда, наверняка невозможно бесконечно увеличивать длину конвейера, из-за конечной скорости переключения транзисторов.
0serg
20.07.2017 00:09+1Конвейер и «куча всего в 1 такт» — это совершенно разные вещи.
Длину конвейера как раз можно наращивать бесконечно, именно благодаря тому что скорость переключения транзисторов ограничивает только отдельную стадию конвейера а не цепочку в целом.
0serg
20.07.2017 00:07+1Частота на которой будет работать FPGA зависит от сложности схемы которую туда закинули
Попытка запихнуть достаточно сложные вычисления в 1 такт гарантирует что никаких сотен мегагерц там уже не будет.
qw1
19.07.2017 18:02-1А не эффективней ли майники на FPGA?
Эффективнее, если нужно только считать хеш. Тогда 100500 медленных (по сравнению с CPU) ядер FPGA в сумме будут быстрее.
Но новые криптовалюты используют такие хеши, для расчёта которых нужно 1-2 ГБ быстрой памяти.
Каждому вычислительному ядру, реализованному в FPGA, просто невозможно дать столько памяти в монопольное владение. А если память расшаривать, возникнет узкое место с конкурентным доступом.
Поэтому разница между FPGA-схемой и GPU — в пользу GPU, с учётом более тонкого техпроцесса GPU и оптимизированных шин к памяти.JerleShannara
19.07.2017 18:52А для того, чтобы FPGA+OpenCL было шустрее чем GPU+OpenCL\CUDA надо оптимизировать алгоритм. Например какие-то блоки, к которым идёт постоянный доступ, можно выкинуть в кеш/локальную память, или закинуть в QDR.
qw1
19.07.2017 20:12+1Там, где создатели сознательно заложили зависимость от RAM, ничего не оптимизируешь.
Например, хеш в майнинге etherium — 200 итераций
XN+1 = XN xor RAM [ XN mod RAMSIZE ]
где RAM — таблица псевдослучайных данных (заполнена хешами), размером более гигабайта, размер каждого Xi — 256 бит.JerleShannara
21.07.2017 01:13-1Тут да, с ходу не скажу. Хотя если RAM статичная, то можно раскидать её кусками по кернелам считающим какой-то конкретный диапазон. Ну или разбить её на два контроллера памяти (оверкил по тупому использованию памяти конечно, но я так на ускоритель вполне спокойно засуну и 32 гигабайта DDR4). Или опять варианты вида «считаем блоками, кусок хешей перегружаем в QDR и мучаем там, далее выгружаем обратно в DDR/отдаём хосту»
qw1
21.07.2017 17:24+1Вроде не получается раскидывать кусками. Каждому кернелу нужен массив всего объёма.
А увеличение количества контроллеров не масштабируется.
Ну, можно сделать 16 контроллеров и у каждого своя DDR небольшого объёма.
Но схема коммутации, к какому контроллеру идти за какими данными, будет огромной (у каждого контроллера — своя шина адреса и данных, т.е. нужно 16 шин к каждому ядру).
А масштаб x16 — это мало для ASIC-ов, тут хотя бы 4096 сделать.
JerleShannara
19.07.2017 18:49+1Можно и на FPGA, берём OpenCL и переписываем майнер на него. Современные ускорители на FPGA вполне себе имеют 16Gb DDR3/4, а если вам нужна огромная скорость/минимальные задержки, то можно и с QDR4 купить (но тут ценник уже взлетит совсем).
Axedem
19.07.2017 16:05Ну назвали бы «Эпоха GPU» или вроде того, а то уж очень попахивает рекламой Nvidia.

kengur8
19.07.2017 16:05+1Был у меня телефон на тегре, грелся как сволочь и тормозил. На сколько знаю Денвер дальше прототипа не выйдет, из-за патентных споров.
Нвидиа это такой же Интел — доить покупателей в премиум сегменте это их стратегия. Обновлять технологии и архитектуру только в крайнем случае.

SlTr
19.07.2017 16:06+1У автора статьи ни разу в тексте не употребляется аббревиатура PCI, только PCIe. Грубо говоря общего у шины PCI и у «шины» PCI Express только слово PCI.
nerudo
19.07.2017 16:21+1PCIe является преемницей PCI, вплоть до программной совместимости (с нюансами, конечно же), пусть и поверх другого физического интерфейса.
SlTr
20.07.2017 10:36+1Так все что вы перечислили это и есть:
общего у шины PCI и у «шины» PCI Express только слово PCI
потому что PCI Express технологически не является развитием шины PCI.nerudo
20.07.2017 10:45+1Что значит «технологически»? Физический уровень другой, все остальное обратно совместимо. Так что общего у них сильно больше чем три буквы в названии.
SlTr
20.07.2017 16:40-1Что значит «технологически»?
Наверно стоило написать технологическим развитием шины PCI, но имелось ввиду то что PCI Express это:
1.Не усовершенствованная шина PCI
2 А ПО СУТИ ДРУГАЯ ШИНА.
А написал я все это потому, что покоробило:
1. Intel оставляла скорость шины PCI на низком уровне и ограничивала количество путей ввода-вывода, поддерживаемое их процессором, тем самым гарантируя, что GPU всегда будут зависеть от процессоров
Еще раз повторю, у автора статьи везде используется слово «PCIe».SlTr
21.07.2017 10:31-1За что минус к карме я так и не понял. Для тех кто не согласен пусть элементарно загуглит матчасть начиная с википедии: что из себя представляет шина PCI и PCI Express. А совместимость программных интерфейсов оставлена для обратной совместимости программных интерфейсов, и все. Мог быть и другой программный интерфейс и слова PCI в названии могло и не быть вообще (есть и другое название). Еще раз: PCI Express не была развитием PCI.
И да:
1. Intel оставляла скорость шины PCI на низком уровне и ограничивала количество путей ввода-вывода, поддерживаемое их процессором, тем самым гарантируя, что GPU всегда будут зависеть от процессоров
Неплохой экскурс в историю, я не помню, честно, может такое и было, кстати может поэтому agp и появился…
Но я морально готов к следующим минусам! Правду не задушишь лол ахахах!JerleShannara
21.07.2017 16:09AGP появился из-за i740 =) Intel придумали такую вещь как более шустрый доступ к системной памяти для видеокарты с той целью, чтобы не ставить на видеокарты (дешевые) кучу памяти, а обойтись необходимым минимумом под framebuffer, а все текстурки и прочее держать в системной памяти.
А с цитатой из статьи можно спокойно поспорить. PCI была и на 66Mhz, и была в варианте 64Bit(и это было в эпоху Pentium-III). Ну а на исходе была PCI-X с 64 битами и 133Мгц (Уже ближе к концу эпохи Pentium-4)
nerudo
21.07.2017 17:41+1Про минус это не ко мне. А по сути «была — не была» — это демагогия. Факт в том, что взяли транспортный уровень PCI. Выкинули физический. То, что выкинулось вместе с физическим — сэмулировали, чтобы сохранить совместимость с PCI. По крайней мере PCIe заметно ближе к PCI, чем все прочие современные протоколы типа Serial RapidIO, Infiniband или еще чего.

Mairon
19.07.2017 17:44+5Не очень понятно, а на чем автор собирается работать на десктопе? ARM, прямо скажем, оказался в идейной депрессии — рынок планшетов накрылся, на телефонах такой круг задач, что стало абсолютно неважно, какой у тебя процессор, году так в 2015, а ARM на десктопы так и не влез. Реинкарнация Windows RT — очередные вялые попытки Майкрософт вдохнуть жизнь в Windows Mobile, не говоря уж о том, что у Qualcomm, которая является ключевым партнёром по WoA, известно какое отношение к обновлениям, и покупать десктоп на снапдрагоне, который через полтора года будет снят с поддержки, никто не будет. Это ещё оставляю за скобками вопрос легальности трансляции x86-32 в AArch, а также отношение Майкрософт к своим экспериментам.
Так что если выбирать между Intel и Qualcomm, то выбор очевидно не в пользу вторых.
Areso
19.07.2017 21:08+1На ARM делают миллионы хромбуков, и миллионы же SBC (по крайней мере — малин миллионы, тираж остальных SBC сильно меньше).
Mairon
19.07.2017 23:03+3Все эти миллионы хромбуков занимают <5% рыночной доли настольных систем даже на рынках ключевого распространения при невероятном субсидировании со стороны Гугла, который пихает их с доплатой каждой американской госконторе. Про малины вообще не говорю, ими вообще никто не пользуется на консюмерском рынке.

romxx
20.07.2017 00:52-4Вы в каком-то своем мире живете, даже неловко вам что-то возражать, нарушать такой красиво выстроенный мир :)

x67
20.07.2017 14:01Я живу в своем мире и тут я уже года два не видел живого хромбука. Скажите, как построить портал в ваш мир?
jetexe
20.07.2017 16:30Периодически встречаю материнки со впаяным ARM: ток не жрет, охлаждать (почти) не надо, кино/музыку крутит, страички в браузерах рисует. В итоге отличные «печатные машинки» получаются
Areso
20.07.2017 17:38+1Хз, хз, у меня малинка 3 в цикле крутит простой скрипт (подключиться к БД, выполнить селект, отдать результат на I2C), нагревается ооочень ощутимо этим скриптом, палец на терпит прикосновения к поверхности чипа.
В браузере работает медленно (js регулярно вешает малинку намертво), видео тоже не всякое воспроизводит. Сопоставима с одноядерным удушенным Intel Atom на нетбуке 2008 года выпуска, который у меня когда-то был и от которого я избавился в 2014 по причине его устаревания.
beeruser
20.07.2017 14:46+1>> рынок планшетов накрылся
«Накрылся» в смысле не растёт?
Так и рынок PC уже несколько лет падает.
>> Реинкарнация Windows RT — очередные вялые попытки Майкрософт вдохнуть жизнь в Windows Mobile
О чём речь? Эта полноценная 10-ка не связанная с WM.
Наконец-то появится вменяемое железо, а не хромбуки с убогими характеристиками вида «2-гига, 2-ядра».
>> известно какое отношение к обновлениям, и покупать десктоп на снапдрагоне, который через полтора года будет снят с поддержки, никто не будет.
Разумеется будет — я куплю =)
У QCOMM нормальное отношение к обновлениям, просто они это делают не бесплатно.
Производители не хотят платить.
Почитайте тред
https://twitter.com/jhamby/status/886823340484083712
Mairon
21.07.2017 18:00«Накрылся» в смысле не растёт?
Так и рынок PC уже несколько лет падает.
Накрылся в смысле «падает». И во многом он ещё только падает, а не проваливается в бездну, как раз из-за Intel-планшетов. АРМы-то проваливаются, и из всех планшетов худо-бедно растут только виндопланшеты.
А рынок традиционных ПК скорее стагнирует, у IDC по свежим данным как раз именно так.
О чём речь? Эта полноценная 10-ка не связанная с WM.
В каком месте она «полноценная» без x86-64? На момент анонса обещали только x86-32, может что-то изменилось?
У QCOMM нормальное отношение к обновлениям, просто они это делают не бесплатно.
Производители не хотят платить.
Почитайте тред
Удобная позиция. Мы, конечно, за обновления, но отгрузите нам 100500 нефти, чтобы мы вам это обновление сделали. На русский язык это переводится как «у квалкома отвратное отношение к обновлениям». Это верно как для Nexus, так и для Windows, включая, но не ограничиваясь, Mobile.
Не говоря уж о том, что даже если SoC поддерживаются, поставщики телефонов получают код от Квалкома только через несколько месяцев после релиза нового Android в AOSP. А до этого они могут только провью клепать как Сони, не более того.

dendron
20.07.2017 00:29Немного в сторону… Мне грустно от того что nVidia и прочие забыли про игры и бросились в нейросети для Большого Брата. Игры хотя бы были безобидные для человечества. Сейчас уже шагу нельзя ступить, как твоя личность уже идентифицирована и оцифрована, поведение предугадано, социальные связи установлены, индекс лояльности посчитан, алгоритм манипуляции определён. Такой вот ИИ. Вряд ли фантасты о таком мечтали.
ivanius
25.07.2017 21:05Мне кажется это не совсем так, правильно писали тут про майнинг, про нейросети и ИИ меньше, НО производители игр для того и сотрудничают с AMD или nVidia чтобы их игры были более оптимизированы и работали хорошо, при этом используют новые технологии.
И к стати не увидел в коментах ни слова об VR, который тоже сейчас развивается на ряду со всем этим и ему тоже нужна производительность видео т.к. 2 рендера под каждый глаз в 2к и выше немало ресурсов кушает, не говорю уже о vsync 60fps и выше.


vikarti
20.07.2017 02:48+1Даже сегодня самый мощный CPU от Intel справляется только с 24 ядрами
Строго говоря это не совсем корректно. У Xeon Phi ядер от 64 (а потоков от 256).
Производит их Intel и даже штатную версию Windows на них — запускали (пусть нужна спецматеринка) — смотрим например https://www.servethehome.com/intel-xeon-phi-x200-knights-landing-boots-windows/
Цены правда негуманные. Ну так на топовые Xeon'ы они тоже не особо гуманные.
JerleShannara
21.07.2017 01:36+1Впринципе можно пойти другим путём (который интел и купили ради фая) — потратить 10к$ на FPGA ускоритель и лицензии на софт.
msts2017
20.07.2017 10:49Теперь понятно почему апи директ икс изначально был каким-то, неожиданно, кривоватым (удивлялся в прошлом веке), это специально было сделано.

ChieF_Of_ReD
20.07.2017 20:19-1Т.е. если не спорить с прогнозами и я правильно понял, то получается, что железяка которая сейчас является видеокартой сможет перетянуть на себя все вычислительные операции и функции проводимые процессором при этом люто шагнув в производительности и скорости?
unclechu
21.07.2017 20:12Я хотел создать новый набор драйверов Windows, позволявших проводить массивную конкуренцию на рынке железа, чтобы работа новых медиа, включая аудио, ввод данных, видео, сетевые технологии, и т.п. на создаваемом нами рынке игр для ПК зависела от собственных драйверов Windows. Intel не справилась бы с конкуренцией на свободном рынке, созданной нами для компаний, производящих потребительское железо, и поэтому не смогла бы создать CPU, способный эффективно виртуализировать всю функциональность, которую могли потребовать пользователи. Так и родился DirectX.
Всё что нужно знать о некрософте в ответ на вопрос: «почему её называют копрорацией зла».
AIxray
25.07.2017 21:05А как же процессорные инструкции SSE,AVX…? И ещё, если бы и вправду было так, то скажем Pentium 4 Prescott до сих пор бы тянул все современные игры, а Gpu NVidia обрабатывала все необходимые вычисления.
Вот стоит обсудить, что где как, а затем можно загадывать.
И не забывайте современный мир таков, что завтра одна технология может переехать/вжиться в другую, так что не удивительно будет, вопрос только в целесообразности.PsyHaSTe
27.07.2017 01:15+3SSE дают ускорение в 2-4 раза, AVX — в 8, а GPGPU — в 100+. Вроде бы есть разница…
AndreyNagih
Однако, Intel уже сегодня встраивает FPGA в свои процессоры, пусть и для особых заказчиков.
SADKO
… ну, просто массы до этого ещё не доросли, сама концепция использования подобных устройств ещё в процессе, средств разработки\оптимизации нет, ну в смысле есть но лишь для решения частных задач, а в будущем легко представить себе не только вычислительные библиотеки на всякую потребу, но возможно и хитрые, интеловские компиляторы, которые и старый код ускорят, как-нибудь :-)
qw1
А что там с количеством перепрограммирований?
Матрица при перепрошивке деградирует ли, как flash-память при перезаписи?
JerleShannara
Ничего, прошивка лежит во внешней памяти и по большому счёту её никогда не перезаписывают, т.к. она представляет собой bootloader. Когда вам надо научить
намайнить биткпомучать нейросеть вы просто даёте команду на загрузку в ПЛИС прошивки нейросети, которая в свою очередь грузится не в ROM, а в RAM (да, я знаю, что обзывать реконфигурируемую матрицу соединений в плис RAMом это не очень, но понятие «кол-во циклов перезаписи» тут имеет тот-же смысл, что и в модуле обычной DDR/кеше вашего процессора)ktod
В FPGA нет flash-памяти. Там ячейки конфигурации на базе статического ОЗУ.
Flash нативно был в CPLD и как костыль в некоторых сериях FPGA, которые пришли на замену CPLD.